Demo Video on Real-time Meeting Recognizer and Browser (267 MB).
Demo Video on Meeting Assistance system on a tablet PC (100 MB).
Demo Video on Multi-modal Communication Scene Analysis (93 MB).
We are sorry that all the conversations in the videos are in Japanese, but we hope you can get an idea of our system. Captions and narrations are in English.
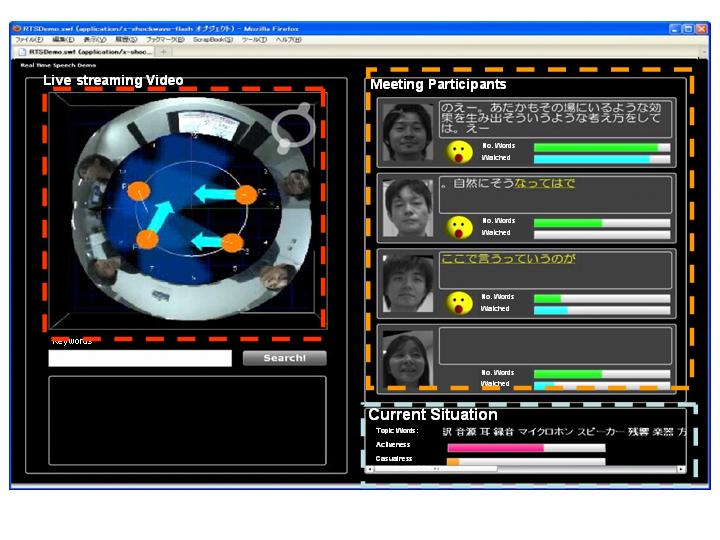
Fig. 2: Prototype of meeting browser (click for more details).
Our system analyzes both
the activity of each participant
(e.g. speaking when and what, laughing, watching to whom),
and the atmosphere of the meeting
(e.g. topic, activeness, casualness)
by integrating audio and visual information.
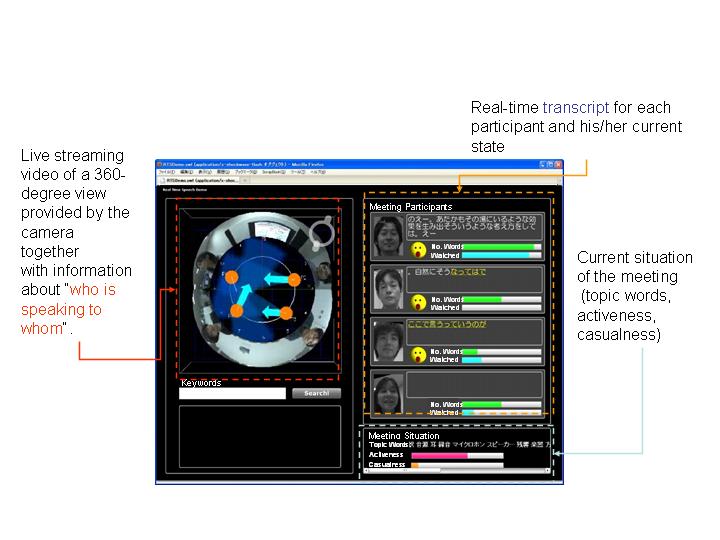
All the analysis results are continuously displayed on a browser (Fig. 2):
Left: Live streaming Video of a 360-degree view provided by the camera, together with analysis result on "who is speaking to whom" and "who is looking at whom".
Upper-right: Status of each participants with real-time transcript, current state (event detection (speaking, laughing, or silent), the number of spoken words, and the visual focus of attention).
Lower-right: Meeting atmosphere including the activeness, casualness, and the topic words of the meeting.
Demo Video on Real-time Meeting Recognizer and Browser (267 MB).
Demo Video on Multi-modal Communication Scene Analysis (93 MB).
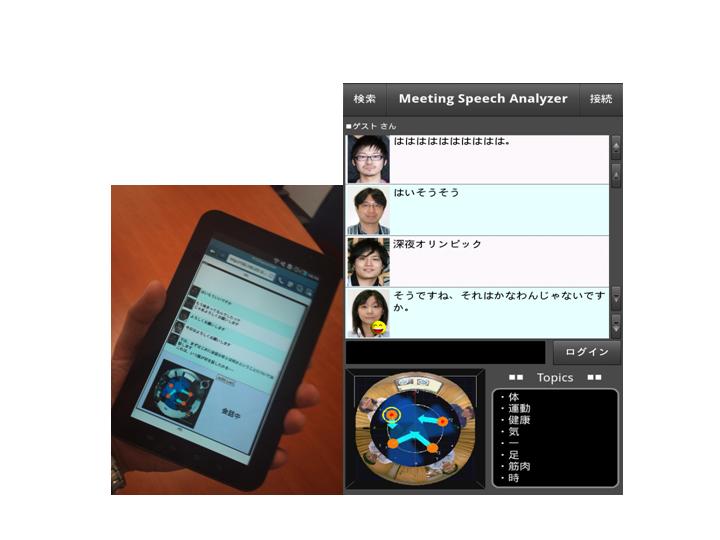
Fig. 3: Meeting assistance with a smart-phone (click for larger image).
We also implemented a meeting assistance system as an application of our real-time meeting recognizer.
The system visualizes the meeting recognition results on tablet PCs and smart-phones (Fig. 3) in an online manner.
We can also easily retrieve and access the recorded meeting information by using this meeting assistance system.
Online-mode usage examples:
Assist and activation of a discussion.
Searching the unknown terms in the discussion with a smart-phone.
High realistic TV conference system by transmitting multi-modal information.
Offline-mode usage examples:
Meeting minutes taking
Archiving meetings
Check and training of the communication skill
Demo Video on Meeting Assistance system on a tablet PC (100 MB) (Tablet PC version will appear after 0:48. Sorry all are in Japanese, but we hope you can get an idea of this system).
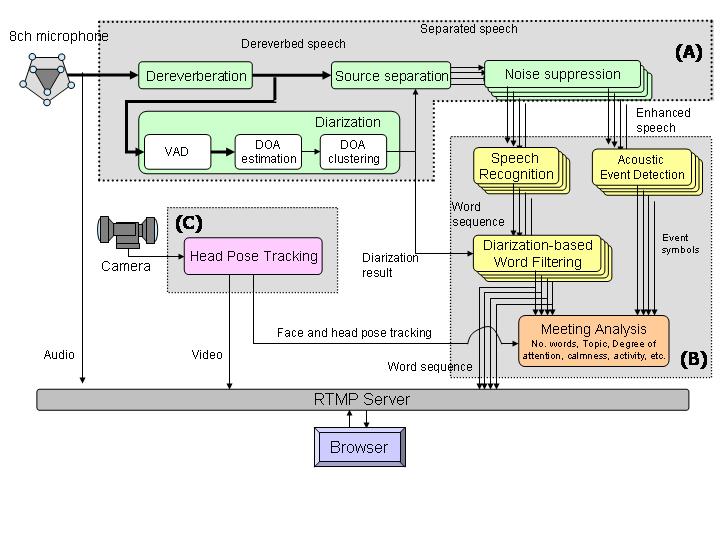
Fig. 4: System architecture (click for larger image)
Figure 4 shows the system architecture. Part (A): Speech enhancement:
In meeting recognition scenarios, we need to remove several types of audio distortion, e.g., additive noises, speech overlaps, and reverberation.
To combat all the types of distortion, we employ four techniques [4]:
Dereverberation based on multi-channel weighted linear prediction [5]
Speaker diarization (= estimation of "who speak when") based on direction-of-arrival [6]
Source separation with beamforming approach [6]
Noise suppression with mel-scaled Wiener filter [7]
Part (B):Speech recognition provides the transcribed utterances for each enhanced signal for each speaker.
We employ the speech recognizer SOLON (Speech recognizer with OutLook On the Next generation) [8] developed at our laboratories, which achieves high-accuracy and fast speech recognition using discriminatively trained acoustic and language models [9][10].
SOLON adopts an efficient WFST-based decoding algorithm [11] with a
fast on-the-fly composition technique that enables to integrate
different language models in low-latency one-pass decoding [12].
SOLON is used both for
Speech recognition
and Acoustic event detection (silence, speech and laughter).
For browsing of ongoing meetings, we apply our proposed techniques
Sentence boundary detection [13]
Topic tracking [14]
to obtain the analysis results with low latency from speech recognition results.
Detailed information can be found in [1,2] and its references.
Part (C):Visual processing:
The face pose tracker [15,16] provides head pose information of each participant, from which we estimate "who is looking at whom" and "visual focus of attention".
Our system also estimates "who is speaking to whom",
by combining the audio and visual information,
[1] T. Hori, S. Araki, T. Yoshioka, M. Fujimoto, S. Watanabe, T. Oba, A. Ogawa, K. Otsuka, D. Mikami, K. Kinoshita, T. Nakatani, A. Nakamura, and J. Yamato, "Low-latency Real-time Meeting Recognition and Understanding Using Distant Microphones and Omni-directional Camera," submitted to IEEE Trans. ASLP, (accepted)
[2] T. Hori, S. Araki, T. Yoshioka, M. Fujimoto, S. Watanabe, T. Oba, A. Ogawa, K. Otsuka, D. Mikami, K. Kinoshita, T. Nakatani, A. Nakamura, J. Yamato, "Real-time Meeting Recognition and Understanding Using Distant Microphones and Omni-directional Camera," in Proc of SLT2010, 2010.
[3] S. Araki, T. Hori, T. Yoshioka, M. Fujimoto, S. Watanabe, T. Oba, A. Ogawa, K. Otsuka, D. Mikami, M. Delcroix, K. Kinoshita, T. Nakatani, A. Nakamura, and J. Yamato, "Demonstration on low-latency meeting recognition and understanding using distant microphones," HSCMA2011, 2011.
Speech Enhancement & Diarization
[4] S. Araki, T. Hori, M. Fujimoto, S. Watanabe, T. Yoshioka, T. Nakatani, "Online meeting recognizer with multichannel speaker diarization", Proc. Asilomar 2010, pp. 1697--1701, 2010.
[5] T. Yoshioka, T. Nakatani, T. Miyoshi, and H. G. Okuno, ÅgBlind separation and dereverberation of speech mixtures by joint
optimization,Åh IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 1, pp. 69.84, 2011.
[6] S. Araki, M. Fujimoto, K. Ishizuka, H. Sawada, and S. Makino, "Speaker indexing and speech enhancement in real meetings / conversations," ICASSP2008, pp.93--96, 2008.
[7] M. Fujimoto, K. Ishizuka, and T. Nakatani, ÅgA study of mutual front-end processing method based on statistical model for noise robust speech recognition,Åh in Proc. Interspeech Åf09, September 2009, pp. 1235--1238.
Speech recognition
[8] T. Hori, ÅgNTT Speech recognizer with Outlook On the Next generation: SOLON,Åh in Proc. NTT Workshop on Communication Scene Analysis, 2004, pp. SP.6. [pdf] [9] E. McDermott, S. Watanabe, and A. Nakamura, "Discriminative training based on an integrated view of MPE and MMI in margin and error space," in Proc. ICASSP, 2010, pp. 4894--4897.
[10] T. Oba, T. Hori, A. Nakamura, and A. Ito, "Round-robin duel
discrimination language models," IEEE Transactions on Audio, Speech, and Language Processing, 2011 (to appear).
[11] T. Hori, C. Hori, Y. Minami, and A. Nakamura, "Efficient WFST-based
one-pass decoding with on-the-fly hypothesis rescoring in extremely
large vocabulary continuous speech recognition," IEEE Transactions on
Audio, Speech, and Language Processing, vol. 15, no. 4, pp. 1352--1365, 2007.
[12] T. Oba, T. Hori, A. Nakamura, and A. Ito,Å@"Round-robin duel
discriminative language models in one-pass decoding with on-the-fly
error correction," in Proc. ICASSP2011, pp. 5588--5591, May 2011.
[13] T. Oba, T. Hori, and A. Nakamura, "Improved sequential dependency analysis integrating labeling-based sentence boundary detection," IEICE Transactions, Information & Systems, vol. E93-D, no. 5, pp. 1272--1281, 2010.
[14] S. Watanabe, T. Iwata, T. Hori, A. Sako, and Y. Ariki, "Topic tracking language model for speech recognition," Computer Speech and Language, Vol. 25, Issue 2, pp. 440--461, April, 2011.
Image processing and Non-verbal communication scene analysis
[15] K. Otsuka, S. Araki, K. Ishizuka, M. Fujimoto, M. Heinrich, J. Yamato, "A Realtime Multimodal System for Analyzing Group Meetings by Combining Face Pose Tracking and Speaker Diarization," ICMI2008, pp. 257--264, 2008.
[16] Conversation Scene Analysis page by Kazuhiro Otsuka --> Link

{kind=link}