All-neural online source separation, counting, and diarization for meeting analysis
A fully neural network based single-channel block-online source separation, counting and diarization system
Thilo von Neumann, Keisuke Kinoshita, Marc Delcroix, Shoko Araki, Tomohiro Nakatani, Reinhold Haeb-Umbach
[Link to our paper]
Automatic analysis of meetings promises to relieve humans from tedious transcriptions work. It comprises counting the number of meeting attendees (source counting), detecting which participant is active when (diarization), separating speech in regions where multiple participants talk at the same time ((blind) source separation), and transcribing the said words for the separated audio streams (speech recognition) for recordings in the length of up to multiple hours. All of these are challenging tasks by themselves, and become even more demanding considering that recordings of meetings can be arbitrary long, making batch processing practically unfeasible and asking for block-online processing.
Our recently proposed single-channel source separation and counting system "Recurrent Selective Attention Network" (RSAN), also called "Selective Hearning Network" (SHR) [Kinoshita et al., ICASSP 2018], can efficiently separate and count multiple talkers in clean recordings by treating the source separation problem as an iterative source extraction. It is predicated to a recurrent neural network (RNN) and uses the same neural network multiple times to iteratively extract one source after another while maintaining information about which parts of the spectrogram have not yet been extracted as part speech signal. We achieved state-of-the-art performance comparable to Permutation Invariant Training, Deep Clustering and Deep Attractor Network.
In our newly proposed method, the input spectrogram is split into time blocks of equal length, and the same neural network is now applied not only for each detected source, but also for each block, now being recurrent in two directions over time and the number of sources. It is trained to output an embedding vector alongside the separation mask for each speaker that represents the identity of the extracted speaker. These embedding vectors are passed to the next time block as a source adaptation input, and the model is trained to extract the source that is represented by the input vector. If speakers for which an adaptation embedding input exists are silent throughout a whole time block, a mask filled with zeros is output, but the source embedding vector is passed to the next time block. This causes the system to always output the same source in the same iteration, thus eliminating the permutation problem. The problem of source counting is stripped down to a simple threshold processing on the estimated masks. Unlike any prior works, our approach can in theory handle arbitrary long recordings with an arbitrary amount of talkers. It can track identities even if a talker remains silent over a significant amount of time and maintains a stable output order for all present speakers.
This work will be presented at ICASSP-2019. A preprint of the paper is available here.
Audio Samples
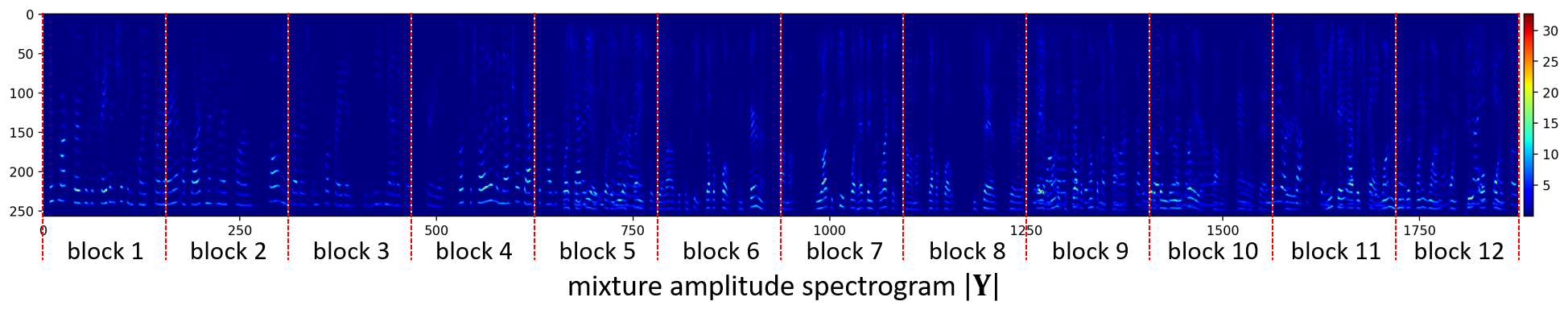
Male-Female Mixture (30s)
Original
Separated speaker 1
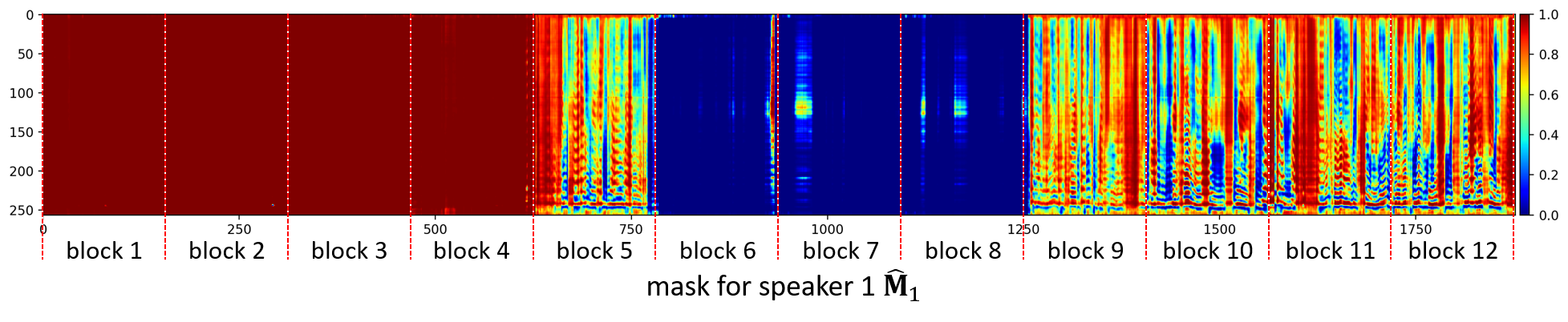
The speaker information is not lost in the three blocks (7.5 seconds) where the first (female) speaker is silent. The second (male) speaker is suppressed in the overlapping parts. Some artifacts are visible in the mask for the silent time blocks.
Separated speaker 2
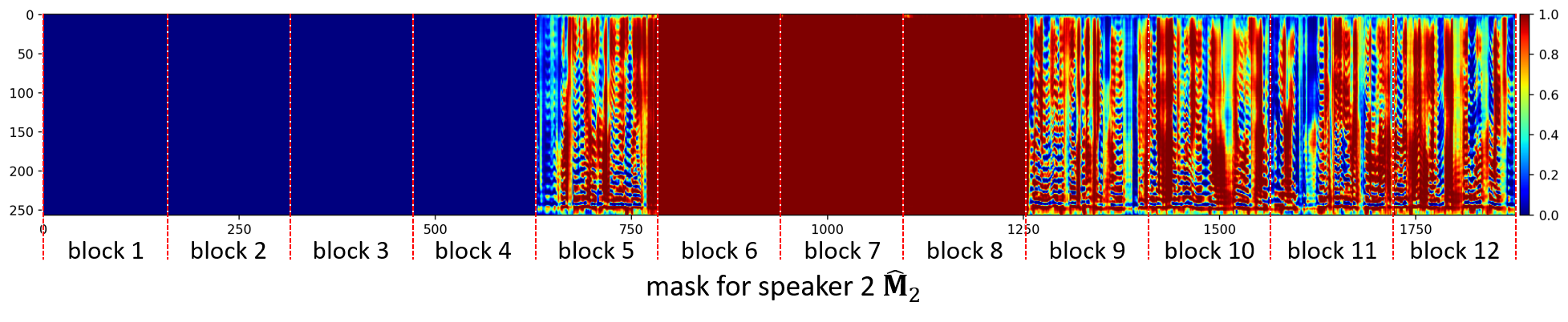
The system does a single iteration for the first 4 time blocks and only outputs one mask for the first active speaker. It then correctly detects the second speaker when it starts speaking in the fifth block and achieves a reasonable separation performance for that speaker throughout the rest of the signal.