This is a demonstration page for the following paper at ICASSP2020.
Keisuke Kinoshita, Marc Delcroix, Shoko Araki, Tomohiro Nakatani,
``Tackling real noisy reverberant meetings
with all-neural
source separation, counting, and diarization system'',
ICASSP-2020,
Automatic meeting/conversation analysis is an essential fundamental technology required to let, e.g. smart devices follow and respond to our conversations. To achieve an optimal automatic meeting analysis, we previously propose an all-neural approach called "online RSAN (Reccurent selective attention network)" that jointly solves source separation, speaker diarization and source counting problems in an optimal way (in a sense that all the 3 tasks can be jointly optimized through back-propagation) [1]. In the above paper, we experimentally show that, even in real meeting scenarios, the proposed all-neural approach can perform effective speech separation and enhancement, and outperform state-of-the-art systems in terms of diarization error rate.
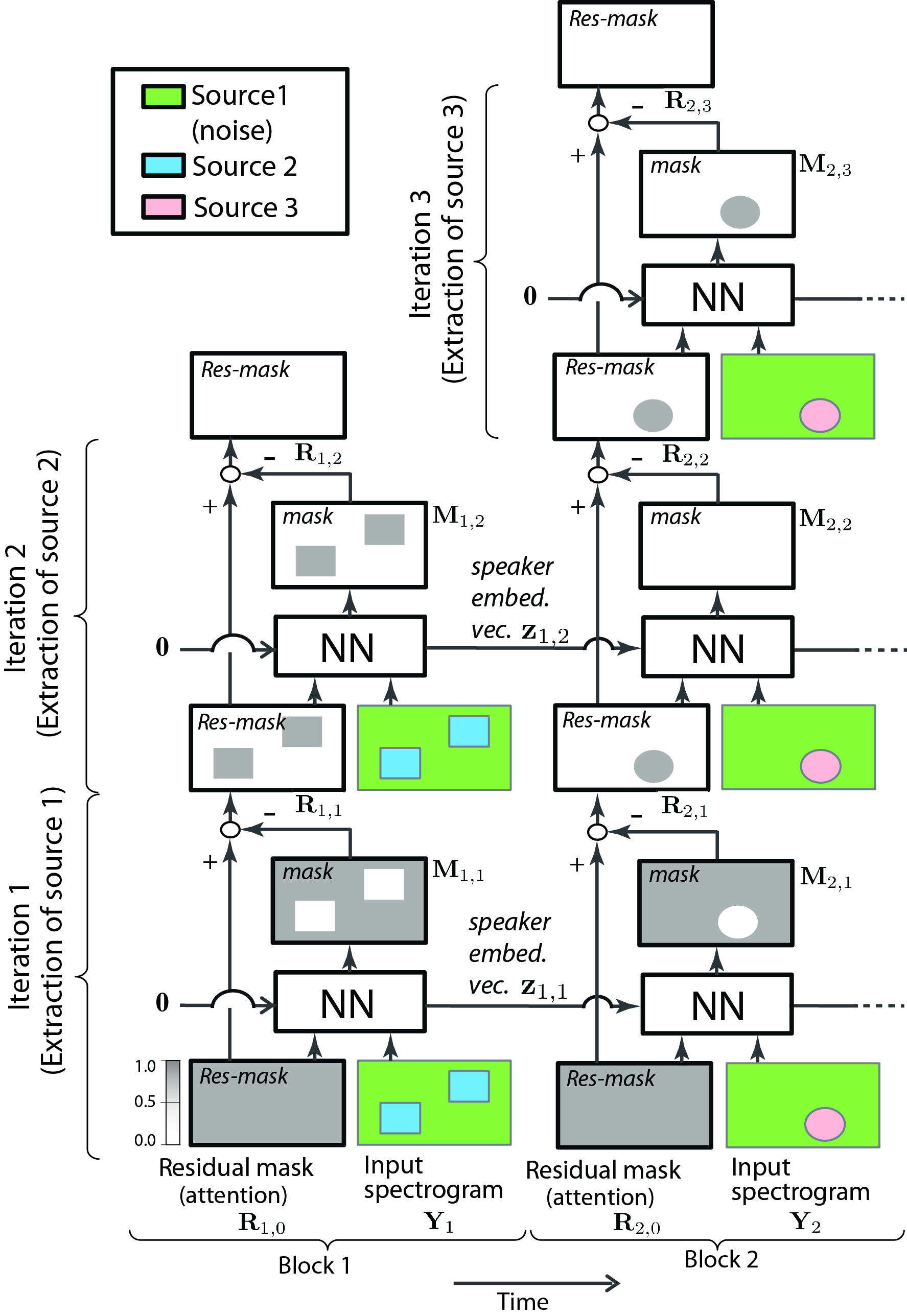
As in the following figure, the proposed method works in an block online fashion. At each block, it recursively extracts a speaker from the input mixture until there is no more speaker left in the block, and simultaneously estimates a speaker embedding vector for each speaker. Then, in the subsequent blocks, it recieves the speaker embedding vectors extracted in previous blocks, and perform speaker extraction corresponding to the speaker embedding vectors. If there is a new speaker that has not been observed in the previous blocks, the system automatically increase the number of source extraction iteration, and separate and start tracking that speaker too. By doing so, it performs jointly source separation, source counting and speaker tracking (i.e. diarization-like process).
Here are a set of audio samples for you:
- Observed mixture containing 3 people (3-minute excerpt taken out from a 20-minute-long real spontaneous meeting)
- Headset recordings of each person
- Signals separated by our method "online RSAN" (Each speaker's voice and background noise)
- Signals separated by our method "online RSAN"+ postprocessing with CGMM-based masking,
where RSAN masks were used as priors for CGMM clustering [2] (Each speaker's voice and background noise)
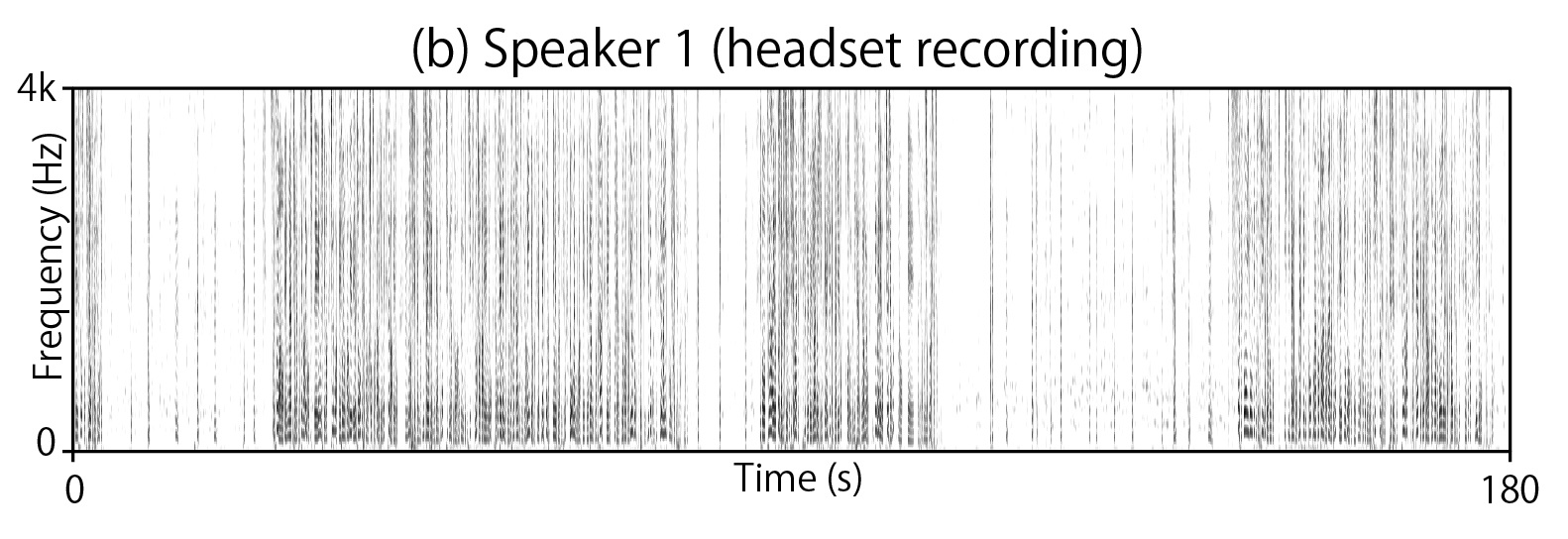
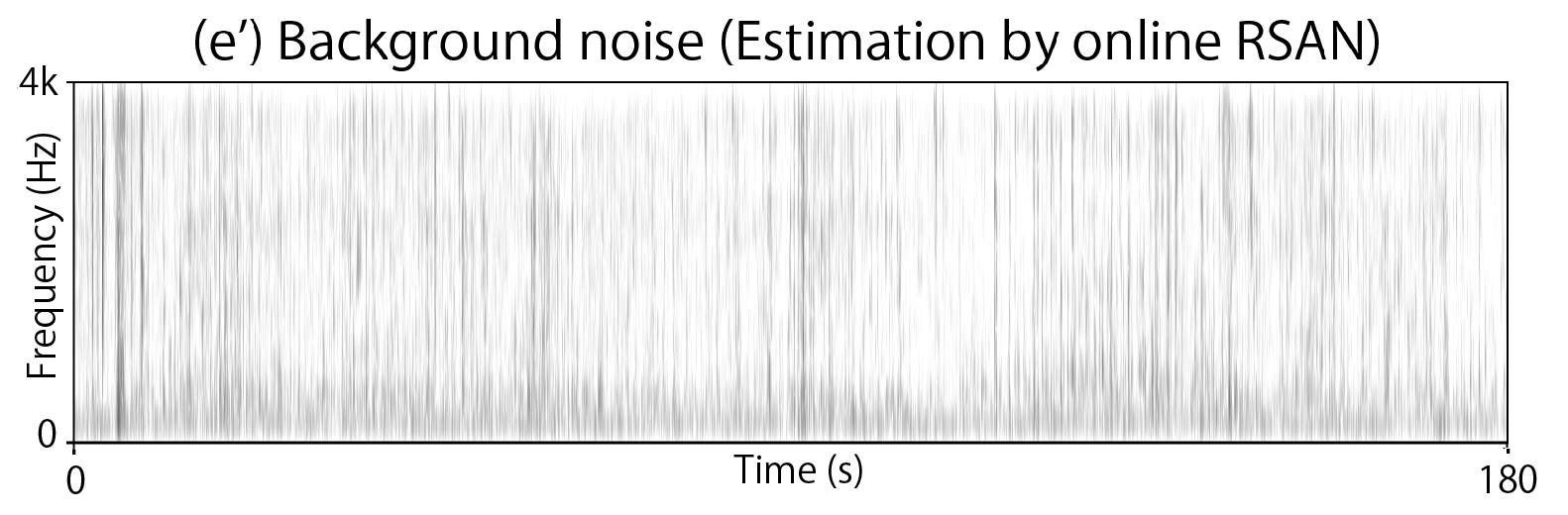
Spectrogram (a) corresponds to observed signal, (b)(c)(d) to headset recordings of each speaker,
and (b')(c')(d')(e') to signals estimated by online RSAN + postprocessing with CGMM-based masking. Enjoy!
 |
||||
 |
 |
(↓ online RSAN)(↓ online RSAN+CGMM) | ||
 |
 |
(↓ online RSAN)(↓ online RSAN+CGMM) | ||
 |
 |
(↓ online RSAN)(↓ online RSAN+CGMM) | ||
 |
(↓ online RSAN)(↓ online RSAN+CGMM) | |||
References
[1]. Thilo von Neumann, Keisuke Kinoshita, Marc Delcroix, Shoko Araki, Tomohiro Nakatani, Reinhold Haeb-Umbach. "All-neural online source separation, counting, and diarization for meeting analysis." ICASSP, 2019 [Link to the paper]
[2]. Tomohiro Nakatani, Nobutaka Ito, Takuya Higuchi, Shoko Araki, Keisuke Kinoshita. "Integrating DNN-based and spatial clustering-based mask estimation for robust MVDR beamforming." ICASSP, 2017 [Link to the paper]