We propose novel approaches to fuse audio and visual target speaker clues for audio-visual target speaker extraction.
Here are a set of samples of extracted audio from real recorded mixtures with conventional and proposed methods.
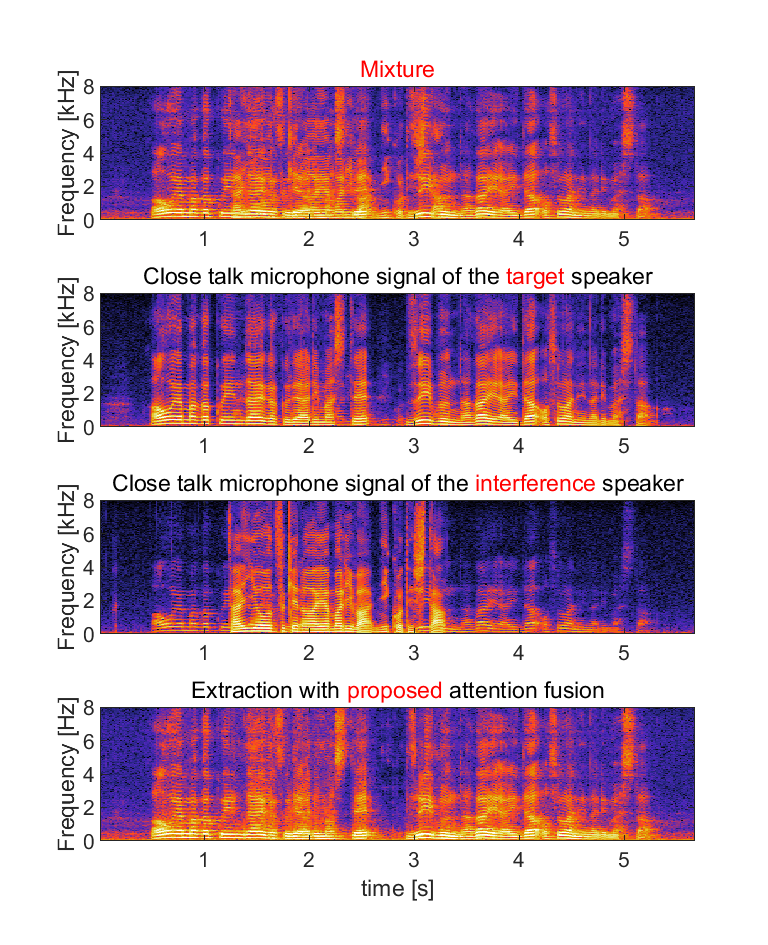
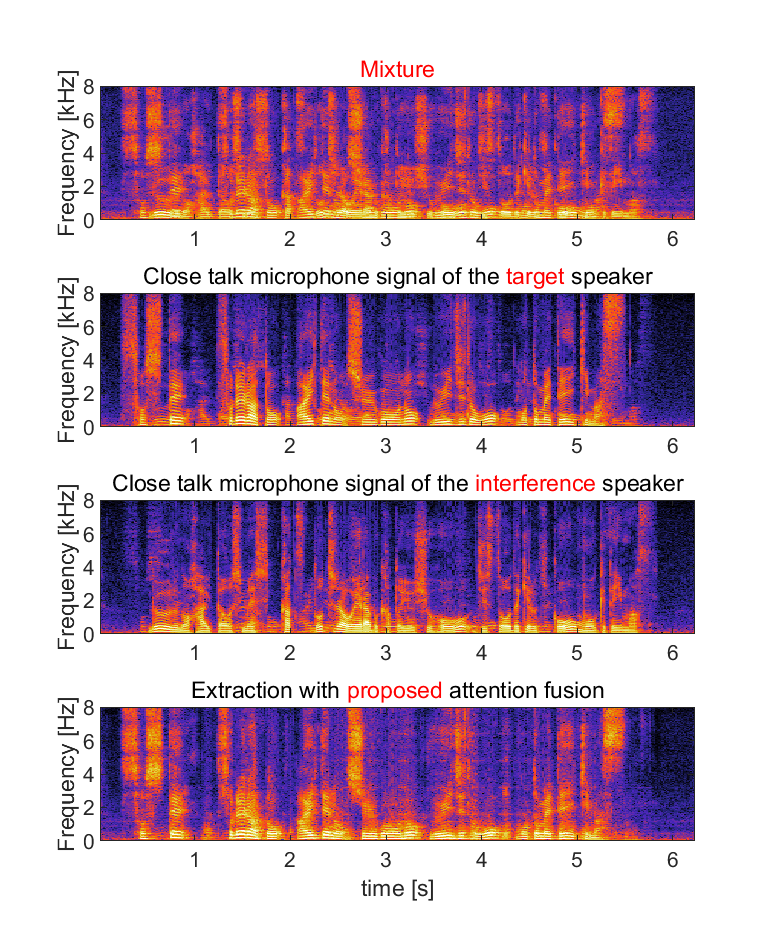
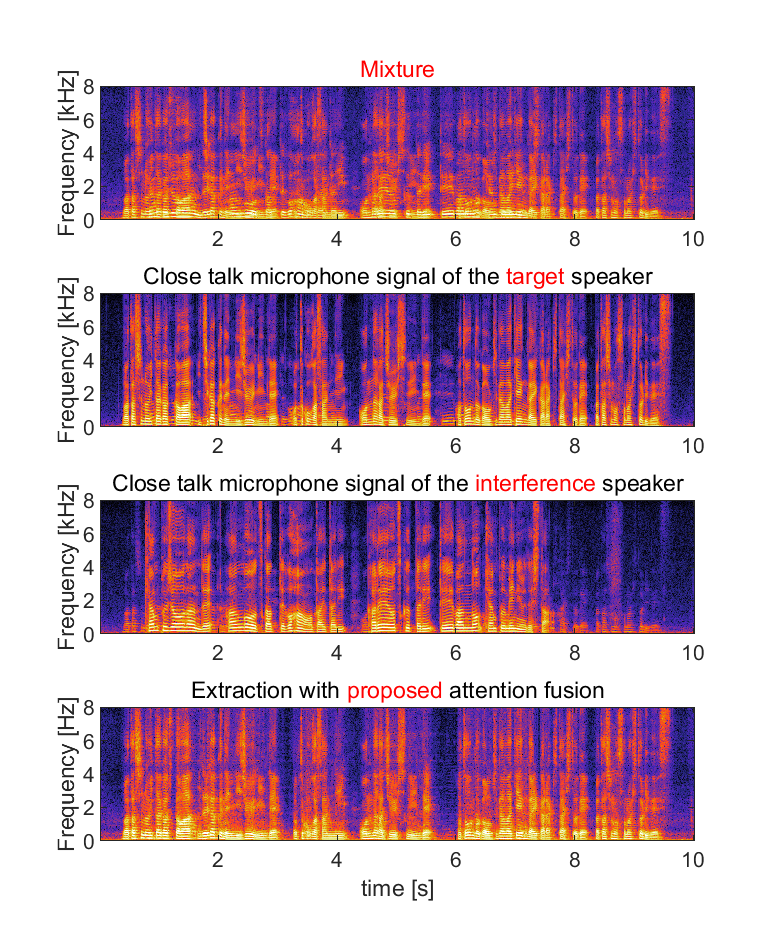
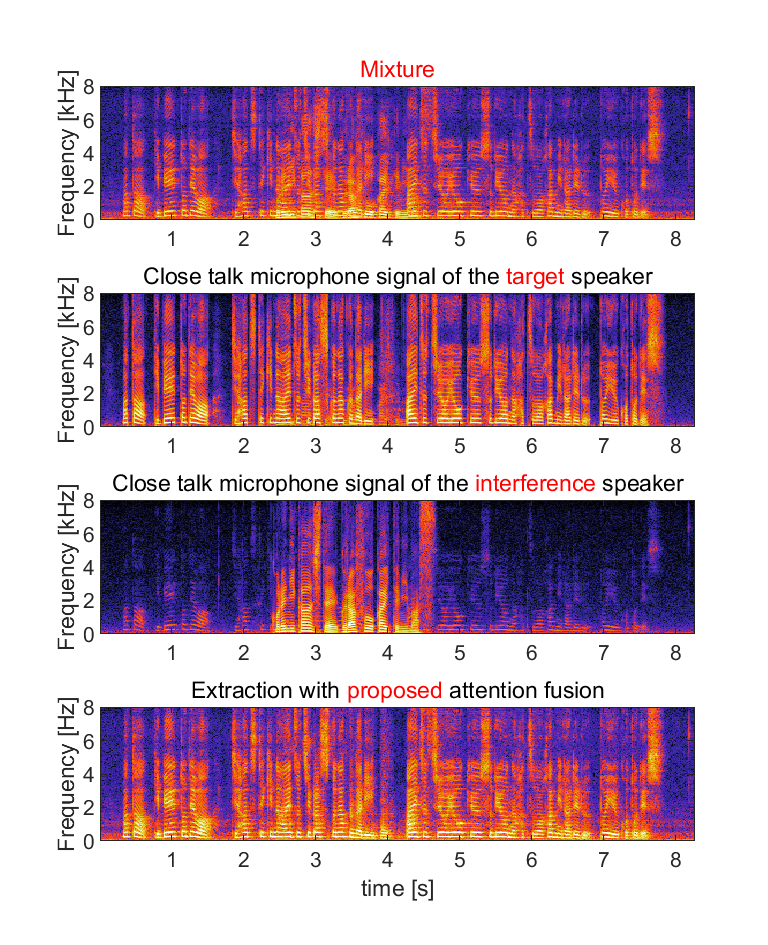
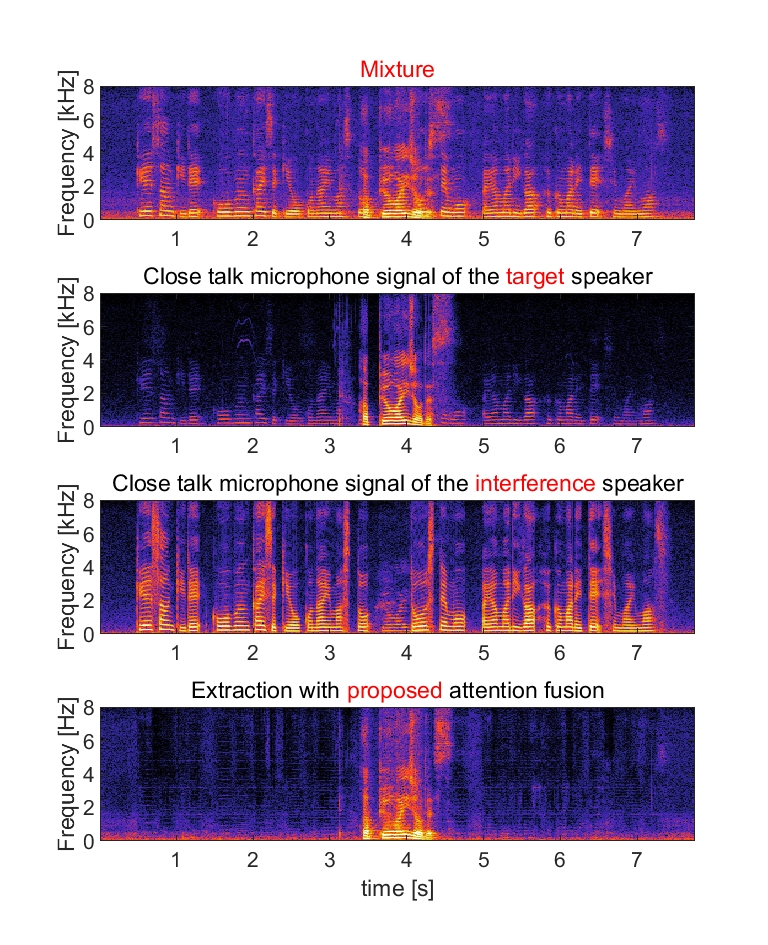
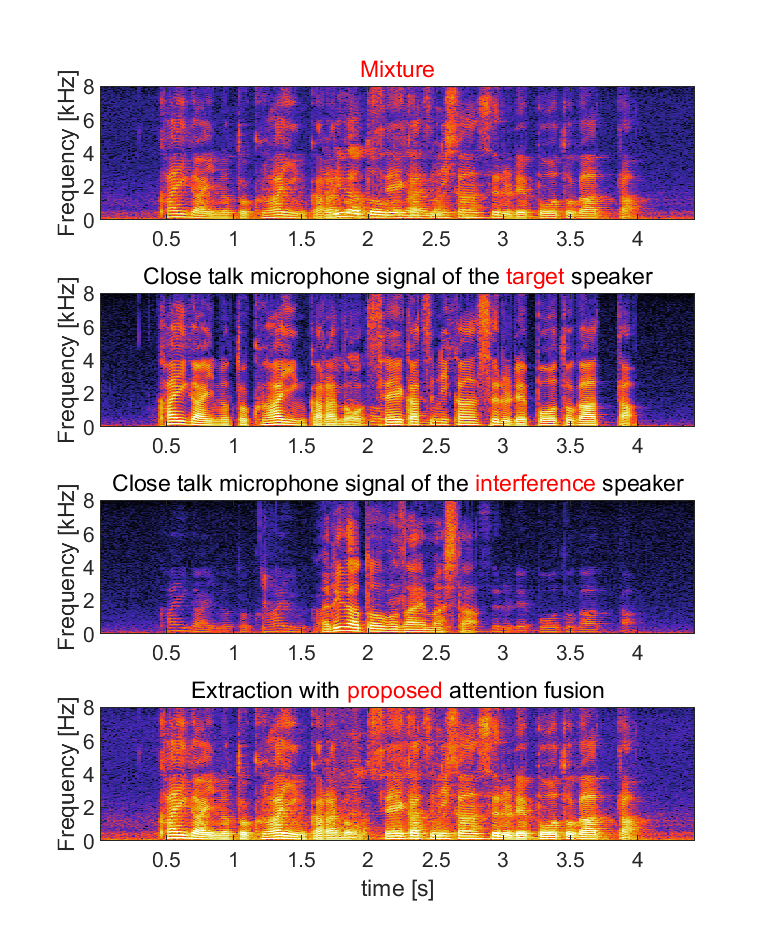
(a) Input for the audio-visual target speaker extraction system consists of mixed speech, audio clue (enrollment speech) and visual clue (video capturing the face of the target speaker).
(b) We show close talk microphone signals of the target and interference speaker as references, but they are not true target signals since it is unavailable in real recordings. The references contain some leakage of the interference speaker.
(c) We show extracted audio with four methods: (i) the extraction with only audio-clue, (ii) the extraction with only visual-clue, (iii) the extraction with conventional attention fusion and (iv) the extraction with proposed attention fusion (normalized attention model with attention guided training). Domain adaptation was conducted for each of them.