Here are a set of audio samples for the proposed universal sound selector/remover:
- Observed mixture containing 7 audio event (AE) classes (i.e., knock, telephone, keyboard, meow, applause, cough, laughter)
- Reference signal (2-class and 4-class selection/removal)
- Estimated signal (2-class and 4-class selection/removal)
- Both selection-target AE classes and removal-target AE classes are set to "knock, telephone" for 2-class (I=2)
and "knock, telephone, keyboard, meow" for 4-class (I=4) cases, respectively
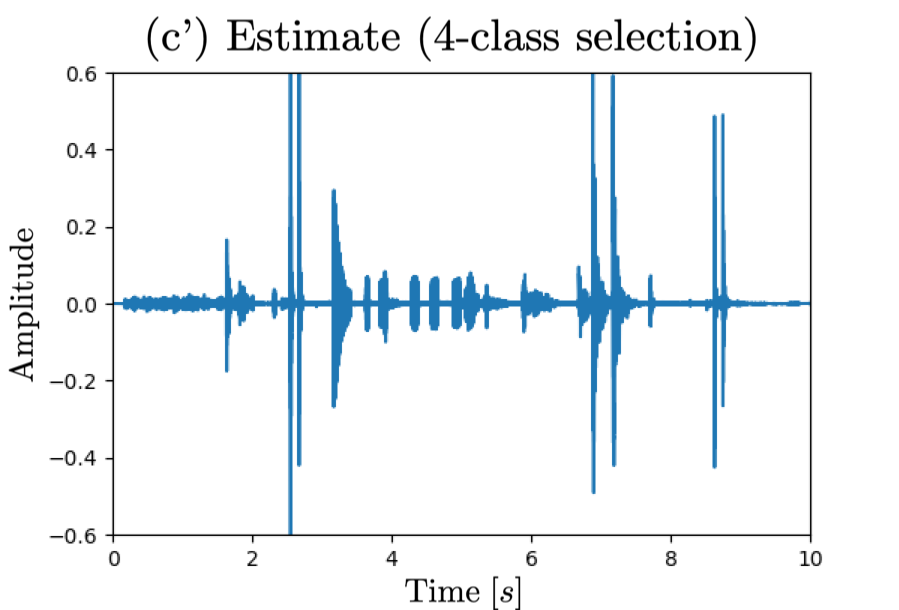
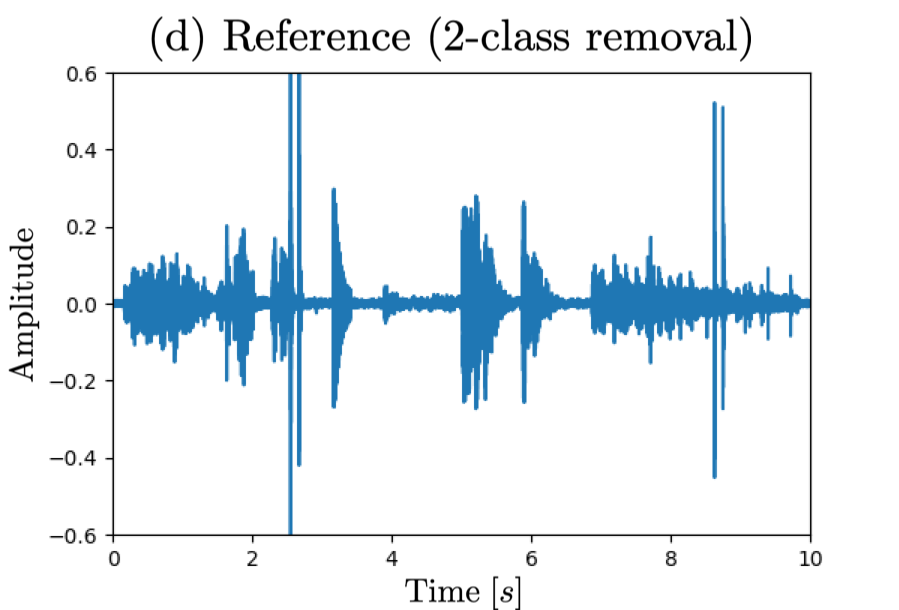
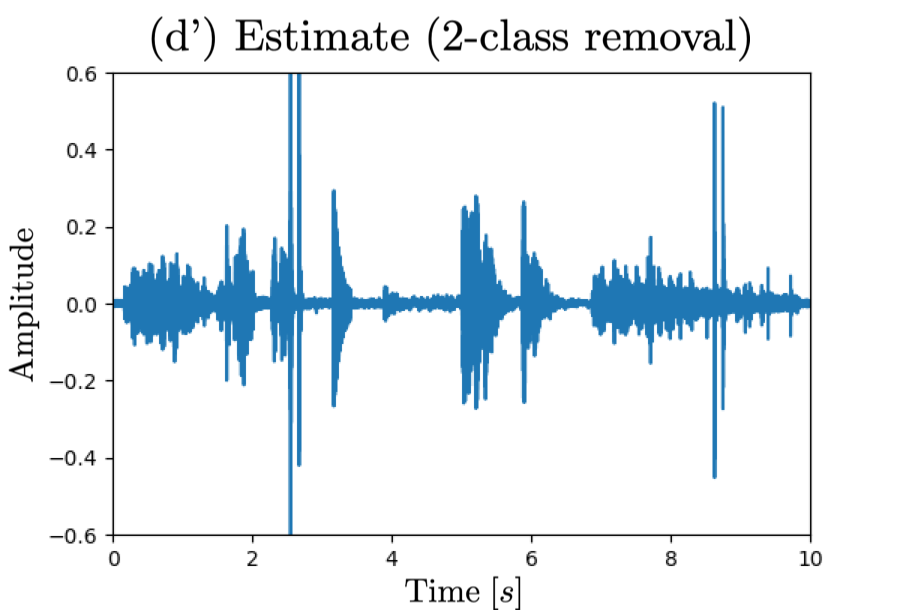
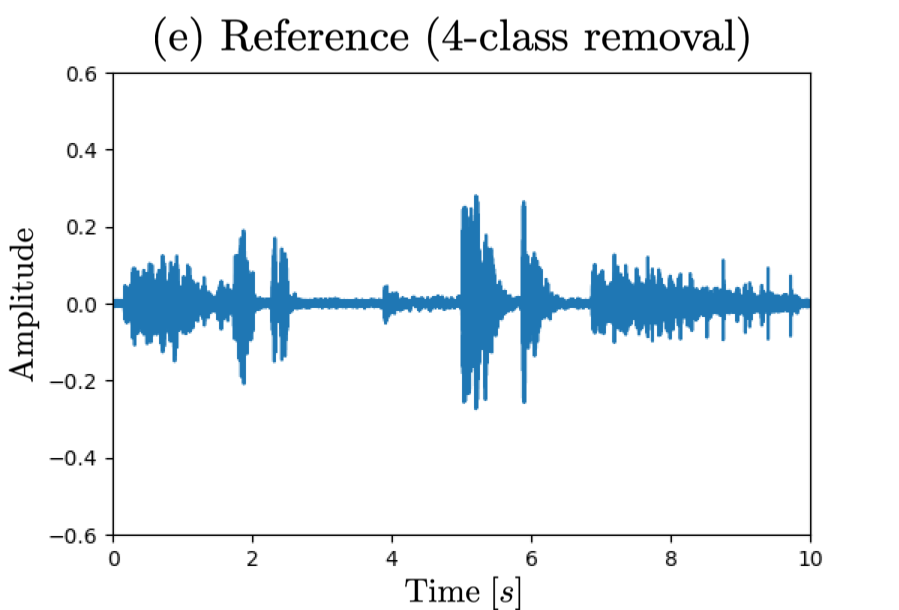
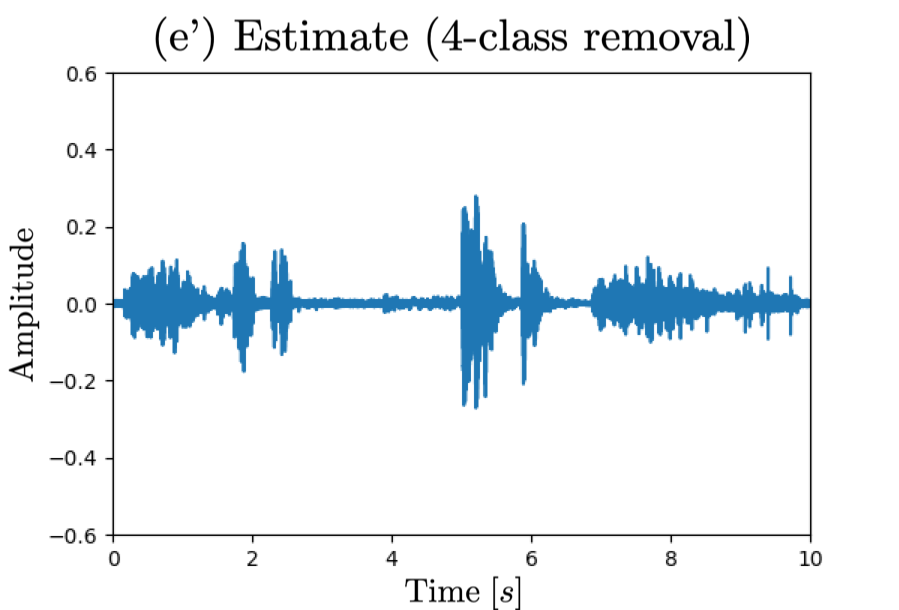
Waveform (a) corresponds to observed signal, (b)(c) reference signal for sound selection task, (d)(e) reference signal for sound removal task,
(b')(c') estimated signal by unversal sound selector and (d')(e') estimated signal by universal sound remover.
□ Sound Selection
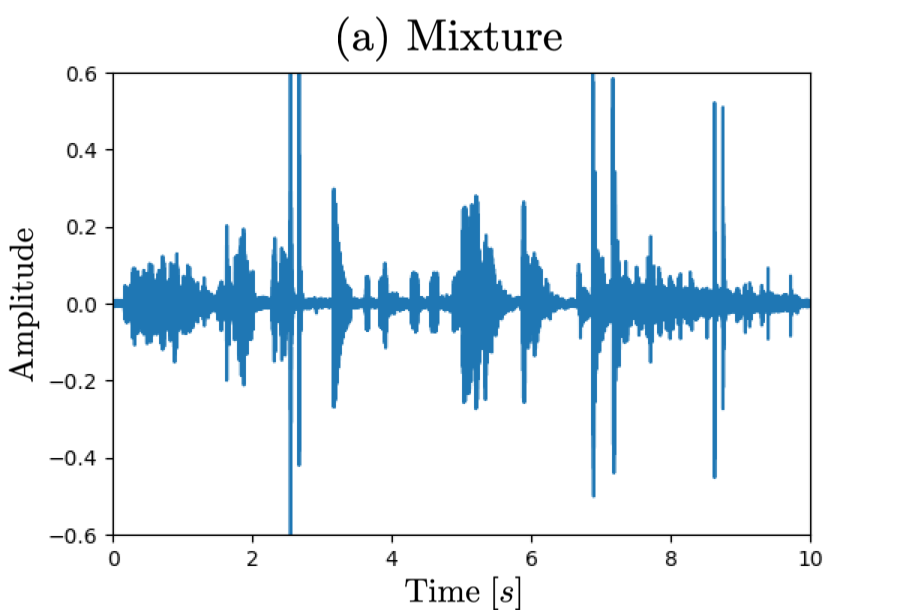 |
□ 2-class case: selecting "knock, telephone"
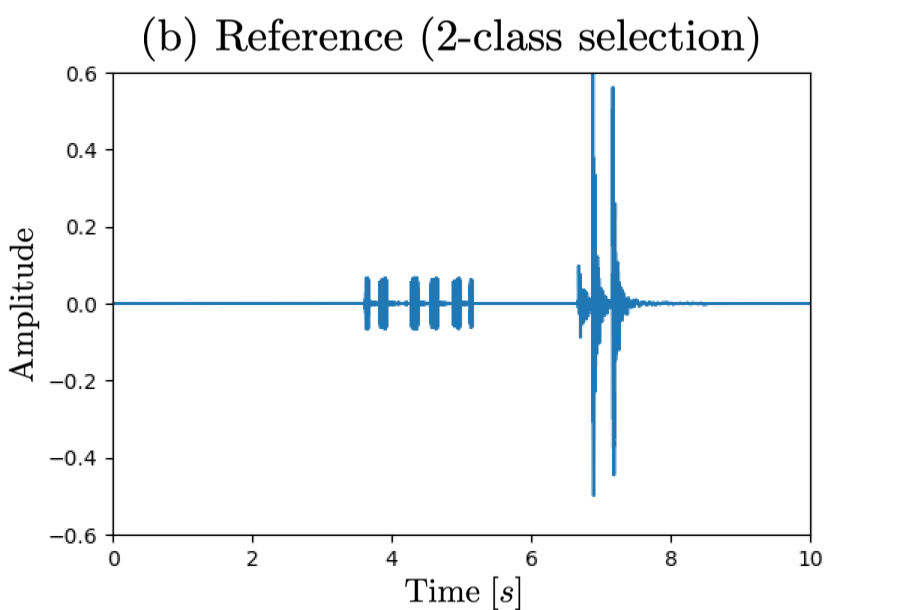 |
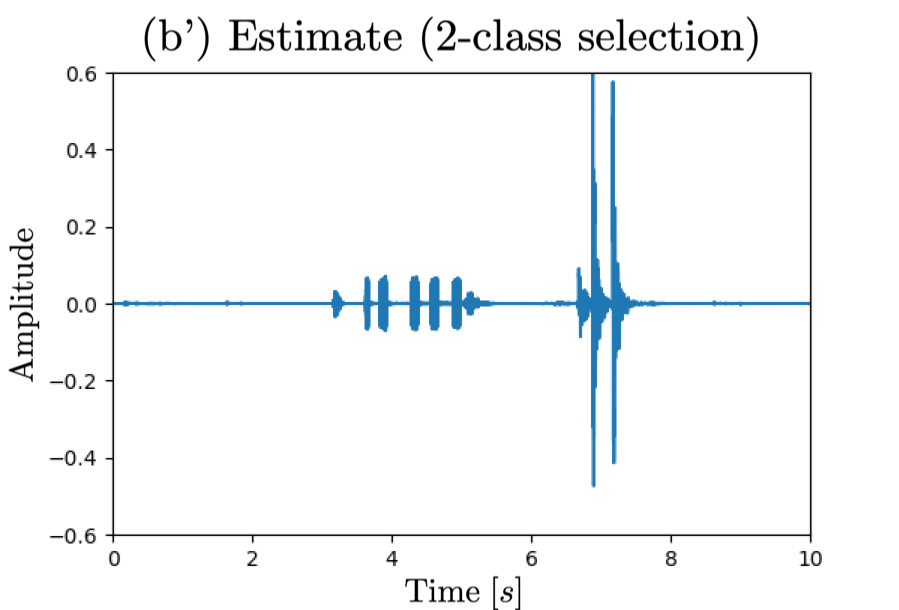 |
□ 4-class case: selecting "knock, telephone, keyboard, meow"
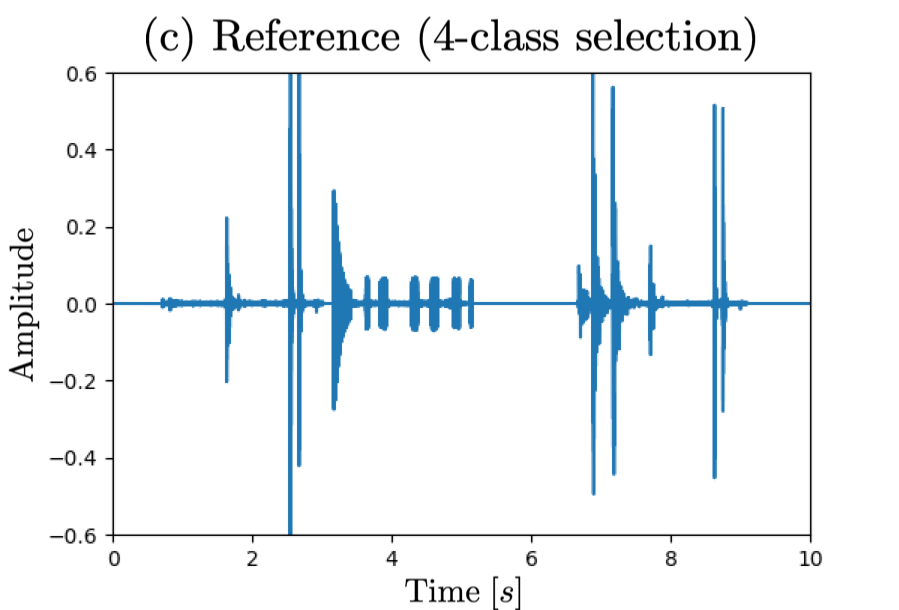 |
 |
□ Sound Removal
|
□ 2-class case: removing "knock, telephone"
 |
 |
□ 4-class case: removing "knock, telephone, keyboard, meow"
 |
 |