Demonstration of blind dereverberation of single channel speech

 Demonstration sounds for ICASSP-2003
Demonstration sounds for ICASSP-2003
- Reference:
Nakatani, T., and Miyoshi, M, ``Blind dereverberation of single channel
speech signal based on harmonic structure,'' submitted to ICASSP-2003.
- Task: dereverberation of male/female word utterances
- Training data: 5240 Japanese word utterances included in ATR database convolved with impulse responses. The reverberation times (rtime) are 0.1, 0.2, 0.5, 1.0 second, respectively.
- Presentataion document [PDF]
- Female speech
| Rtime (second) |
Original sound |
Reverberant sound |
Dereverberated sound |
| 0.1 |
 |
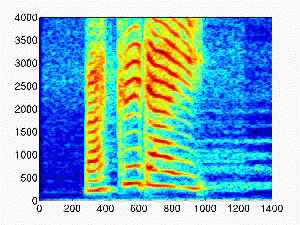 |
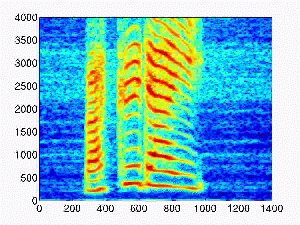 |
| 0.2 |
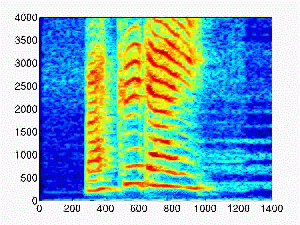 |
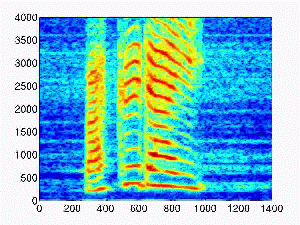 |
| 0.5 |
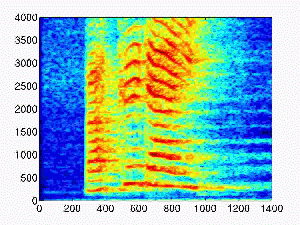 |
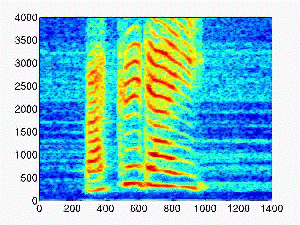 |
| 1.0 |
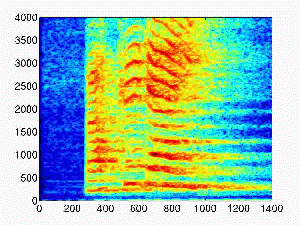 |
 |
- Male speech
| Rtime (second) |
Source sound |
Reverberant sound |
Dereverberated sound |
| 0.1 |
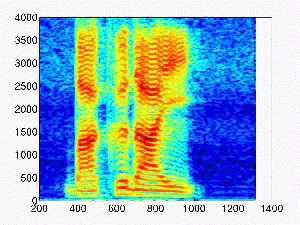 |
 |
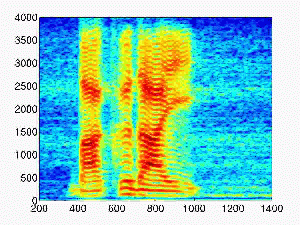 |
| 0.2 |
 |
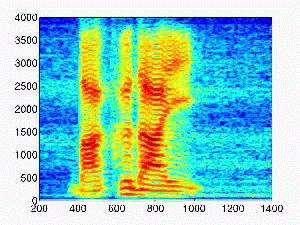 |
| 0.5 |
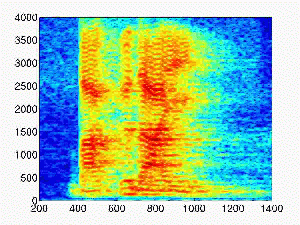 |
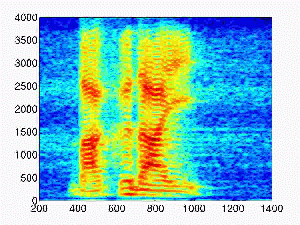 |
| 1.0 |
 |
 |
(back to Tomohiro's homepage)