

メディアとコミュニケーション
誰がどのように話しても正確に聞き取ります
~話者や発話スタイルの多様性に頑健な音声認識技術~

概要
現在,音声認識技術は丁寧な話し方で正しい文を話せば高精度で認識が可能ですが,会話等に見られる多様な話し方に対しては精度が悪化してしまうことが知られています.本展示ではこうした多様性を吸収する技術について紹介します.本技術を用いることにより,多様性に富み最も認識困難とされる「音声認識されることを意識しない発話」,例えば講義や会話における発話の高精度な認識が可能となります.将来的には高精度音声データマイニングや,人の生活を自然に支援できる対話エージェントといったシステムの技術に発展します.研究を通して,こうした高度な情報システムを,機械の存在を意識させることなく,自然に活用できる社会を目指します.
ポスター
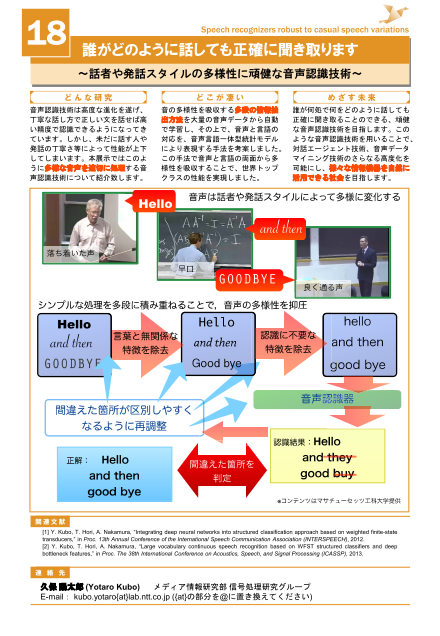
ポスターの画像をクリックすると,PDFファイルが開きます.
資料一覧
- Y. Kubo, T. Hori, A. Nakamura, “Integrating deep neural networks into structured classification approach based on weighted finite-state transducers,” in Proc. INTERSPEECH, 2012.
- Y. Kubo, T. Hori, A. Nakamura, “Large vocabulary continuous speech recognition based on WFST structured classifiers and deep bottleneck features," in Proc. ICASSP, 2013.
展示担当者

久保 陽太郎
メディア情報研究部
メディア情報研究部

小川 厚徳
メディア情報研究部
メディア情報研究部

Marc Delcroix
メディア情報研究部
メディア情報研究部

中村 篤
メディア情報研究部
メディア情報研究部

藤本 雅清
メディア情報研究部
メディア情報研究部

堀 貴明
メディア情報研究部
メディア情報研究部