CAUSEとは?
音声には発話内容に相当する言語情報だけでなく、感情表現やムードに相当する非言語情報が含まれ、音声対話において重要な役割を担っています。 我々は、この非言語情報は話者の顔表情に強く表出されているはずと考え、音声のみから話者のアクションユニット[1](顔面筋パラメータ)を推定する問題に取り組みました。 これを可能にするのがCrossmodal Action Unit Sequence Estimation/Estimator (CAUSE)[2]で、音声のメルスペクトログラムからアクションユニット強度系列を予測するニューラルネットワークモデルとなっています。 例えばCAUSEにより音声から推定したアクションユニット強度系列を所与の顔画像に反映すれば、画像中の顔の表情を音声に合わせて動かすことができるようになります。
※本サイトで掲載しているサンプル画像やサンプル音声はCelebAデータセット[3]およびVoxCeleb2データセット[4]から転用したものです。
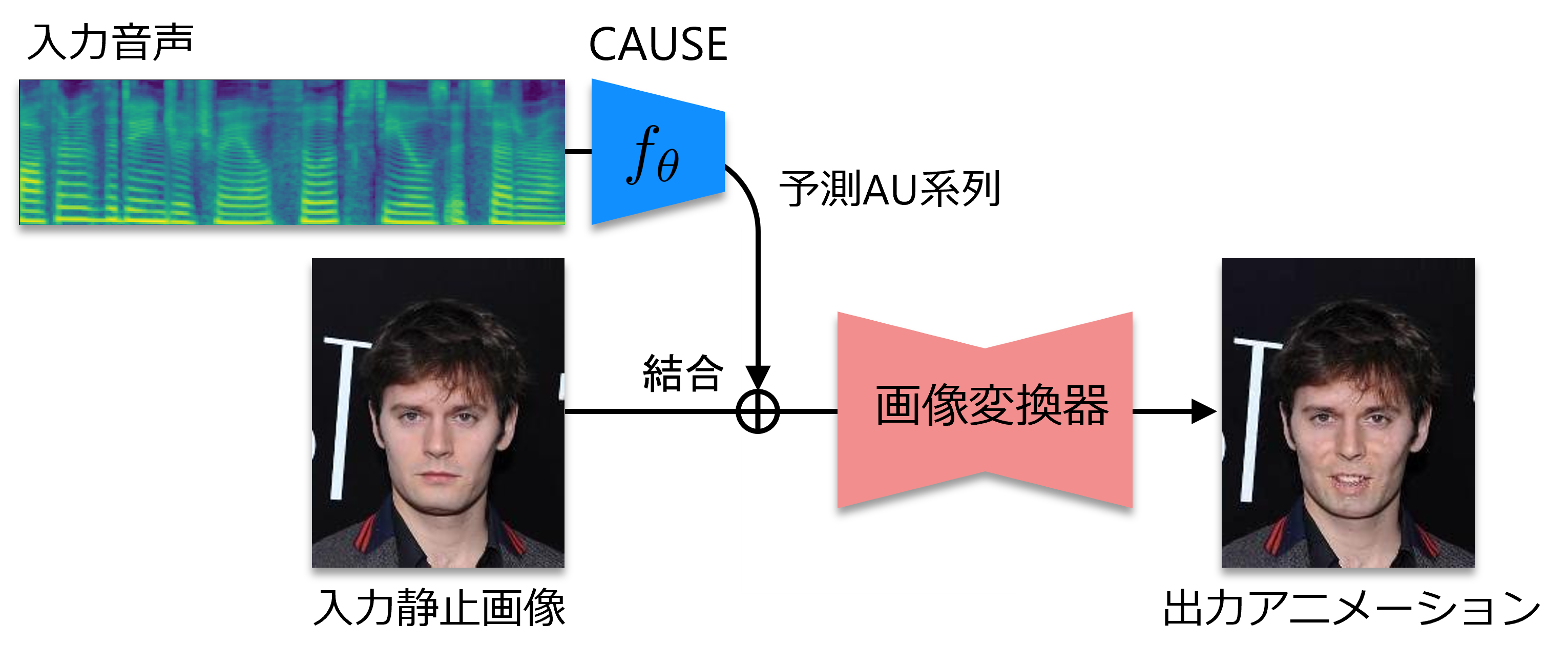
以下では、CAUSEとGANimation[5](Generative Adversarial Networks (GANs)に基づく画像変換手法)を組み合わせて音声から顔アニメーションを生成した例を紹介します。
デモ
1. 顔写真を選んでください








+
2. 音声を選んでください