Hirokazu Kameoka, Kou Tanaka, Damian Kwasny, Takuhiro Kaneko, Nobukatsu Hojo,
"ConvS2S-VC: Fully Convolutional Sequence-to-Sequence Voice Conversion,"
IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1849-1863, Jun. 2020.
(IEEE Xplore)
ConvS2S-VC
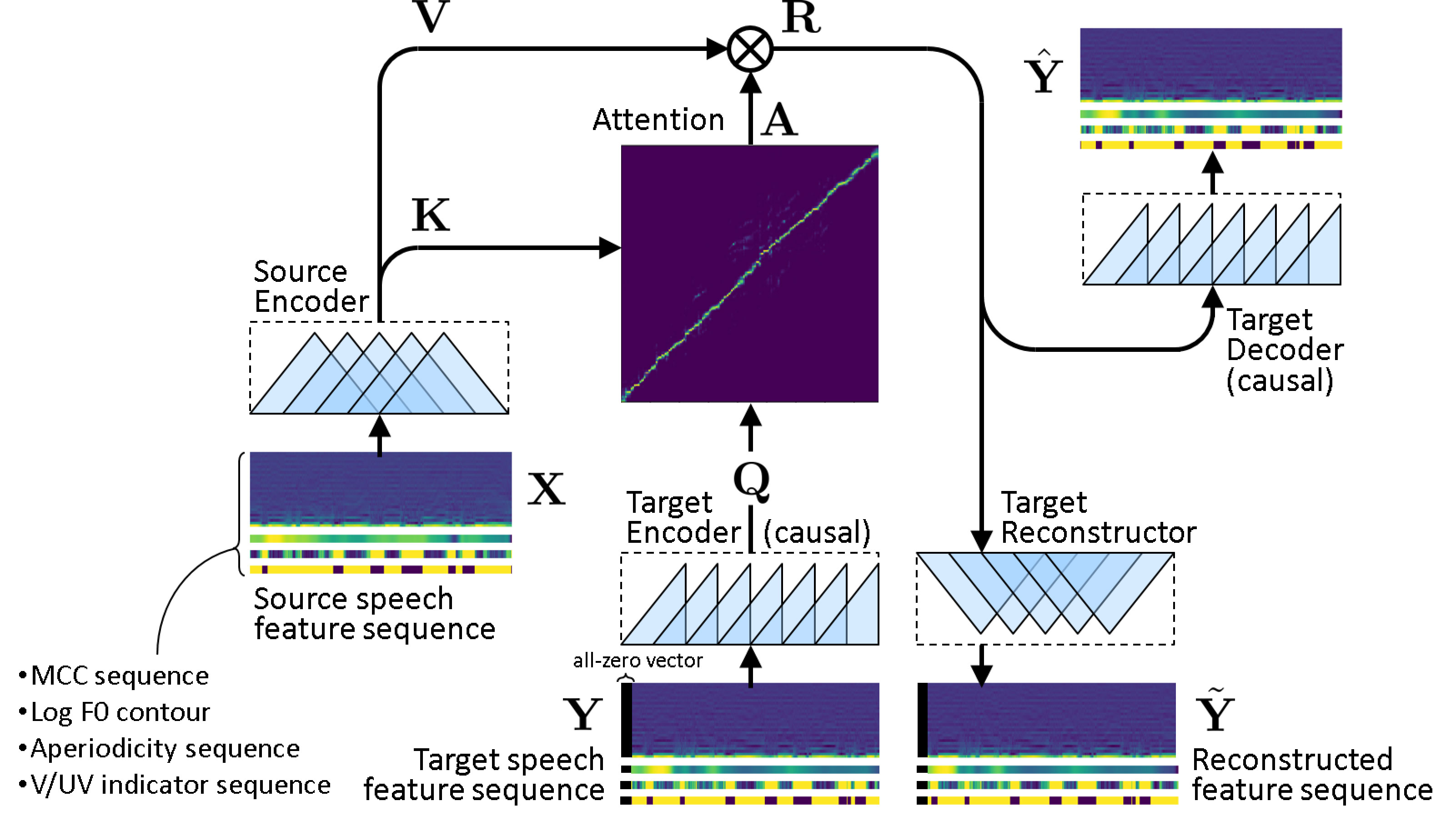
ConvS2S-VC is a voice conversion method based on fully convolutional sequence-to-sequence (seq2seq) learning. It learns the mapping between source and target speech feature sequences using a fully convolutional seq2seq model with an attention mechanism. Owing to the nature of seq2seq learning, our method is particularly noteworthy in that it allows the flexible conversion of not only the voice characteristics but also the pitch contour and duration of the input speech. The current model consists of five networks, namely source and target encoders, a target decoder, and source and target reconstructors, which are designed using dilated causal convolution networks with gated linear units.
Figure 1. Model structure of ConvS2S-VC.
Links to related pages
Please also refer to the following web sites for comparison.
Here are some audio examples of ConvS2S-VC tested on a speaker identity conversion task.
In this experiment, we used the CMU Arctic database [1], which consists of
1132 phonetically balanced English utterances spoken by four US English speakers.
We selected "clb" (female) and "rms" (male) as the source speakers and "slt" (female) and
"bdl" (male) as the target speakers. The audio files for each speaker were manually divided
into 1000 and 132 files, which were provided as training and evaluation sets, respectively.
For each utterance, 28 mel-cepstral coefficients (MCEPs), log F0, aperiodicity, and
voiced/unvoiced information were extracted every 8 ms using the WORLD analyzer.
Audio examples obtained with ConvS2S-VC, its RNN counterpart, and the open-source VC system
called "sprocket" [2] are demonstrated below.
Here are some audio examples of ConvS2S-VC tested on a voice emotional expression conversion task.
All the training and test data used in this experiment consisted of Japanese utterances spoken
by one female speaker with neutral (ntl), angry (ang), sad (sad) and happy (hap) expressions.
Audio examples obtained with sprocket [2] are also provided below.
As these examples show, ConvS2S-VC was able to convert the expressions more naturally than sprocket.
Here are some audio examples of ConvS2S-VC tested on an electrolaryngeal-to-normal speech
conversion task.
Loss of voice after a laryngectomy can lead to a considerable decrease in the quality of life.
Electrolaryngeal (EL) speech is a method of voice restoration using electrolarynx,
which is a battery-operated machine that produces sound to create a voice.
Here, we used ConvS2S-VC to perform EL speech enhancement with the aim of improving
perceived naturalness of EL speech.
Audio examples obtained with sprocket [2] are also provided below.
Since sprocket is designed to only adjust the mean and variance of the log F0 contour of input speech,
the generated speech samples also have flat pitch contours.
Suprasegmental patterns in speech are important factors that
characterize accents in diverse languages.
Owing to the nature of S2S learning, ConvS2S-VC is able to capture and convert
suprasegmental features contained in input speech.
Here are some audio examples of ConvS2S-VC tested on an English accent conversion task
where the voice of an Indian English speaker ("ksp") is converted to that of two American
English speakers ("slt" and "rms") included in the CMU Arctic database [1].
Audio examples obtained with sprocket [2], which is designed to convert
segmental features only, are also provided.
As these examples show, ConvS2S-VC was able to convert the accent of the Indian
English speaker more successfully than sprocket.