Papers
- Wen-Chin Huang, Tomoki Hayashi, Yi-Chiao Wu, Hirokazu Kameoka, Tomoki Toda, "Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining," arXiv:1912.06813 [eess.AS], Dec. 2019.
- Hirokazu Kameoka, Wen-Chin Huang, Kou Tanaka, Takuhiro Kaneko, Nobukatsu Hojo, Tomoki Toda, "Many-to-Many Voice Transformer Network," arXiv:2005.08445 [eess.AS], May 2020.
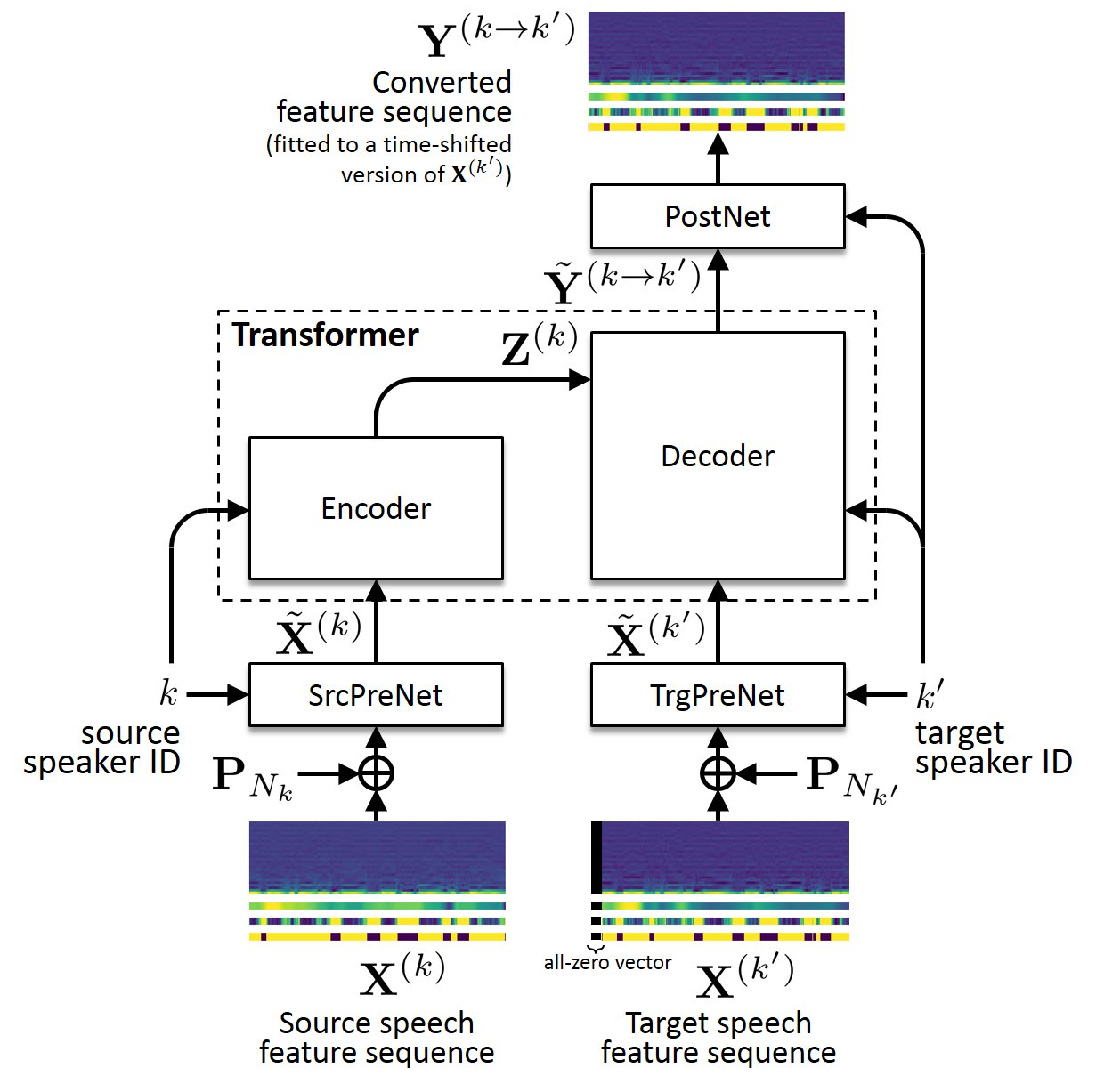
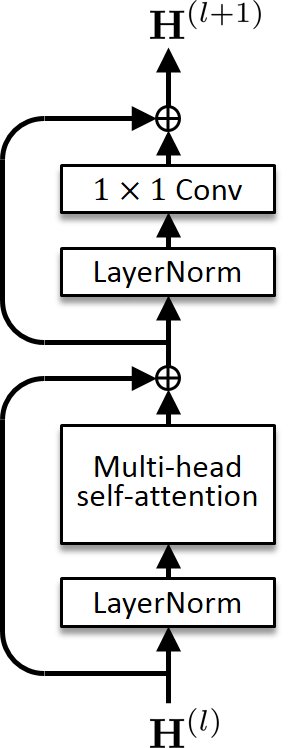
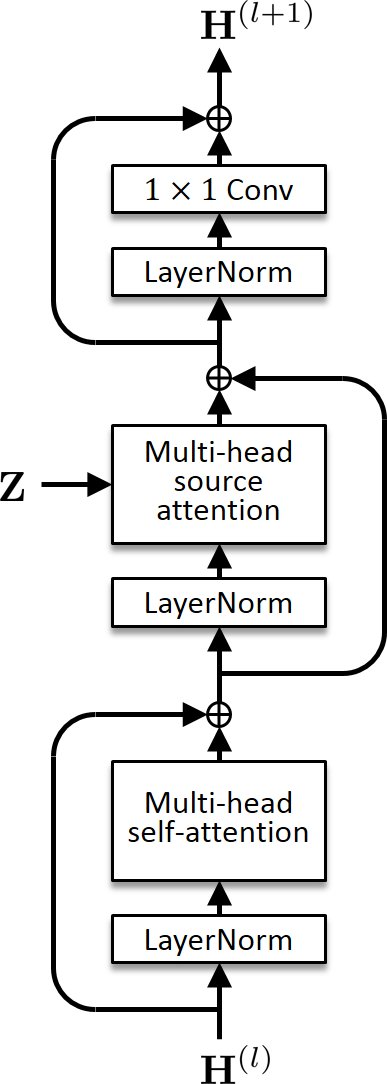
Voice Transformer Network (VTN)
Voice Transformer Network (VTN) is a voice conversion method based on a transformer network architecture. While the default (one-to-one) VTN can only learn the mapping from one speaker's voice into another, the many-to-many VTN is an extension that can simultaneously learn mappings among multiple speakers' voices using a single model. This extension allows us to introduce a training loss called the identity mapping loss to ensure that the input feature sequence will remain unchanged when it already belongs to the target domain. Using this particular loss for model training has been found to be extremely effective in improving the performance.
 |
 |
 |
Links to related pages
Please also refer to the following web sites for comparison.
Audio examples
Speaker identity conversion
Here are some audio examples of many-to-many and one-to-one VTNs tested on a speaker identity conversion task. In this experiment, we used the CMU Arctic database [1], which consists of 1,132 phonetically balanced English utterances spoken by four US English speakers. For each speaker, we used the utterances corresponding to the first 1,000 and last 32 sentences for the training and test sets, respectively. The current version uses 28 mel-cepstral coefficients (MCCs), log F0, aperiodicity, and voiced/unvoiced information extracted from a spectral envelope computed every 8 ms using WORLD as the acoustic feature vector to be converted. We used a speaker-independent WaveNet vocoder [2][3] for waveform generation, trained using the utterances corresponding to the first 1028 sentences of 6 speakers in the same database (including clb, bdl, slt, and rms). Audio examples obtained with the open-source VC system "sprocket" [4] are also demonstrated for comparison.
| VTN (many-to-many) | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
| VTN (one-to-one) | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
| sprocket[4] | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
References
[1] J. Kominek and A. W. Black, "The CMU Arctic speech databases," in Proc. SSW, 2004, pp. 223–224.
[2] https://github.com/kan-bayashi/PytorchWaveNetVocoder
[3] T. Hayashi, A. Tamamori, K. Kobayashi, K. Takeda, and T. Toda, "An investigation of multi-speaker training for WaveNet vocoder," in Proc. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 712-718, 2017.
[4] K. Kobayashi and T. Toda, "sprocket: Open-source voice conversion software," in Proc. Odyssey, 2018, pp. 203–210.