Introduction
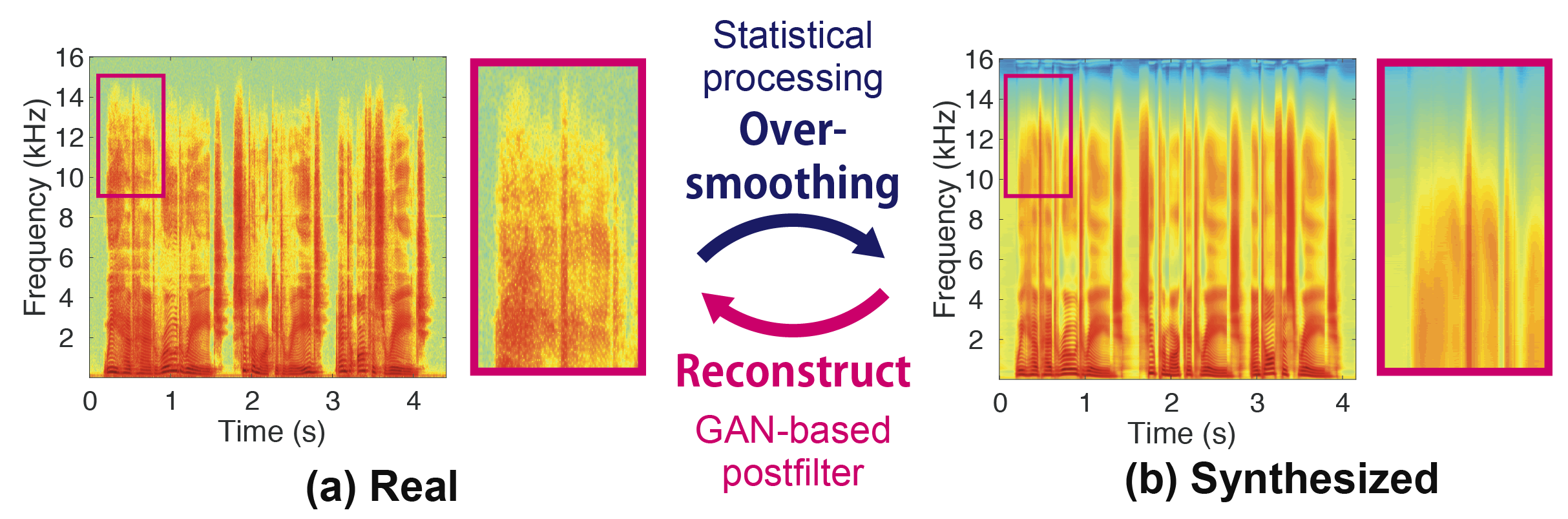
We propose a learning-based postfilter to reconstruct the high-fidelity spectral texture in short-term Fourier transform (STFT) spectrograms. In speech-processing systems, such as speech synthesis, conversion, enhancement, separation, and coding, STFT spectrograms have been widely used as key acoustic representations. In these tasks, we normally need to precisely generate or predict the representations from inputs; however, generated spectra typically lack the fine structures that are close to those of the true data, as shown in Figure 1. To overcome these limitations and reconstruct spectra having finer structures, we propose a generative adversarial network (GAN)-based postfilter [1] for STFT spectrograms. The challenge with this postfilter is that a GAN [2] cannot be easily trained for very high-dimensional data such as STFT spectra. To mitigate this problem, we take a simple divide-and-concatenate strategy. Namely, we first divide the spectrograms into multiple frequency bands with overlap, reconstruct the individual bands using the GAN-based postfilter trained for each band, and finally connect the bands with overlap. We tested our proposed postfilter on a DNN-based TTS task [3] and confirmed that it was able to reduce the gap between synthesized and target spectra, even in the high-dimensional STFT domain.
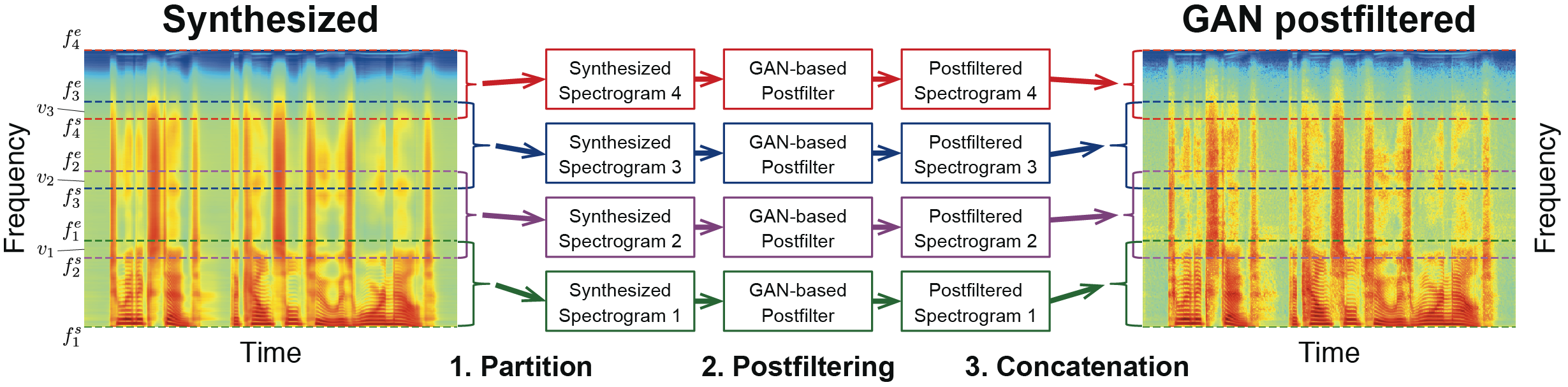
GAN-based Postfilter for STFT Spectrograms
Our goal is to reconstruct convincing STFT spectrograms from the synthesized one. The challenge is that the STFT spectrogram is not only high dimensional but also has a different structure depending on the frequency bands, e.g., a clear harmonic structure can be observed in the low-frequency band, while randomness increases in the high-frequency band. To mitigate this problem, we take a simple divide-and-concatenate strategy. The system overview is summarized in Figure 2.
- Partition: Divide the spectrograms into multiple frequency bands with overlap.
- Postfiltering: Reconstruct the individual bands using the GAN-based postfilter [1] trained for each band.
- Concatenation: Apply a window function to each band to smoothly connect and then concatenate them with overlap.
Experiments
Sample Results
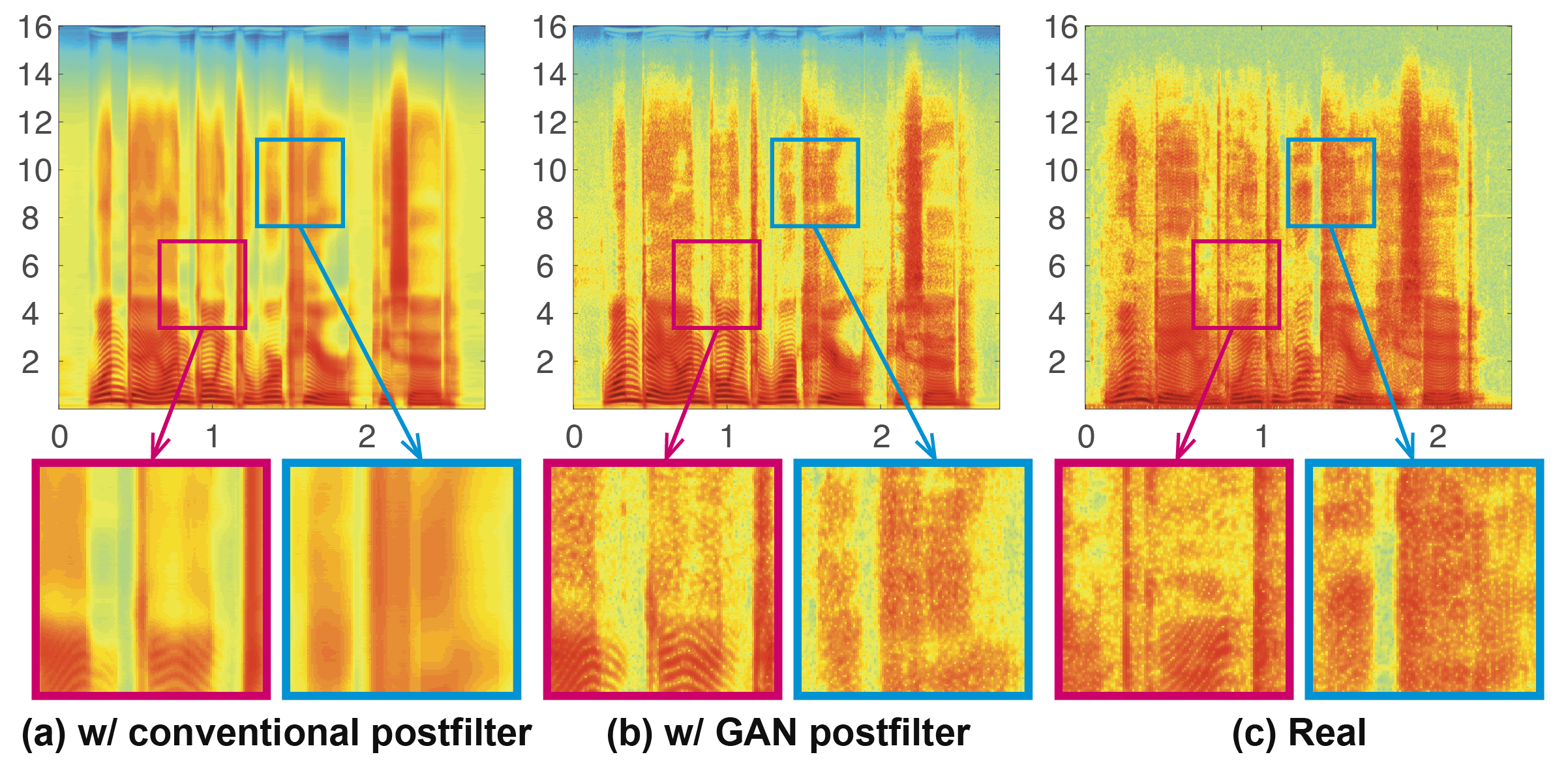
Sample STFT Spectrograms
Sample Speech
| (a) w/ conventional postfilter | (b) w/ GAN postfilter | |
|---|---|---|
| Sample 1 | ||
| Sample 1 (pre-emphasis*) | ||
| Sample 2 |
* Note: Pre-emphasis is used only for listening comparison. These data are not used for training.
Subjective Evaluation
AB Preference Test
- Participants: 18 native speakers of English.
- Sentences: 8 sentences randomly selected from 200 test sentences.

References
[1] Takuhiro Kaneko, Hirokazu Kameoka, Nobukatsu Hojo, Yusuke Ijima, Kaoru Hiramatsu, Kunio Kashino, Generative Adversarial Network-based Postfilter for Statistical Parametric Speech Synthesis. The IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017. [Paper]
[2] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Nets. Advances in Neural Information Processing Systems (NIPS), 2014. [Paper]
[3] Shinji Takaki, Hirokazu Kameoka, Junichi Yamagishi, Direct modeling of frequency spectra and waveform generation based on phase recovery for DNN-based speech synthesis. The Annual Conference of the International Speech Communication Association (Interspeech), 2017. [Paper]
[4] Takuhiro Kaneko, Hirokazu Kameoka, Kaoru Hiramatsu, Kunio Kashino, Sequence-to-Sequence Voice Conversion with Similarity Metric Learned Using Generative Adversarial Networks. The Annual Conference of the International Speech Communication Association (Interspeech), 2017. [Paper]
Contact
Takuhiro Kaneko
NTT Communication Science Laboratories, NTT Corporation
kaneko.takuhiro at lab.ntt.co.jp