Check out our follow-up work:
- iSTFTNet2 (Interspeech 2023): Faster and more lightweight iSTFTNet using 1D-2D CNN
- MISRNet (Interspeech 2022): Lightweight neural vocoder using multi-input single shared residual blocks
- WaveUNetD (ICASSP 2023): Fast and lightweight discriminator using Wave-U-Net
- AugCondD (ICASSP 2024): Augmentation-conditional discriminator for limited data
Abstract
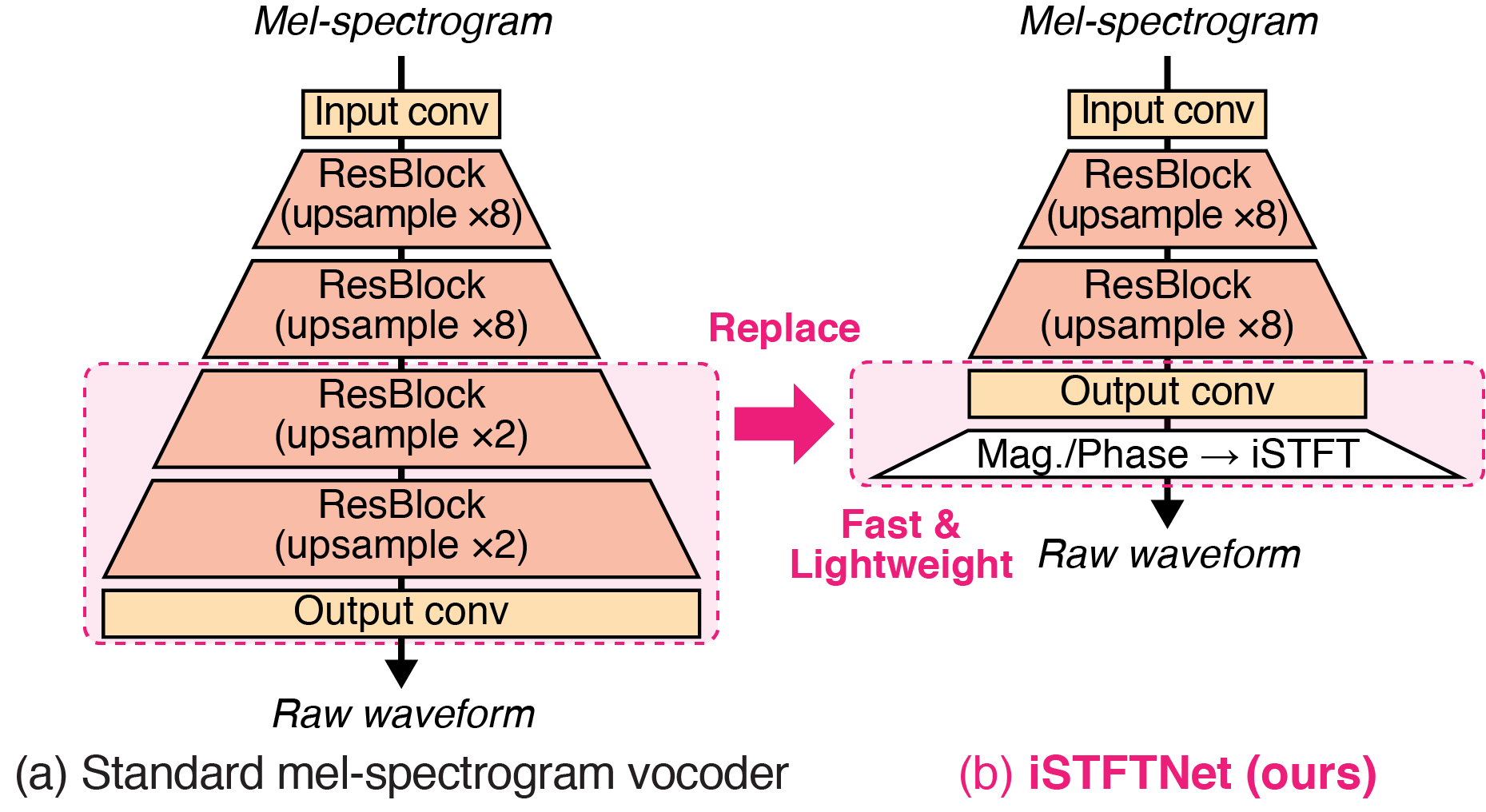
In recent text-to-speech synthesis and voice conversion systems, a mel-spectrogram is commonly applied as an intermediate representation, and the necessity for a mel-spectrogram vocoder is increasing. A mel-spectrogram vocoder must solve three inverse problems: recovery of the original-scale magnitude spectrogram, phase reconstruction, and frequency-to-time conversion. A typical convolutional mel-spectrogram vocoder (Figure 1(a)) solves these problems jointly and implicitly using a convolutional neural network, including temporal upsampling layers, when directly calculating a raw waveform. Such an approach allows skipping redundant processes during waveform synthesis (e.g., the direct reconstruction of high-dimensional original-scale spectrograms). By contrast, the approach solves all problems in a black box and cannot effectively employ the time-frequency structures existing in a mel-spectrogram. We thus propose iSTFTNet (Figure 1(b)), which replaces some output-side layers of the mel-spectrogram vocoder with the inverse short-time Fourier transform (iSTFT) after sufficiently reducing the frequency dimension using upsampling layers, reducing the computational cost from black-box modeling and avoiding redundant estimations of high-dimensional spectrograms. During our experiments, we applied our ideas to three HiFi-GAN variants and made the models faster and more lightweight with a reasonable speech quality.
Experiment results
Main results
Supplementary results
I. Synthesis from ground-truth mel-spectrogram
- Dataset: LJSpeech [1]
- Input: Ground truth mel-spectrogram
- Note: The models denoted by pink color is iSTFTNet.
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | |
|---|---|---|---|---|---|
| Ground truth |
| V1 [2] | |||||
|---|---|---|---|---|---|
| V1-C8C8C2I | |||||
| V1-C8C8I | |||||
| V1-C8I | |||||
| V1-C8C1I |
| V2 [2] | |||||
|---|---|---|---|---|---|
| V2-C8C8C2I | |||||
| V2-C8C8I | |||||
| V2-C8I | |||||
| V2-C8C1I |
| V3 [2] | |||||
|---|---|---|---|---|---|
| V3-C8C8I | |||||
| V3-C8I | |||||
| V3-C8C1I |
| MB-MelGAN [3] | |||||
|---|---|---|---|---|---|
| PWG [4] |
II. Application to text-to-speech synthesis
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | |
|---|---|---|---|---|---|
| Text | made certain recommendations which it believes would, if adopted, | materially improve upon the procedures in effect at the time of President Kennedy's assassination and result in a substantial lessening of the danger. | As has been pointed out, the Commission has not resolved all the proposals which could be made. The Commission nevertheless is confident that, | with the active cooperation of the responsible agencies and with the understanding of the people of the United States in their demands upon their President, | the recommendations we have here suggested would greatly advance the security of the office without any impairment of our fundamental liberties. |
| Ground truth |
| C-FS2 + V1 [2] | |||||
|---|---|---|---|---|---|
| C-FS2 + V1-C8C8I |
| C-FS2 [5] |
|---|
III. Application to multiple speakers
- Dataset: VCTK [6]
- Input: Ground truth mel-spectrogram
- Note: The models denoted by pink color is iSTFTNet.
| Sample 1 (p240) | Sample 2 (p260) | Sample 3 (p280) | Sample 4 (p311) | Sample 5 (p335) | |
|---|---|---|---|---|---|
| Ground truth |
| V1 [2] | |||||
|---|---|---|---|---|---|
| V1-C5C5I | |||||
| V2 [2] | |||||
| V2-C5C5I | |||||
| V3 [2] | |||||
| V3-C10C6I |
IV. Application to Japanese
- Dataset: JSUT [7]
- Input: Ground truth mel-spectrogram
- Note: The models denoted by pink color is iSTFTNet.
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | |
|---|---|---|---|---|---|
| Ground truth |
| V1 [2] | |||||
|---|---|---|---|---|---|
| V1-C5C5I | |||||
| V2 [2] | |||||
| V2-C5C5I | |||||
| V3 [2] | |||||
| V3-C10C6I |
Citation
@inproceedings{kaneko2022istftnet,
title={{iSTFTNet}: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time {Fourier} Transform},
author={Takuhiro Kaneko and Kou Tanaka and Hirokazu Kameoka and Shogo Seki},
booktitle={ICASSP},
year={2022},
}
References
- K. Ito and L. Johnson. The LJ Speech Dataset. 2017.
- J. Kong, J. Kim, J. Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. NeurIPS, 2020.
- G. Yang, S. Yang, K. Liu, P. Fang, W. Chen, L. Xie. Multi-Band Melgan: Faster Waveform Generation For High-Quality Text-To-Speech. SLT, 2021.
- J. Kong, J. Kim, J. Bae. Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram. ICASSP, 2020.
- P. Guo, F. Boyer, X. Chang, T. Hayashi, Y. Higuchi, H. Inaguma, N. Kamo, C. Li, D. Garcia-Romero, J. Shi, J. Shi, S. Watanabe, K. Wei, W. Zhang, Y. Zhang. Recent Developments on ESPnet Toolkit Boosted by Conformer. ICASSP, 2021.
- C. Veaux, J. Yamagishi, K. MacDonald. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit. University of Edinburgh. The Centre for Speech Technology Research, 2017.
- R. Sonobe, S. Takamichi, H. Saruwatari. JSUT Corpus: Free Large-Scale Japanese Speech Corpus for End-to-End Speech Synthesis. arXiv preprint arXiv:1711.00354, 2017.
Our follow-up work
- T. Kaneko, H. Kameoka, K. Tanaka, S. Seki. MISRNet: Lightweight Neural Vocoder Using Multi-Input Single Shared Residual Blocks Interspeech, 2022. Project
- T. Kaneko, H. Kameoka, K. Tanaka, S. Seki. Wave-U-Net Discriminator: Fast and Lightweight Discriminator for Generative Adversarial Network-Based Speech Synthesis ICASSP, 2023. Project
- T. Kaneko, H. Kameoka, K. Tanaka, S. Seki. iSTFTNet2: Faster and More Lightweight iSTFT-Based Neural Vocoder Using 1D-2D CNN. Interspeech, 2023. Project