Multi-agent
Reinforcement Learning of Multi-Robot Delivery Mission via Hierarchical Task Decomposition
and Virtual Work Braking
Hiroshi Kawano
Presented @ ICRA2013 and SMC2013
(Papers are available from IEEE Xplorer ICRA2013,
SMC2013)
Abstract: In
applying reinforcement learning (RL) to multi-robot control, the size of the
learning state space easily explodes because the state space has a high
dimension. Hierarchical reinforcement learning (HRL) is one of the most
practical approaches to solve the problem; however, automatically decomposing a
plain MDP state space into sub-spaces has not been studied thoroughly enough to
be applied to practical robotics problems. We propose a method that
automatically forms hierarchical sub-tasks for multi-robot delivery missions.
The method executes sub-task decomposition and the learning process in a
step-by-step manner, by widening the robot’s range of movements around the load
and gradually decreasing the domain of the load position. The method is free
from state space explosion problem. Once the hierarchical decomposition of the
mission space is done, the action decision policy for each robot is obtained by
distributed reinforcement learning (DiQ). To improve
the stability of the learning process, we treat the work operated by robots as
a new agent that regulates robots’ motion. We assume that the work has braking
ability for its motion. The work stops its motion when the robot attempts to
push the work in an in-appropriate direction. The policy for the work braking
is obtained via dynamic programming of a Markov decision process by using a map
of the environment and the work’s geometry. By virtue of this, DiQ without joint state space shows convergence. Simulation
results also show the high performance of the proposed method in learning
speed.
Summary
of the proposed algorithm is as follows:
We assume a work delivery mission in a
grid space that requires task taking over among robots. In the assumed grid
world, one robot has enough force for pushing the work; however, the work
cannot be delivered from start position to destination without task taking over
because there are points where the travel of a pushing robot is blocked by
obstacles. Usually, reinforcement learning or motion planning for solving such
a problem needs exponential calculation costs.
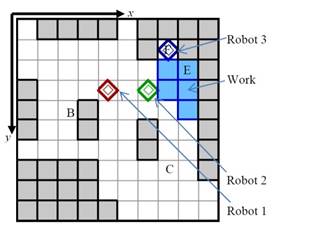
Figure 1. The example of the multi-robot work
delivery mission in which three robots deliver a work from position B to C. At
position E, task taking over among the robots is needed.
We propose a method that solves the
problem of such a high complexity by the consideration of simple kinematical
property of robot and work. I focused on the fact that we cannot distinguish
the case that the pushed work brakes its motion from the case that the robot
stops pushing (As Newton’s third law says “action and reaction force’s strength
is the same”). Therefore, If the work itself knows when it should brake its
motion, for example, in order to make it not derail the desired trajectory or
wait at the proper position until one of the robots arrives at the task taking
over position, such kind of braking action of work can be implemented by robot
motion even though the work has no braking actuators. Such a implementation of
the robot controller can be accomplished very easily using subsumption
architecture. If the robots that carry out reinforcement learning are
controlled in such a policy simulating the Virtual
Work Braking, complicated consideration of task taking over is no longer
needed in the learning process. Therefore, the learning process can be executed
in a single agent reinforcement learning manner.
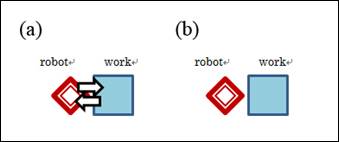
Figure 2. If the adjacent robot and work stay
still, we cannot know whether (a) the robot pushes and the work brakes its
motion or (b) the robot stop pushing.
The virtual working braking policy
itself can be obtained by way of hierarchical dynamic programing in which the
domain of the state space of each stage is defined considering the relative
distance between the robot and the work. At the first stage, the domain of
robot must be adjacent to the work surface and the robot cannot move, but the
work can move whole area of the mission environment. As the stage of the
calculation progresses, the domain of the robot position and action is widen
and the domain of the work position becomes narrower. At the first stage, the
target trajectory of the work considering the robot pushing is obtained, next
in the second stage, the work’s position for task taking over is obtained, and
at last stage, the position of the work that waits for the arrival of the task
taking over robot is obtained. As for the detail see.
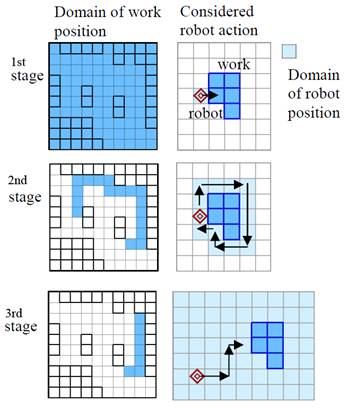
Figire.3 The state spaces in hierarchical
dynamic programming to obtain the information needed in virtual work braking
policy implementation.
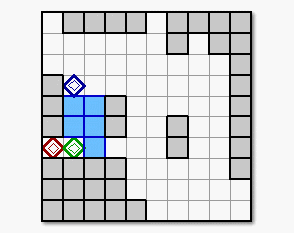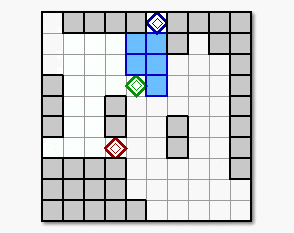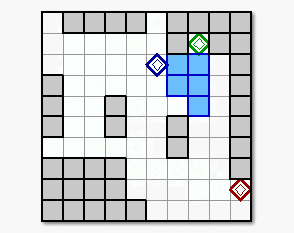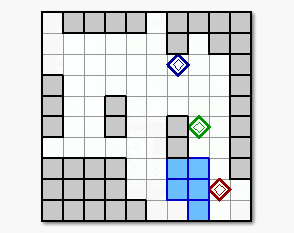
Figure 4. The obtained result of the robots
motion by the proposed learning method in the assumed multi-robot work delivery
mission.
Last
Updated on 2018.06.28