Collective First-Person Vision for Automatic Gaze Analysis in Multiparty Conversations
Shiro Kumano, Kazuhiro Otsuka, Ryo Ishii, and Junji Yamato
NTT Communication Science Laboratories
Abstract
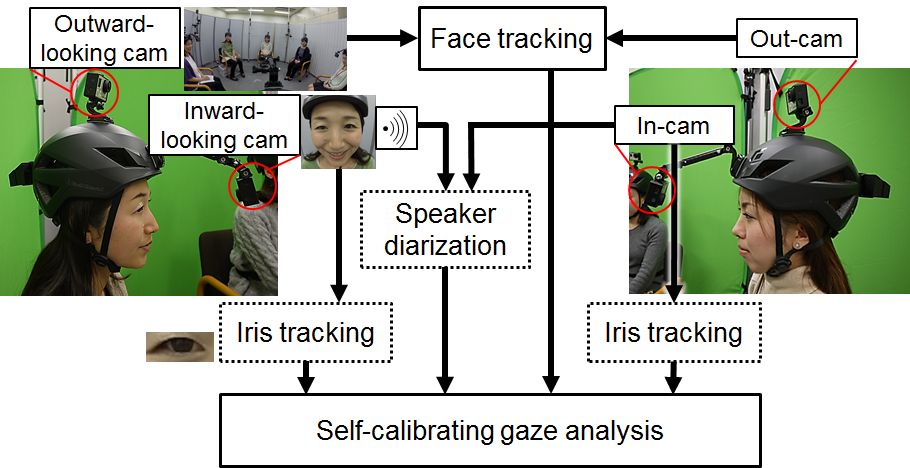
This paper targets small- to medium-sized-group face-to-face conversations where each person wears a dual-view camera, consisting of inward- and outward-looking cameras, and presents an almost fully automatic but accurate off-line gaze analysis framework that does not require users to perform any calibration steps. Our collective first-person vision (Co-FPV) framework, where captured audio-visual signals are gathered and processed in a centralized system, jointly undertakes the fundamental functions required for group gaze analysis, including speaker detection, face tracking, and gaze tracking. Of particular note is our self-calibration of gaze trackers by exploiting a general conversation rule, namely that listeners are likely to look at the speaker. From the rough conversational prior knowledge, our system visualizes fine grained participants' gaze behavior as a gazee-centered heat map, which quantitatively reveals what parts of the gazee's body the participant looked at and for how long while the gazer was speaking or listening. An experiment using conversations amounting to a total of 140 min, each lasting an average of 8.7 min and engaged in by 37 participants in groups of three to six, achieves a mean absolute error of 2.8 degrees in gaze tracking. A statistical test reveals neither a group size effect nor a conversation type effect. Our method achieves F-scores of over .89 and .87 in gazee and eye contact recognition, respectively, in comparison with human annotation.