
Abstract
Fully unsupervised 3D representation learning has gained attention owing to its advantages in data collection. A successful approach involves a viewpoint-aware approach that learns an image distribution based on generative models (e.g., generative adversarial networks (GANs)) while generating various view images based on 3D-aware models (e.g., neural radiance fields (NeRFs)). However, they require images with various views for training, and consequently, their application to datasets with few or limited viewpoints remains a challenge. As a complementary approach, an aperture rendering GAN (AR-GAN) that employs a defocus cue was proposed. However, an AR-GAN is a CNN-based model and represents a defocus independently from a viewpoint change despite its high correlation, which is one of the reasons for its performance. As an alternative to an AR-GAN, we propose an aperture rendering NeRF (AR-NeRF), which can utilize viewpoint and defocus cues in a unified manner by representing both factors in a common ray-tracing framework. Moreover, to learn defocus-aware and defocus-independent representations in a disentangled manner, we propose aperture randomized training, for which we learn to generate images while randomizing the aperture size and latent codes independently. During our experiments, we applied AR-NeRF to various natural image datasets, including flower, bird, and face images, the results of which demonstrate the utility of AR-NeRF for unsupervised learning of the depth and defocus effects.
Method
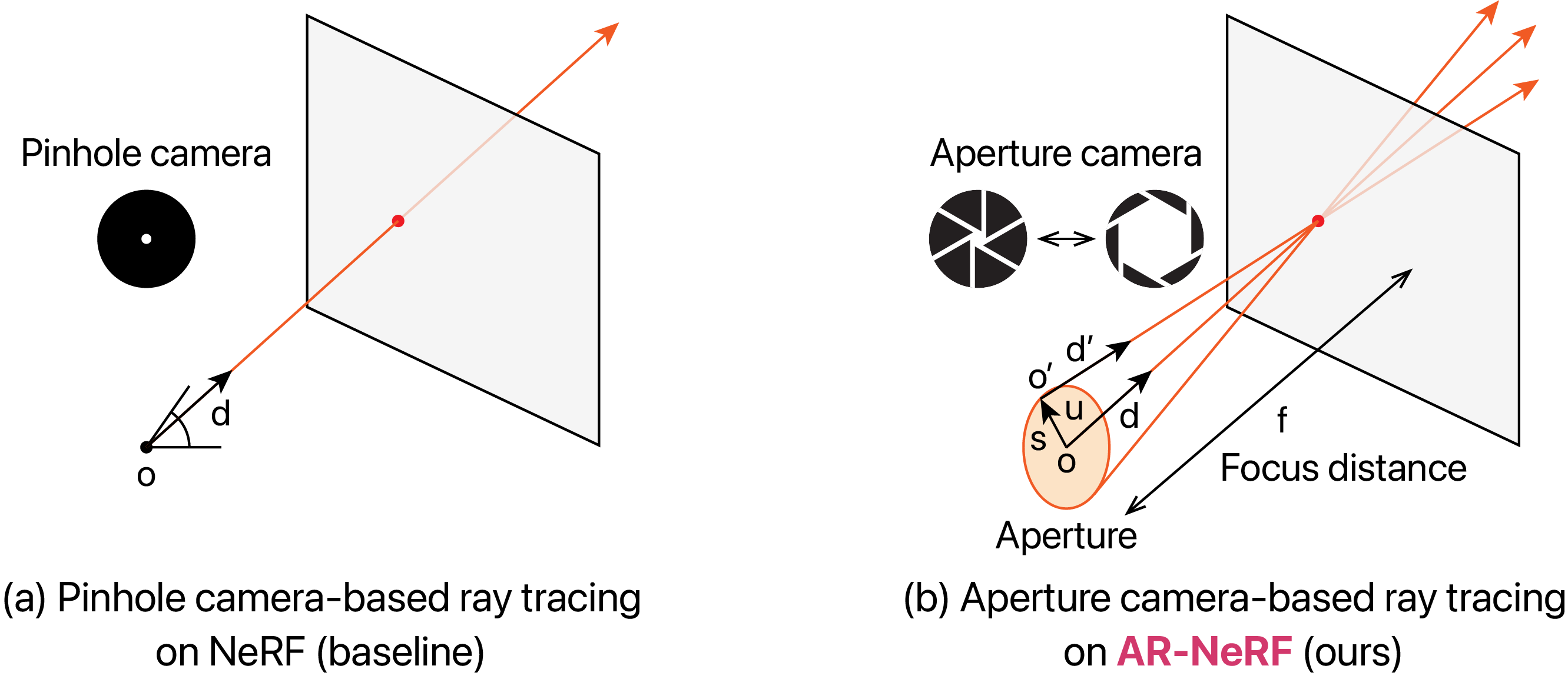
We aim to construct a unified model that can leverage defocus and viewpoint cues jointly by considering the application of unsupervised learning of the 3D representation (particularly depth and defocus effects) from natural unstructured (and view-limited) images. To achieve this, we propose a new extension of NeRF called aperture rendering NeRF (AR-NeRF), which can represent defocus effects and viewpoint changes in a unified manner by representing both factors through a common ray-tracing framework. More precisely, in contrast to the standard NeRF, which represents each pixel using a single ray under the pinhole camera assumption (Figure 2(a)), AR-NeRF employs an aperture camera that represents each pixel using a collection of rays that converge at the focus plane and whose scale is determined according to the aperture size (Figure 2(b)). Through such modeling, we can represent both viewpoint changes and defocus effects by simply changing the inputs and the integration of the implicit function (multilayer perceptron (MLP)), which converts the point position and view direction into the RGB color and volume density. Consequently, through training, we can optimize the MLP while reflecting both factors.
Example results
Examples of generated images and depths



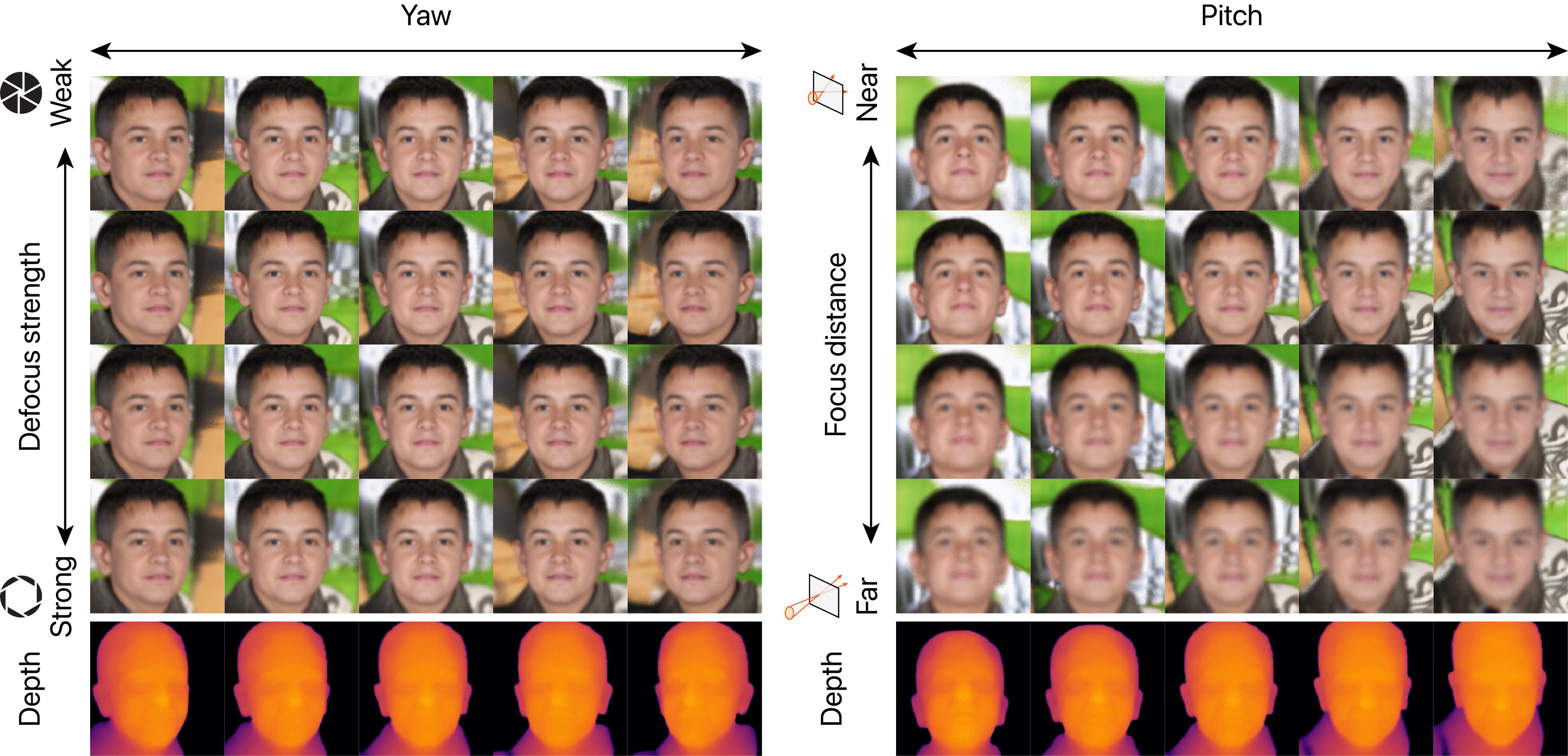
Examples of simultaneous control of viewpoint and defocus
Examples of simultaneous control of latent codes and defocus

Citation
@inproceedings{kaneko2022ar-nerf,
title={{AR-NeRF}: Unsupervised Learning of Depth and Defocus Effects from Natural Images with Aperture Rendering Neural Radiance Fields},
author={Takuhiro Kaneko},
booktitle={CVPR},
year={2022},
}