The Places Japanese audio caption corpus
Japanese spoken captions for the Places205 image dataset
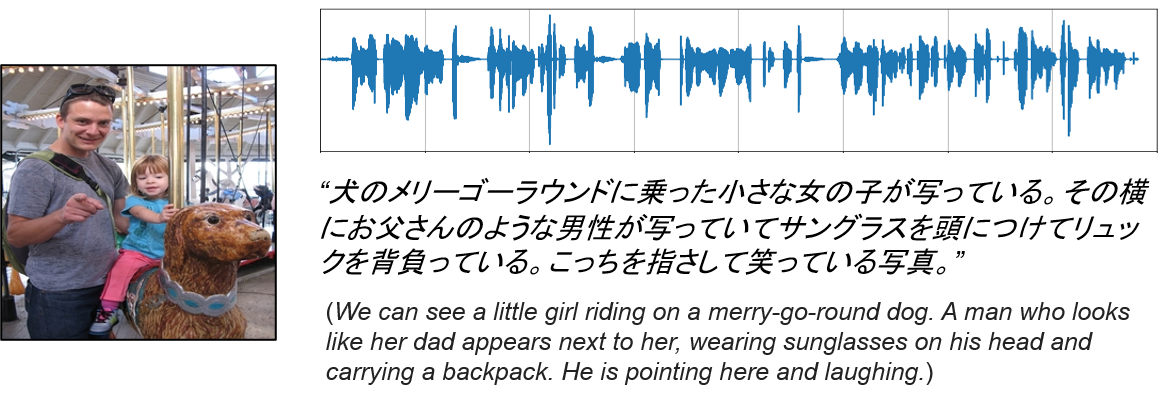
What is the Places Japanese audio caption corpus?
We collected a new corpus of Japanese spoken captions for the Places205 dataset [1]. This speech corpus was collected to investigate the learning of spoken language (words, sub-word units, higher-level semantics, etc.) from visually-grounded speech. We used a subset of 100,000 images from the Places data that have both English [2] and Hindi [3] captions. To collect the Japanese corpus, we recorded a spontaneous, free-form spoken caption for each image using a crowdsourcing service in Japan.
To collect high-quality audio captions, all the recorded signals were checked by human listeners. If a signal contained too much noise or distortions, or was too short, it was excluded from the dataset, and the speaker was asked to rerecord. Through this process, we collected 98,555 captions from 303 unique speakers (182 females and 121 males) in about three months.
The following table shows the average duration and the number of words per caption for each language. The number of words was counted from the speech recognition results. As shown in the table, the listening verification process resulted in longer and richer spoken captions.
| Average duration | Average word count | |
|---|---|---|
| English [2] | 9.5 seconds | 19.3 words |
| Hindi [3] | 11.4 seconds | 20.4 words |
| Japanese [1] | 19.7 seconds | 44.6 words |
Learning semantic correspondences between visual objects and spoken words
Using this dataset we learned semantic correspondences between objects within images and spoken words within their captions without the need for annotated training data in either modality.
Download dataset
Visit the Places Japanese audio caption corpus website hosted by https://zenodo.org/.
The corpus only includes audio recordings, and not the associated images. You will need to separately download the Places image dataset here.
License
The data is distributed under the Creative Commons Attribution-ShareAlike (CC BY-SA) license.
If you use this data in your own publications, please cite the following paper.
@INPROCEEDINGS{Ohishi2020trilingual,
author={Ohishi, Yasunori and Kimura, Akisato and Kawanishi, Takahito and Kashino, Kunio and Harwath, David and Glass, James},
booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Trilingual Semantic Embeddings of Visually Grounded Speech with Self-Attention Mechanisms},
year={2020},
pages={4352-4356},
}
This is a collaborative work with MIT CSAIL.
References
[1] Y. Ohishi, A. Kimura, T. Kawanishi, K. Kashino, D. Harwath, and J. Glass, “Trilingual Semantic Embeddings of Visually Grounded Speech with Self-attention Mechanisms,” in Proc. ICASSP, 2020.
[2] D. Harwath, A. Recasens, D. Sur´ıs, G. Chuang, A. Torralba, and J. Glass, “Jointly discovering visual objects and spoken words from raw sensory input,” International Journal of Computer Vision, 2019.
[3] D. Harwath, G. Chuang, and J. Glass, “Vision as an interlingua: Learning multilingual semantic embeddings of untranscribed speech,” in Proc. ICASSP, 2018.