Masked Modeling Duo for Speech: Specializing General-Purpose Audio Representation to Speech using Denoising Distillation
Abstract
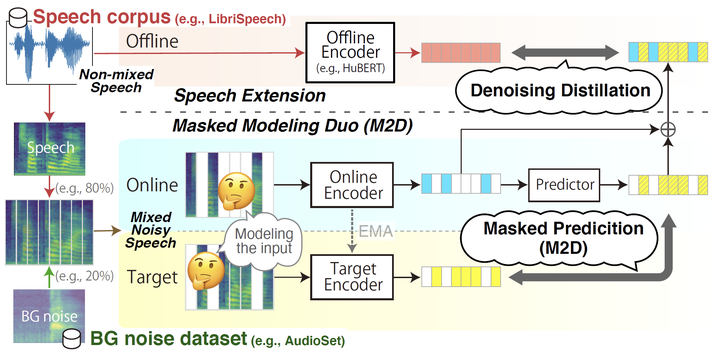
Self-supervised learning general-purpose audio representations have demonstrated high performance in a variety of tasks. Although they can be optimized for application by fine-tuning, even higher performance can be expected if they can be specialized to pre-train for an application. This paper explores the challenges and solutions in specializing general-purpose audio representations for a specific application using speech, a highly demanding field, as an example. We enhance Masked Modeling Duo (M2D), a general-purpose model, to close the performance gap with state-of-the-art (SOTA) speech models. To do so, we propose a new task, denoising distillation, to learn from fine-grained clustered features, and M2D for Speech (M2D-S), which jointly learns the denoising distillation task and M2D masked prediction task. Experimental results show that M2D-S performs comparably to or outperforms SOTA speech models on the SUPERB benchmark, demonstrating that M2D can specialize in a demanding field.