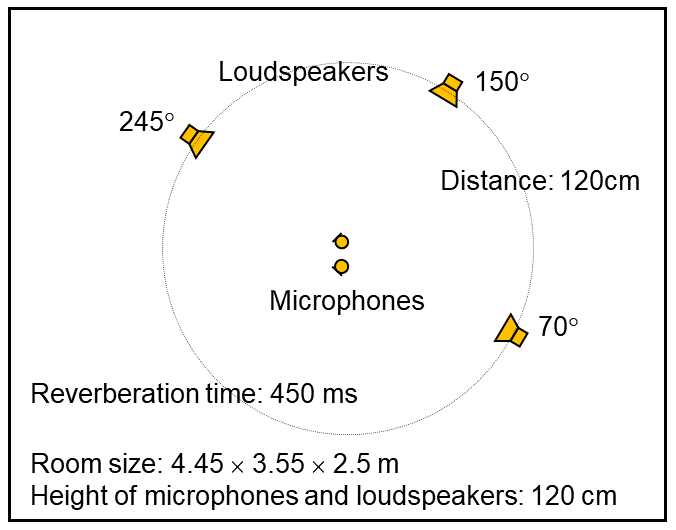
The sampling frequency was 8 kHz. The STFT window width and shift were 1024 and 256 samples, i.e., 128 ms and 32 ms, respectively.
We aimed at two tasks. The first task was blind source separation (BSS) where the reverberations spanning multiple time frames should also be contained in the resultant separated signal. The second task was blind source separation and dereverberation (BSS+BD) where only the early reflections within the current time frame should be contained in the resultant separated signal and the late reverberations in the following time frames should be eliminated.
We executed two methods for both tasks above. The first method is the ordinary FCA. The second method is the multi-frame FCA in which multi-frames were constructed by concatenating the current STFT frame and the previous STFT frames with the frame delays of {2, 4, 6}.
| Stereo mixture | |||
| BSS result by the ordinary FCA | y1 3.26 | y2 3.70 | y3 1.43 |
| BSS result by the proposed multi-frame FCA | y1 7.66 | y2 6.96 | y3 4.33 |
| BSS+BD result by the ordinary FCA | y1 2.94 | y2 4.10 | y3 1.25 |
| BSS+BD result by the proposed multi-frame FCA | y1 5.72 | y2 6.76 | y3 4.50 |
The numbers show the signal-to-distortion ratios (SDRs) in dB.
Unlike the multi-frame FCA, the ordinary FCA does not model the previous STFT frames with the frame delays . Therefore, the separated signals are the same between the BSS and BSS+BD tasks in the ordinary FCA. In the table above, the SDR numbers are different. This is because the reference signals were different.
On the other hand, the multi-frame FCA produces different results for BSS and BSS+BD tasks. You can clearly hear the difference. There are the reverberations of the target signal remained in the sounds of the BSS task, whereas the late reverberations were eliminated in the sounds of the BSS+BD task.