
プログラム / 講演・研究展示一覧 /

現在の音声認識システムは音響モデルと言語モデルを利用して音声をテキストに変換します.より正しい認識結果を得るにはモデルの学習技術が重要です.現状,流暢な話し言葉を対象とする場合や,学習データが十分に無い場合には認識精度の劣化がみられ,音声認識の普及を妨げる要因となっています.従来,音声データと人が与えた正解文のみからモデル学習を行っていましが,ここ最近,音声認識結果と正解文の照らし合わせを行う識別的学習法が注目を集めています.このテストの答え合わせのような学習法では,間違いやすい箇所を修正することができるため,より高い認識精度が期待できます.音響・言語の両モデルについて,既存手法より高精度なモデルを生成可能な識別的学習法を実現することができました.これらを駆使することで,会話音声のような流暢な話し言葉に対しても,一定の品質の音声認識結果を提供することができるようになりました.これらの技術について分かり易く解説します.
展示パネル
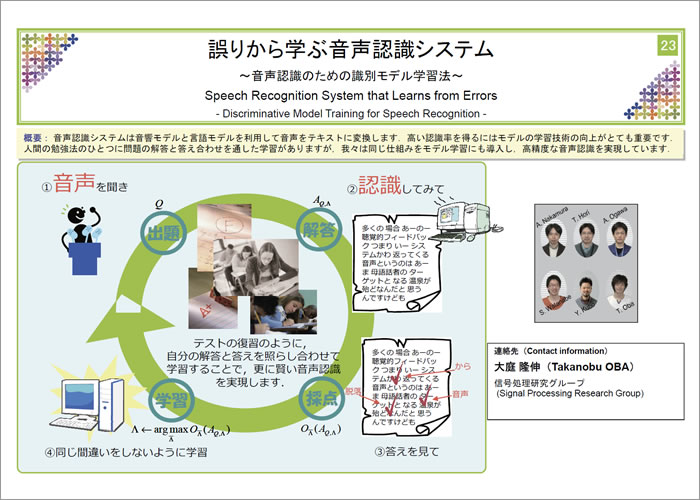
画像をクリックするとPDF版が開きます





