


| 17 |
Controlling facial expressions in face image from speechCrossmodal action unit sequence estimation and image-to-image mapping 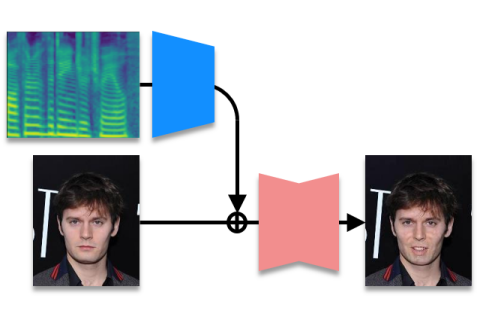
|
|---|
Speech contains not only linguistic information, corresponding to the uttered sentence, but also nonlinguistic information, corresponding to the emotional expression and mood. This information plays an important role in spoken dialogue. This study is the first attempt to estimate the action unit (facial muscle motion parameter) sequence of the speaker from speech alone, assuming that the nonlinguistic information in speech is expressed in the facial expressions of the speaker. Until now, there have been no attempts to estimate action units from speech alone, and how much accuracy could be achieved was not known. This study reveals this for the first time. By combining the action unit sequence estimated from speech with an image-to-image converter, we implemented a system that modifies the facial expression of a still face image in accordance with input speech, making it possible to visualize the expression and mood of speech. Emotional expressions and moods have traditionally been treated symbolically, assigning discrete subjective labels. In contrast, action units are suitable as continuous quantities for expressing emotional expressions and moods, and we have shown that action units can be estimated from speech in this study. In the future, we expect to open up a variety of new applications that simultaneously utilize speech and face images, such as speech synthesis that matches facial expressions and face image generation that matches speech.

[1] H. Kameoka, T. Kaneko, S. Seki, K. Tanaka, “CAUSE: Crossmodal action unit sequence estimation from speech,” submitted to The 23rd Annual Conference of the International Speech Communication Association (Interspeech 2022).

Hirokazu Kameoka / Recognition Research Group, Media Information Laboratory
Email: cs-openhouse-ml@hco.ntt.co.jp