Papers
- Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, and Yuto Kondo, "LatentVoiceGrad: Nonparallel Voice Conversion with Latent Diffusion/Flow-Matching Models," arXiv:2509.08379 [cs.SD], Sep. 2025.
- Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, and Yuto Kondo, "LatentVoiceGrad: Nonparallel Voice Conversion with Latent Diffusion/Flow-Matching Models," submitted to IEEE/ACM Transactions on Audio, Speech and Language Processing, 2025.
VoiceGrad and LatentVoiceGrad
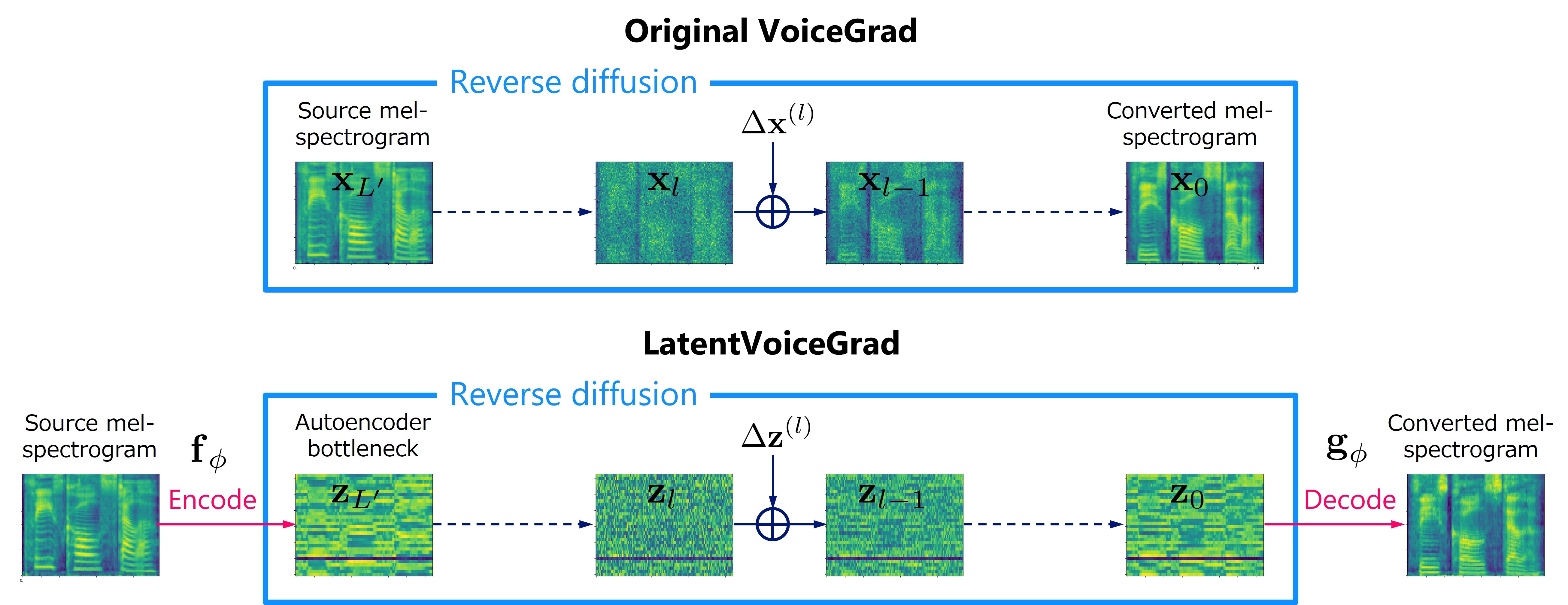
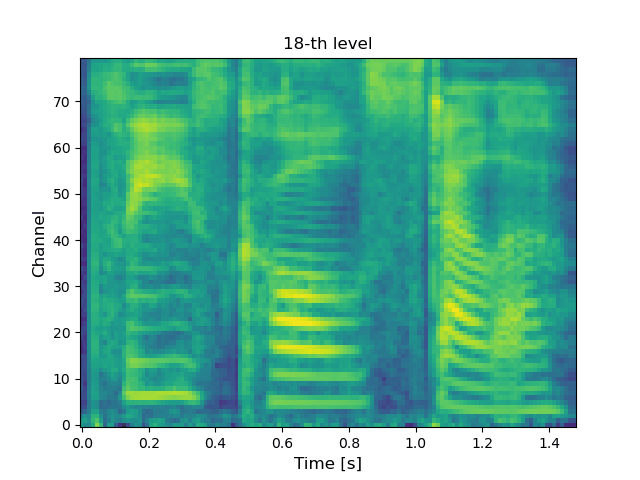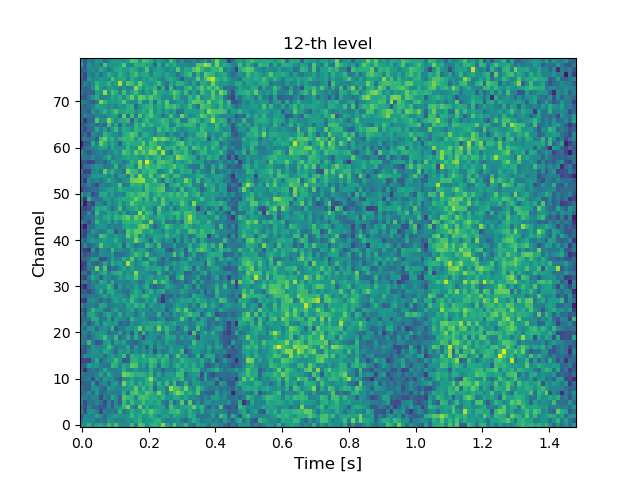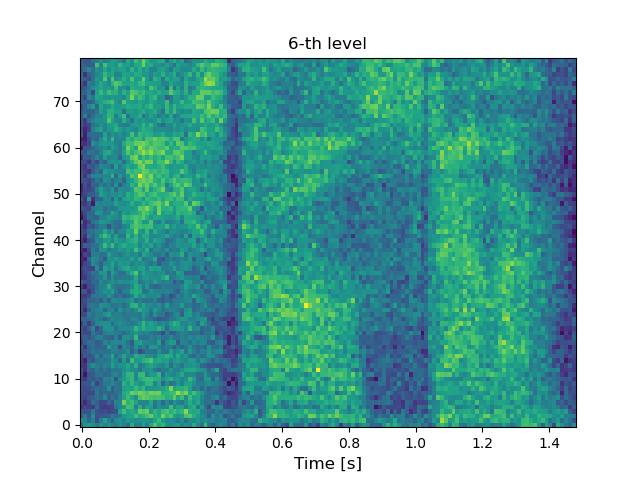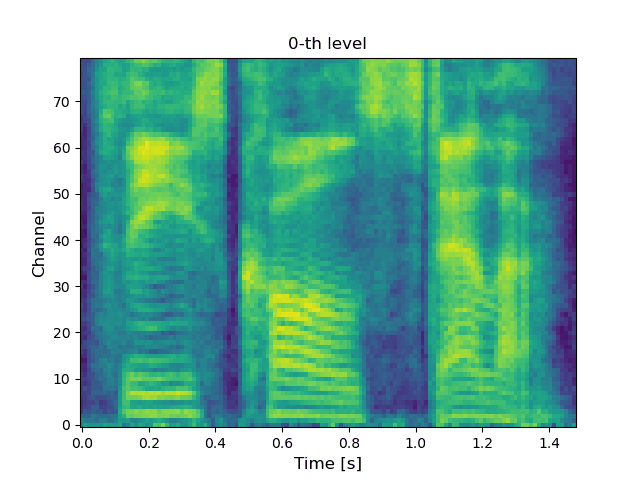
VoiceGrad [1][2] is a nonparallel voice conversion (VC) technique enabling mel-spectrogram conversion from source to target speakers using a diffusion probabilistic model (DPM) [3]. The score network is designed to be conditioned on a speaker embedding, timestep, and phoneme embedding sequence, and is trained using speech samples from various speakers. The trained score network can be used to execute VC by iteratively adjusting an input mel-spectrogram until resembling the target speaker’s. The original VoiceGrad used a one-hot vector for the speaker embedding, limiting it to converting input speech to the voices of known speakers. Here, we modify it to use the speaker embedding generated by a pre-trained speaker encoder from a reference voice, enabling zero-shot conversion (i.e., any-to-any conversion). LatentVoiceGrad is an improved version of VoiceGrad, which applies reverse diffusion to the autoencoder bottleneck features of mel-spectrograms obtained using an adversarially trained autoencoder. Additionally, a flow matching (FM) model [4] is also introduced as an alternative to the DPM to further speed up the conversion process. This results in four possible approaches, depending on whether we use the mel-spectrogram or the autoencoder bottleneck as the data to be converted, and whether the DPM or FM model serves as the underlying generative model. Below, these are referred to as VoiceGrad-DPM, LatentVoiceGrad-DPM, VoiceGrad-FM, and LatentVoiceGrad-FM.
|
|
|
(Click to enlarge) |
|
|
|
|
(Click to enlarge) |
|
|
|
|
(Click to enlarge) |
|
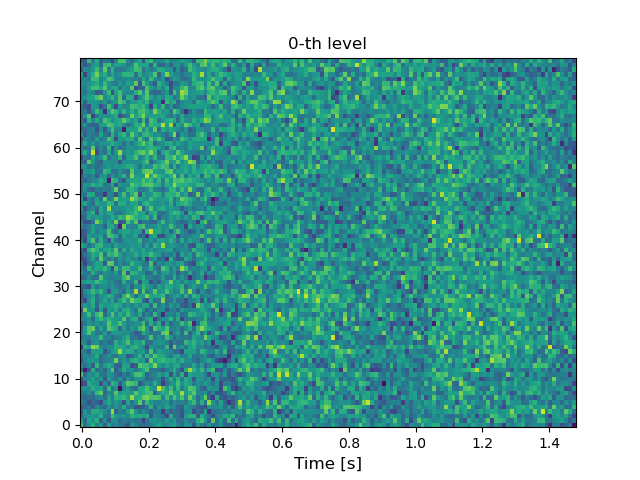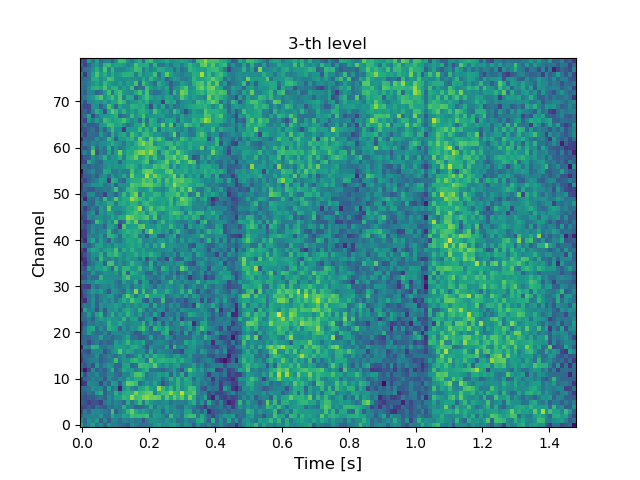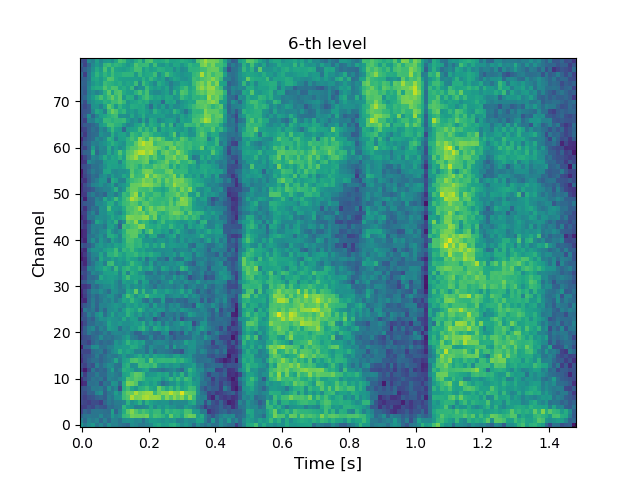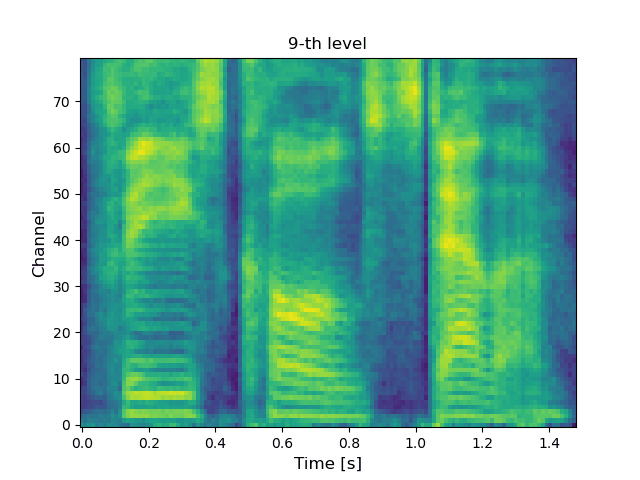
|
|
|
(Click to enlarge) |
|
|
|
|
(Click to enlarge) |
|
Links to related pages
Please also refer to the following web sites.
- Previous version of VoiceGrad
- Links to my other work
Audio examples
Speaker identity conversion
Here are audio examples of speaker identity conversion tested on the CSTR VCTK Corpus (version 0.92) [5], which contains speech data from 110 English speakers with various accents. To simulate a zero-shot any-to-any VC scenario, utterances from ten speakers (p238, p241, p243, p252, p261, p294, p334, p343, p360, and p362) were used as test data and those from the remaining speakers as training data. This resulted in 90 source-target speaker combinations for testing, with the task being to convert input seech into a voice similar to that of a reference utterance. Audio examples obtained with a DPM-based VC method similar to ours (Diff-VC) [6] are also provided for comparison.
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
|---|---|---|---|---|---|---|---|---|
| DPM | FM | DPM | FM | |||||
| p238 |
p241 | |||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p241 |
p238 | |||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p243 |
p238 | |||||||
| p241 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p252 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p261 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p294 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p334 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p343 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p360 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p360 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p362 | ||||||||
| Input |
Reference |
Diff-VC | VoiceGrad | LatentVoiceGrad | ||||
| DPM | FM | DPM | FM | |||||
| p362 |
p238 | |||||||
| p241 | ||||||||
| p243 | ||||||||
| p252 | ||||||||
| p261 | ||||||||
| p294 | ||||||||
| p334 | ||||||||
| p343 | ||||||||
| p360 | ||||||||
References
[1] H. Kameoka, T. Kaneko, K. Tanaka, N. Hojo, and S. Seki, "VoiceGrad: Non-parallel any-to-many voice conversion with annealed Langevin dynamics," arXiv:2010.02977 [cs.SD], 2020.
[2] H. Kameoka, T. Kaneko, K. Tanaka, N. Hojo, and S. Seki, "VoiceGrad: Non-parallel any-to-many voice conversion with annealed Langevin dynamics," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2213–2226, 2024.
[3] J. Ho, A. Jain, and P. Abbeel, "Denoising diffusion probabilistic models," in Adv. Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 6840–6851.
[4] Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, "Flow matching for generative modeling," in Proc. International Conference on Learning Representations (ICLR), 2023, pp. 1–28.
[5] https://datashare.ed.ac.uk/handle/10283/3443
[6] V. Popov, I. Vovk, V. Gogoryan, T. Sadekova, M. Kudinov, and J. Wei, "Diffusion-based voice conversion with fast maximum likelihood sampling scheme," in Proc. International Conference on Learning Representations (ICLR), 2022, pp. 1-23.