Papers
- Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, Nobukatsu Hojo, and Shogo Seki, "VoiceGrad: Non-Parallel Any-to-Many Voice Conversion with Annealed Langevin Dynamics," arXiv:2010.02977 [cs.SD], Oct. 2020.
VoiceGrad
VoiceGrad is a voice conversion (VC) method based upon the concepts of denoising score matching (DSM) [1], annealed Langevin dynamics, and diffusion probabilistic models (DPMs) [2], inspired by WaveGrad [3], a recently introduced novel waveform generation method. The idea involves training a score approximator, a fully convolutional network with a U-Net structure, to predict the gradient of the log density of the mel-spectrograms of multiple speakers. The trained score approximator can be used to perform VC by using annealed Langevin dynamics or reverse diffusion process to iteratively update an input mel-spectrogram towards the nearest stationary point of the target distribution. The current version uses HiFi-GAN [4] to generate a waveform from the converted mel-spectrogram. The following are audio examples of the DSM and DPM versions of VoiceGrad alongside some conventional methods for comparison.
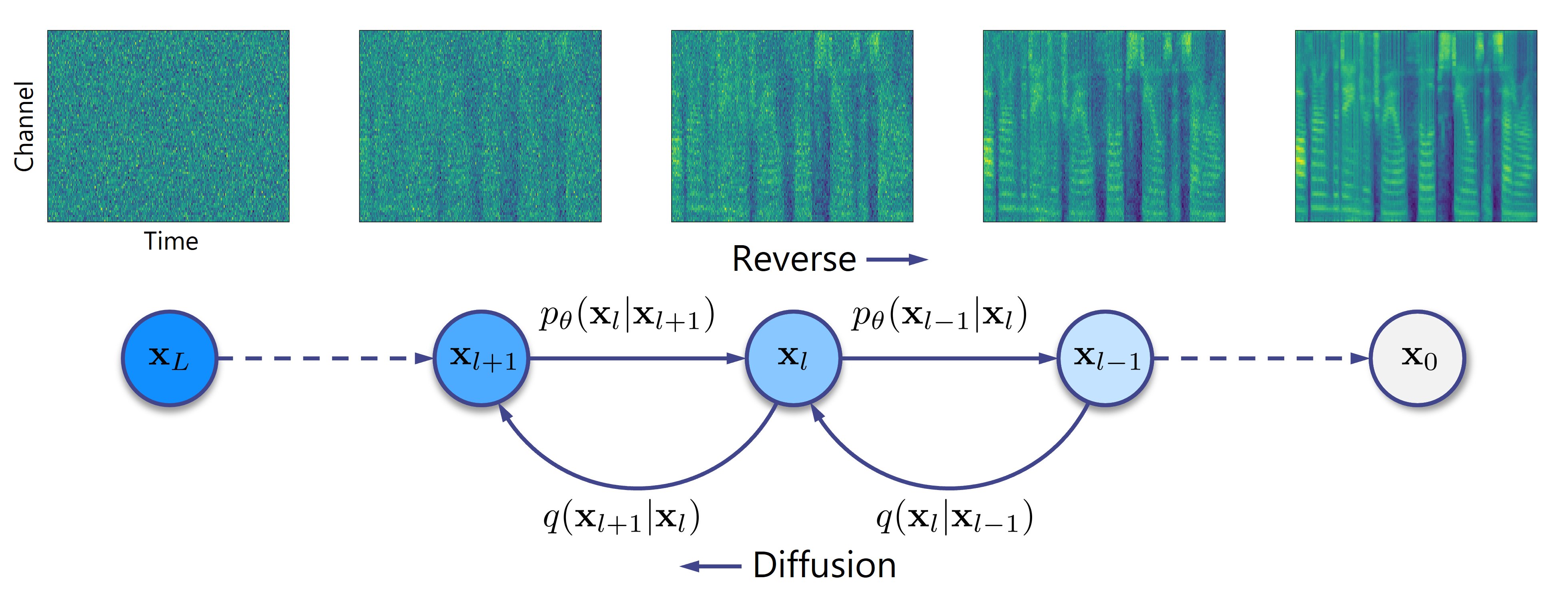 |
(Click to enlarge) |
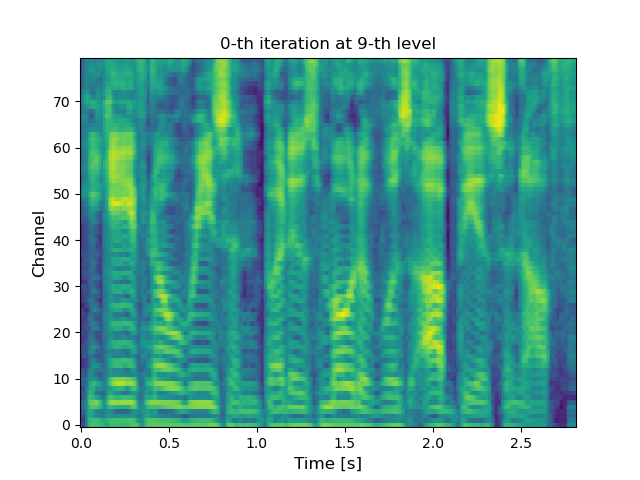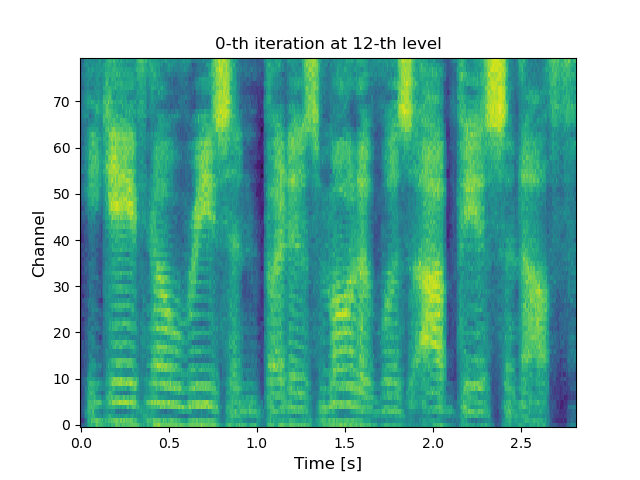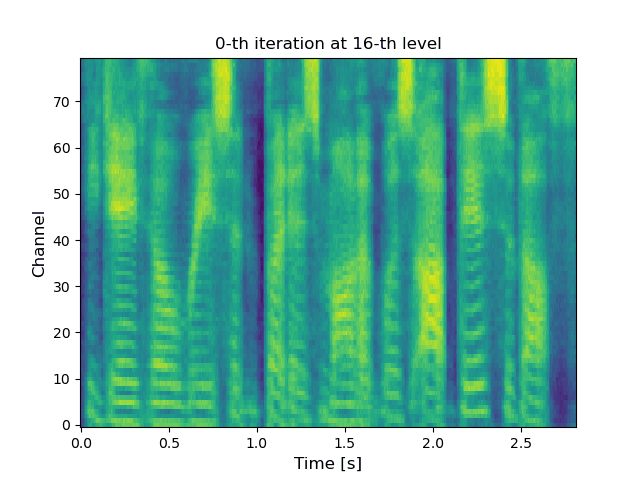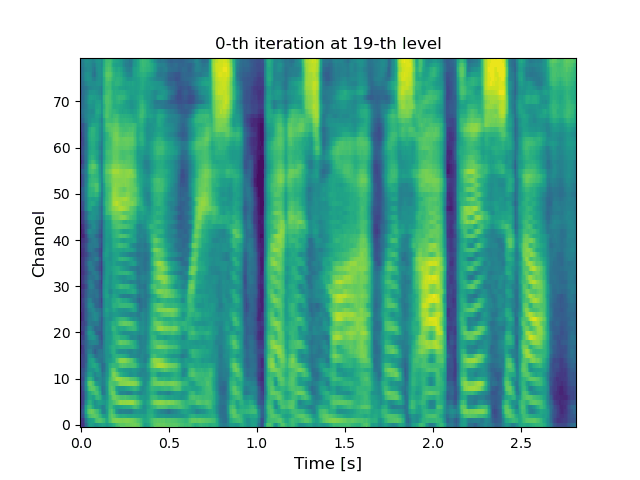 |
(Click to enlarge) |
Links to related pages
Please also refer to the following web sites.
- Version 1 of VoiceGrad (applied to mel-cepstral sequences)
- Links to my other work
Audio examples
Speaker identity conversion
Here are audio examples of speaker identity conversion tested on the CMU Arctic database [5], which consists of 1132 phonetically balanced English utterances spoken by two female speakers ("clb" and "slt") and two male speakers ("bdl" and "rms"). The audio files for each speaker were manually divided into sets of 1000 and 132 files, and the first set was provided as the training set for VoiceGrad and HiFi-GAN. Additionally, utterances of one female speaker ("lnh") and two male speakers ("jmk" and "ksp") are used as test samples of unknown speakers. Audio examples obtained with StarGAN-VC [6][7][8], AutoVC [9], and PPG-VC [10] are also provided for comparison.
| Input |
Target |
StarGAN-VC | AutoVC | PPG-VC | VoiceGrad | |||
|---|---|---|---|---|---|---|---|---|
| DSM | DPM | DPM+BNF | ||||||
| clb |
bdl | |||||||
| slt | ||||||||
| rms | ||||||||
| bdl |
clb | |||||||
| slt | ||||||||
| rms | ||||||||
| slt |
clb | |||||||
| bdl | ||||||||
| rms | ||||||||
| rms |
clb | |||||||
| bdl | ||||||||
| slt | ||||||||
| Input |
Target |
StarGAN-VC | AutoVC | PPG-VC | VoiceGrad | |||
|---|---|---|---|---|---|---|---|---|
| DSM | DPM | DPM+BNF | ||||||
| jmk |
clb | |||||||
| bdl | ||||||||
| slt | ||||||||
| rms | ||||||||
| ksp |
clb | |||||||
| bdl | ||||||||
| slt | ||||||||
| rms | ||||||||
| lnh |
clb | |||||||
| bdl | ||||||||
| slt | ||||||||
| rms | ||||||||
References
[1] Y. Song and S. Ermon, "Generative modeling by estimating gradientsof the data distribution," in Adv. Neural Information Processing Systems (NeurIPS), 2019, pp. 11918–11930.
[2] J. Ho, A. Jain, and P. Abbeel, "Denoising diffusion probabilistic models," in Adv. Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 6840–6851.
[3] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan, "WaveGrad: Estimating gradients for waveform generation," in Proc. International Conference on Learning Representations (ICLR), 2021.
[4] J. Kong, J. Kim, and J. Bae, "HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis," in Adv. Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 17022–17033.
[5] J. Kominek and A. W. Black, "The CMU Arctic speech databases," in Proc. Speech Synthesis Workshop (SSW), 2004, pp. 223–224.
[6] H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, "StarGAN-VC: Non-parallel many-to-many voice conversion using star generative adversarial networks," in Proc. IEEE Spoken Language Technology Workshop (SLT), 2018, pp. 266-273.
[7] T. Kaneko, H. Kameoka, K. Tanaka, and N. Hojo, "StarGAN-VC2: Rethinking conditional methods for StarGAN-based voice conversion," in Proc. Annual Conference of the International Speech Communication Association (Interspeech), 2019, pp. 679-683.
[8] H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, "Nonparallel voice conversion with augmented classifier star generative adversarial networks," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2982-2995, 2020.
[9] K. Qian, Y. Zhang, S. Chang, X. Yang, and M. Hasegawa-Johnson, "AutoVC: Zero-shot voice style transfer with only autoencoder loss," in Proc. International Conference on Machine Learning (ICML), 2019, pp. 5210–5219.
[10] S. Liu, Y. Cao, D. Wang, X. Wu, X. Liu, and H. Meng, "Any-to-many voice conversion with location-relative sequence-to-sequence modeling," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1717–1728, 2021.