Papers
- Hirokazu Kameoka, Kou Tanaka, and Takuhiro Kaneko, "FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion," arXiv:2104.06900 [cs.SD], 2021. (PDF)
- Hirokazu Kameoka, Kou Tanaka, Damian Kwasny, Takuhiro Kaneko, Nobukatsu Hojo, "ConvS2S-VC: Fully Convolutional Sequence-to-Sequence Voice Conversion," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1849-1863, Jun. 2020. (IEEE Xplore)
- Kou Tanaka, Hirokazu Kameoka, Takuhiro Kaneko, Nobukatsu Hojo, "AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms," in Proc. 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2019), pp. 6805-6809, May 2019. (PDF)
- Hirokazu Kameoka, Wen-Chin Huang, Kou Tanaka, Takuhiro Kaneko, Nobukatsu Hojo, and Tomoki Toda, "Many-to-Many Voice Transformer Network," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 656-670, 2021. (IEEE Xplore)
Sequence-to-Sequence Voice Conversion (S2S-VC)
S2S-VC2 is a voice conversion (VC) method that uses sequence-to-sequence (seq2seq or S2S for short) models to learn mappings between the feature sequences (such as the mel-spectrograms) of source and target speech [1]. It reduces to ConvS2S-VC [2], RNNS2S-VC [3], and Transformer-VC [4] as special cases, depending on the architecture design. In the following, audio samples generated via mel-spectrogram conversion using our S2S models, followed by waveform generation using Parallel WaveGAN [5][6], are demonstrated.
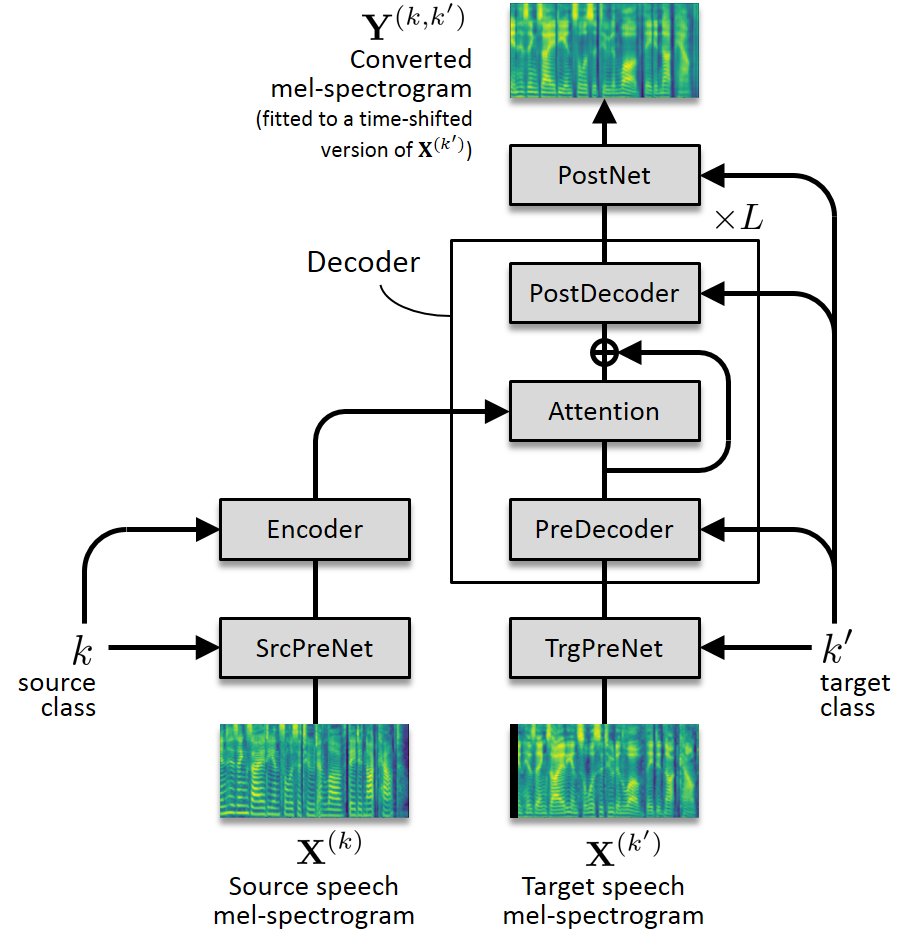 |
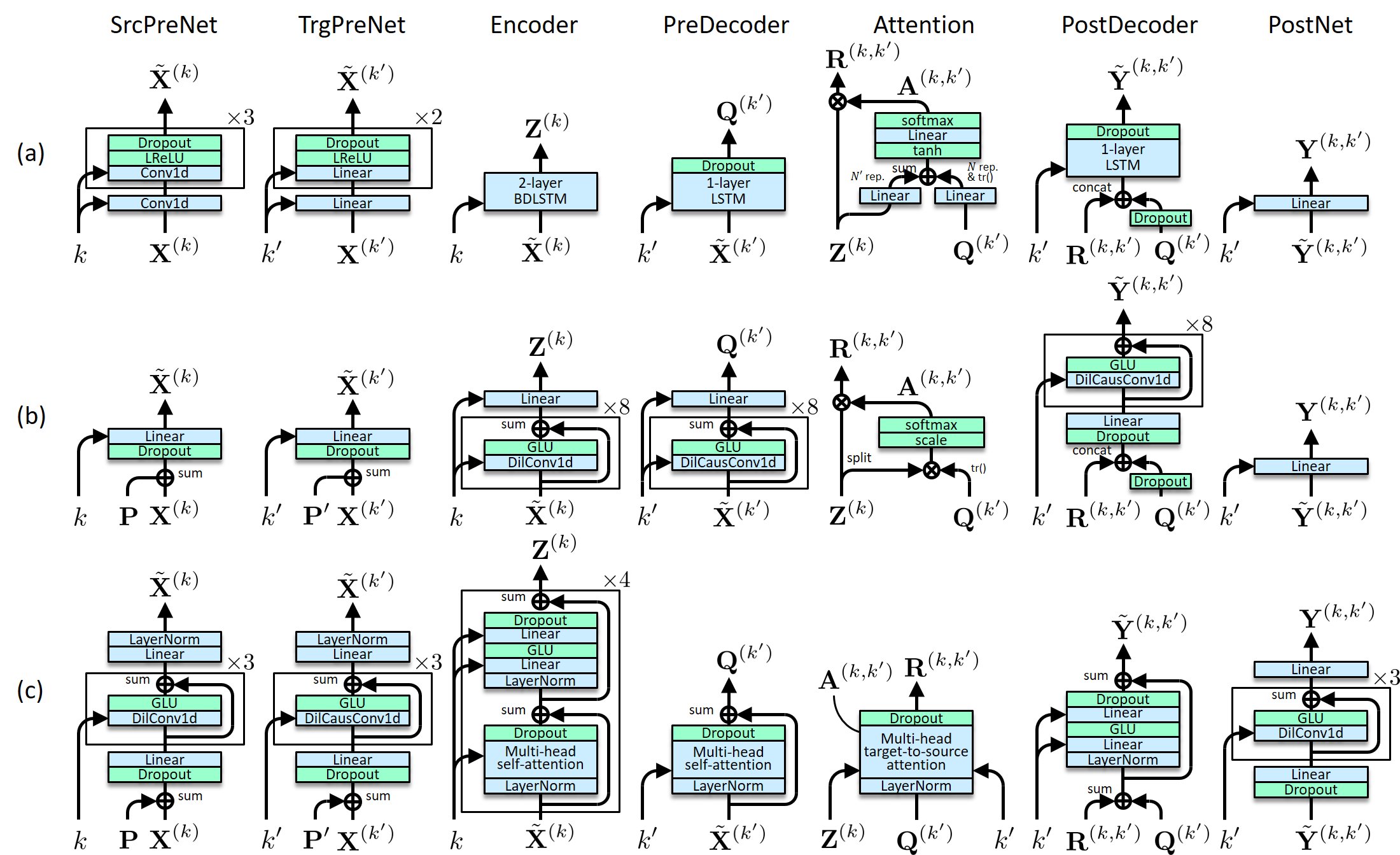 |
(Click to enlarge) |
(Click to enlarge) |
Links to related pages
Please also refer to the following web sites.
Audio examples
Speaker identity conversion
Here are audio examples of speaker identity conversion using the CMU Arctic database [7], which consists of 1132 phonetically balanced English utterances spoken by two female speakers ("clb" and "slt") and two male speakers ("bdl" and "rms"). The audio files for each speaker were manually divided into sets of 1000 and 132 files, and the first set was provided as the training set for the S2S model and Parallel WaveGAN. "Conv", "RNN", and "Trans" stand for the convolutional, recurrent, and Transformer architectures, respectively. "raw", "fwd", and "diag" refer to the modes in which the attention matrix is processed during mel-spectrogram conversion, i.e., using the raw predicted attention matrix, applying attention windowing to the predicted attention matrix so that the attention distribution peak is ensured to move forward, and forcing the attention matrix to be an identity matrix, respectively. In the 'diag' mode, the speaking rate and rhythm of the converted speech become exactly the same as those of the input speech.
|
Change sentence (current: #b0408) |
|||||||||||
| Input | Target | Conv | RNN | Trans | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| raw | fwd | diag | raw | fwd | diag | raw | fwd | diag | |||
| clb |
bdl | ||||||||||
| slt | |||||||||||
| rms | |||||||||||
| bdl |
clb | ||||||||||
| slt | |||||||||||
| rms | |||||||||||
| slt |
clb | ||||||||||
| bdl | |||||||||||
| rms | |||||||||||
| rms |
clb | ||||||||||
| bdl | |||||||||||
| slt | |||||||||||
Emotional expression conversion
Here are audio examples of voice emotional expression conversion. All the training and test data used for this demo consisted of Japanese utterances spoken by one female speaker with neutral (ntl), angry (ang), sad (sad) and happy (hap) expressions.
|
Change sentence (current: #001) |
|||||||||||
| Input | Target | Conv | RNN | Trans | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| raw | fwd | diag | raw | fwd | diag | raw | fwd | diag | |||
| ntl |
ang | ||||||||||
| sad | |||||||||||
| hap | |||||||||||
| ang |
ntl | ||||||||||
| sad | |||||||||||
| hap | |||||||||||
| sad |
ntl | ||||||||||
| ang | |||||||||||
| hap | |||||||||||
| hap |
ntl | ||||||||||
| ang | |||||||||||
| sad | |||||||||||
Electrolaryngeal speech enhancement
Here are some audio examples of electrolaryngeal-to-normal speech conversion. Electrolaryngeal (EL) speech is a method of voice restoration using electrolarynx, which is a battery-operated machine that produces sound to create a voice. The aim of this task is to improve perceived naturalness of EL speech by converting it into a normal version. Since EL speech usually has a flat pitch contour, the challenge is how to predict natural intonation from it. Audio examples are provided below. Note that "fkn", "fks", "mho", and "mht" represent the speaker labels of normal speech.
|
Change sentence (current: #J01) |
|||||||||||
| Input | Target | Conv | RNN | Trans | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| raw | fwd | diag | raw | fwd | diag | raw | fwd | diag | |||
| EL speech |
fkn | ||||||||||
| fks | |||||||||||
| mho | |||||||||||
| mht | |||||||||||
Whisper-to-Natural Speech Conversion
Here are some audio examples of whisper-to-normal speech conversion. Whispered speech can be useful in quiet, private online communication, where the speaker does not want his or her voice to be heard by nearby listeners, but it suffers from lower intelligibility than normal speech. The aim of this task is to convert whispered speech into a normal version so that it becomes easier to hear. Similar to the EL-to-natural speech conversion task, input speech does not contain pitch information. Hence, the challenge is again how to predict natural intonation from unpitched speech. Audio examples are provided below.
|
Change sentence (current: #j01) |
|||||||||||
| Input | Target | Conv | RNN | Trans | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| raw | fwd | diag | raw | fwd | diag | raw | fwd | diag | |||
| whisper | normal | ||||||||||
References
[1] H. Kameoka, K. Tanaka, and T. Kaneko, "FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion," arXiv:2104.06900 [cs.SD], 2021.
[2] H. Kameoka, K. Tanaka, D. Kwasny, T. Kaneko, and N. Hojo, "ConvS2S-VC: Fully Convolutional Sequence-to-Sequence Voice Conversion," IEEE/ACM Trans. ASLP, vol. 28, pp. 1849-1863, Jun. 2020.
[3] K. Tanaka, H. Kameoka, T. Kaneko, and N. Hojo, "AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms," in Proc. 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2019), pp. 6805-6809, May 2019.
[4] H. Kameoka, W.-C. Huang, K. Tanaka, T. Kaneko, N. Hojo, and T. Toda, "Many-to-Many Voice Transformer Network," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 656-670, 2021.
[5] R. Yamamoto, E. Song, and J. Kim, "Parallel Wavegan: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram," in Proc. ICASSP, 2020, pp. 6199-6203.
[6] https://github.com/kan-bayashi/ParallelWaveGAN
[7] J. Kominek and A. W. Black, "The CMU Arctic speech databases," in Proc. SSW, 2004, pp. 223–224.