Papers
- Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, Nobukatsu Hojo, and Shogo Seki, "VoiceGrad: Non-Parallel Any-to-Many Voice Conversion with Annealed Langevin Dynamics," arXiv:2010.02977 [cs.SD], Oct. 2020.
VoiceGrad
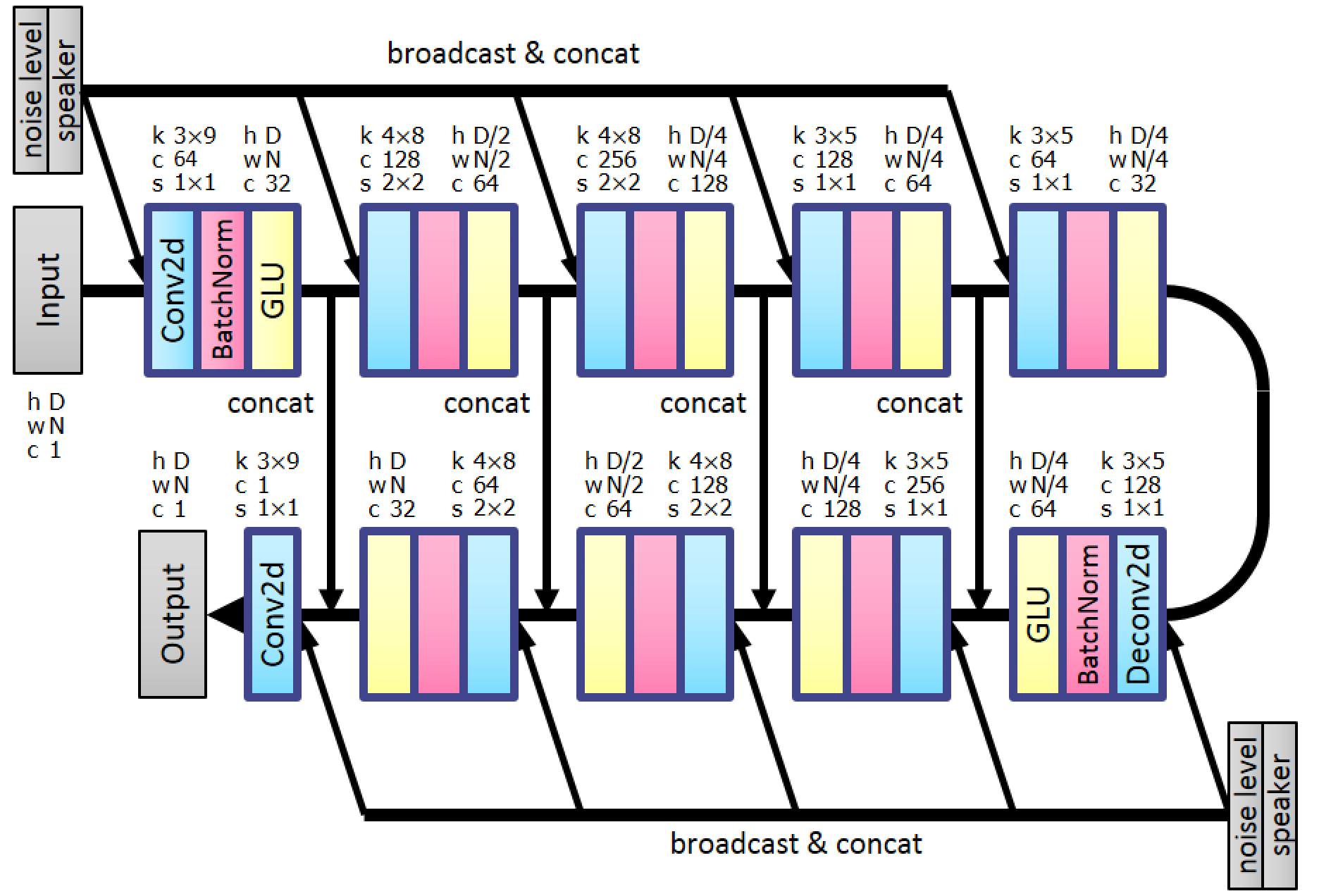
VoiceGrad is a voice conversion method based upon the concepts of denoising score matching and annealed Langevin dynamics [1]. As the name implies, it was inspired by WaveGrad [2], a recently introduced novel waveform generation method. VoiceGrad uses weighted denoising score matching to train a score approximator, a fully convolutional network with a U-Net structure designed to predict the gradient of the log density of the speech feature sequences of multiple speakers, and performs VC by using annealed Langevin dynamics to iteratively update an input feature sequence towards the nearest stationary point of the target distribution based on the trained score approximator network. The current version uses mel-cepstral coefficients (MCCs) extracted from a spectral envelope computed every 8 ms using WORLD [3] as the acoustic feature vector to be converted.
Links to related pages
Please also refer to the following web sites for comparison.
- Version 2 of VoiceGrad (applied to mel-spectrograms)
- Links to my other work
Audio examples
Here are some audio examples of VoiceGrad tested on a speaker identity conversion task in closed-set and open-set scenarios. We used the CMU ARCTIC database [4], which consisted of recordings of 18 speakers each reading the same 1,132 phonetically balanced English sentences. For the training and test sets for a closed-set scenario, we used the utterances of two female speakers, clb and slt, and two male speakers, bdl and rms. We also used the utterances of a male speaker, jmk, and a female speaker, lnh, as the test set for an open-set scenario. For each speaker, we used the last 32 sentences for the test set. To simulate a non-parallel training scenario, we divided the first 1,000 sentences equally into four groups and used the first, second, third, and fourth groups for training for speakers clb, bdl, slt, and rms, respectively, so as not to use the same sentences between different speakers. The training utterances of speakers clb, bdl, slt, and rms were about 12, 11,11, and 14 minutes long in total, respectively. All the signals were sampled at 16 kHz.
Audio examples obtained with VoiceGrad are demonstrated below, along with those obtained with StarGAN-VC [5][6] for comparison. For StarGAN-VC, we tested two versions with different training objectives, one using the cross-entropy loss [5] and the other using the Wasserstein distance and gradient penalty loss [6]. The abbreviations StarGAN-VC(C) and StarGAN-VC(W) are used to indicate the former and latter versions, respectively. For waveform generation, the WaveNet [7][8][9] and WORLD [3] vocoders were used for all these methods. The WaveNet vocoder used was a speaker-independent model [8][9], trained using the utterances corresponding to the first 1028 sentences of 6 speakers in the same database (including clb, bdl, slt, and rms).
Closed-set condition
| Input | Target | Converted | |||||
| VoiceGrad | StarGAN-VC(C) | StarGAN-VC(W) | |||||
| WaveNet | WORLD | WaveNet | WORLD | WaveNet | WORLD | ||
| clb | slt | ||||||
| slt | clb | ||||||
| bdl | rms | ||||||
| rms | bdl | ||||||
| bdl | slt | ||||||
| clb | rms | ||||||
Open-set condition
| Input | Target | Converted | |||||
| VoiceGrad | StarGAN-VC(C) | StarGAN-VC(W) | |||||
| WaveNet | WORLD | WaveNet | WORLD | WaveNet | WORLD | ||
| lnh | slt | ||||||
| jmk | rms | ||||||
| lnh | bdl | ||||||
References
[1] Y. Song and S. Ermon, "Generative modeling by estimating gradientsof the data distribution," in Adv. Neural Information Processing Systems (NeurIPS), 2019, pp. 11918–11930.
[2] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan, "WaveGrad: Estimating gradients for waveform generation," arXiv:2009.00713 [eess.AS], 2020.
[3] M. Morise, F. Yokomori, and K. Ozawa, "WORLD: A vocoder-basedhigh-quality speech synthesis system for real-time applications," IEICE Transactions on Information and Systems, vol. E99-D, no. 7, pp. 1877–1884, 2016.
[4] J. Kominek and A. W. Black, "The CMU Arctic speech databases," in Proc. ISCA Speech Synthesis Workshop (SSW), 2004, pp. 223–224
[5] H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, "StarGAN-VC: Non-parallel many-to-many voice conversion using star generative adversarial networks," in Proc. 2018 IEEE Workshop on Spoken Language Technology (SLT 2018), pp. 266-273, Dec. 2018.
[6] H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, "Non-parallel voice conversion with augmented classifier star generative adversarial networks," arXiv:2008.12604 [eess.AS], Aug 2020.
[7] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, "WaveNet: A generative model for raw audio," arXiv:1609.03499 [cs.SD], 2016.
[8] https://github.com/kan-bayashi/PytorchWaveNetVocoder
[9] T. Hayashi, A. Tamamori, K. Kobayashi, K. Takeda, and T. Toda, "An investigation of multi-speaker training for WaveNet vocoder," in Proc. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 712-718, 2017.