Papers
- Hirokazu Kameoka, Kou Tanaka, and Takuhiro Kaneko, "FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion," arXiv:2104.06900 [cs.SD], 2021. (PDF)
- Hirokazu Kameoka, Wen-Chin Huang, Kou Tanaka, Takuhiro Kaneko, Nobukatsu Hojo, and Tomoki Toda, "Many-to-Many Voice Transformer Network," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 656-670, 2021. (IEEE Xplore)
Transformer-VC2 (or VTN2 for short)
Transformer-VC2 is an upgraded version of Transformer-VC (also called Voice Transformer Network) [1]. While the original Transformer-VC learns to map one sequence of mel-cepstrum vocoder parameters to another, Transformer-VC2 learns to map one mel-spectrogram to another, and uses Parallel WaveGAN [2][3] to generate a waveform from the converted mel-spectrogram.
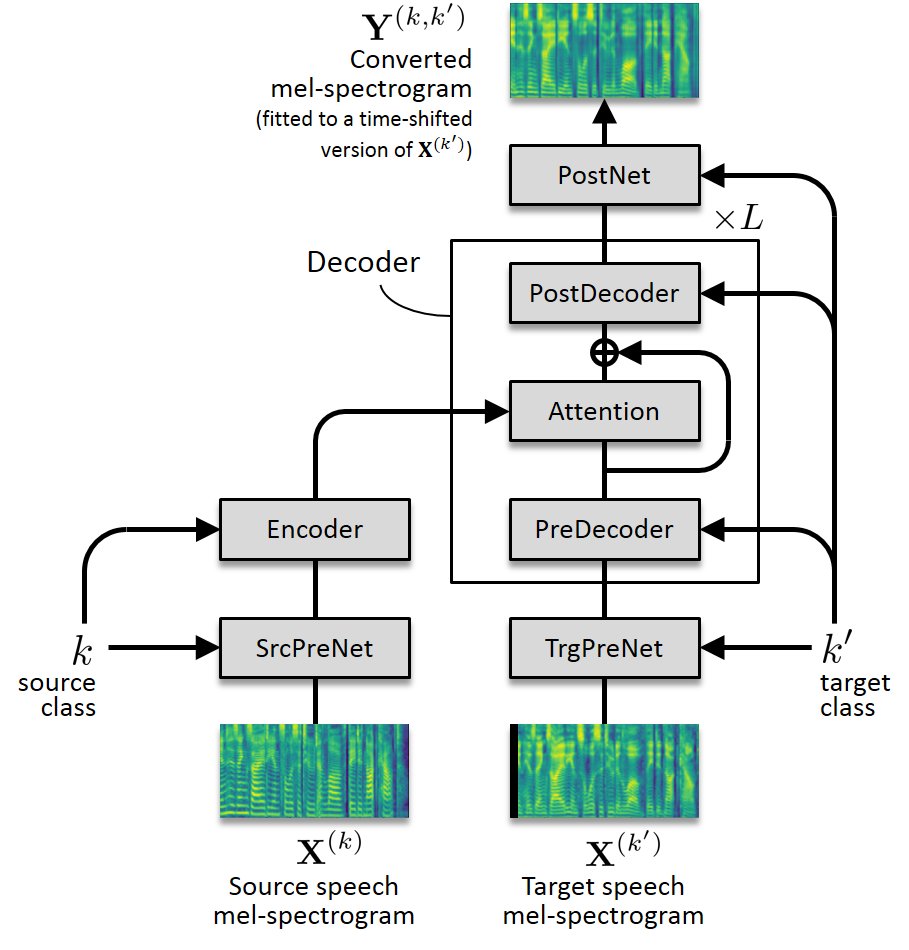 |
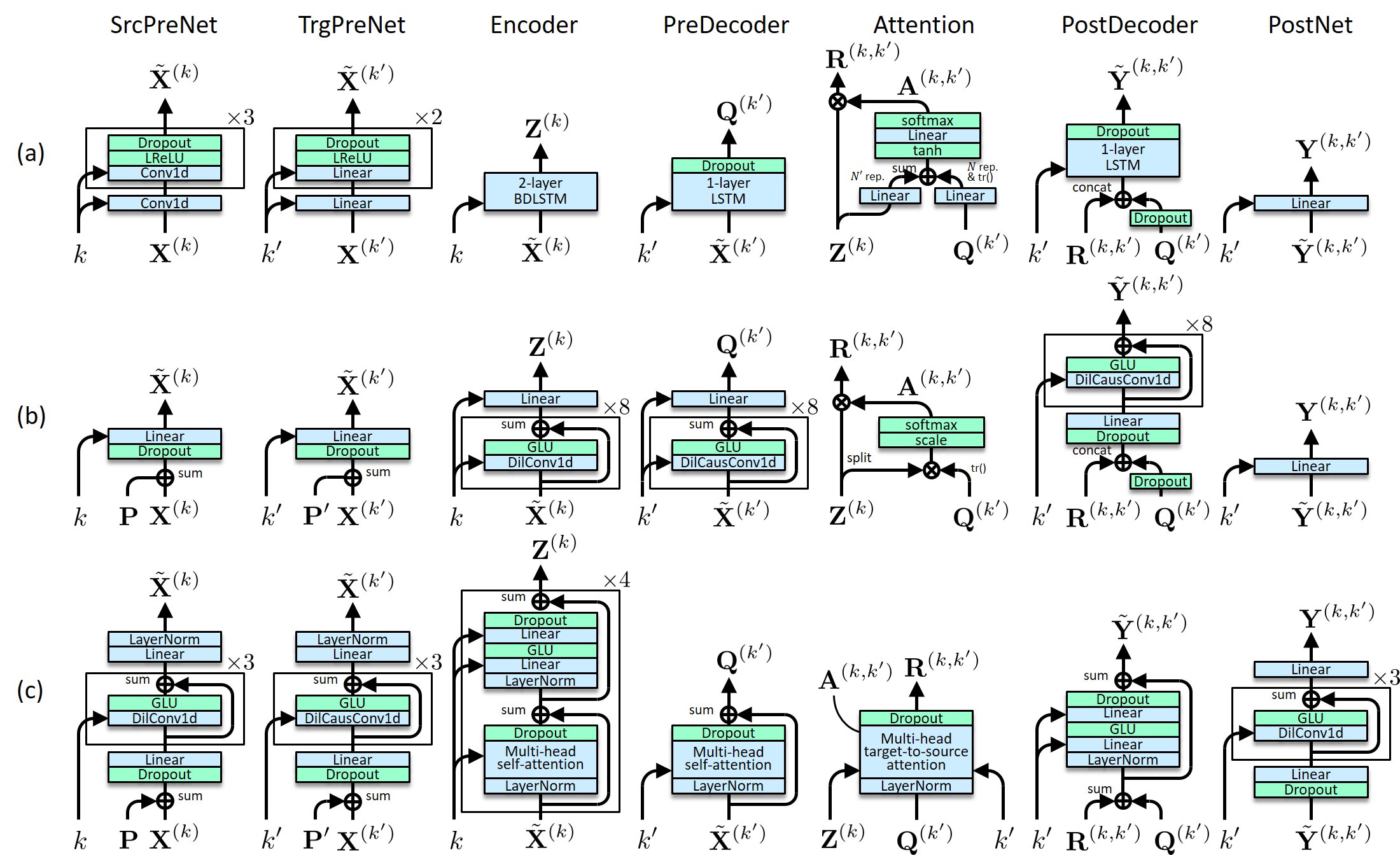 |
Links to related pages
Please also refer to the following web sites for comparison.
Audio examples
Speaker identity conversion
Here are some audio examples of speaker identity conversion. In this experiment, we used the CMU Arctic database [4], which consists of 1132 phonetically balanced English utterances spoken by four US English speakers. We selected "clb" (female) and "rms" (male) as the source speakers and "slt" (female) and "bdl" (male) as the target speakers. The audio files for each speaker were manually divided into 1000 and 132 files, and the first 1000 files were provided as the training set for Transformer and Parallel WaveGAN training. Audio examples obtained with Transformer-VC2, Transformer-VC [1], and the open-source VC system called "sprocket" [5] are demonstrated below.
| Transformer-VC2 | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
| Transformer-VC [1] | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
| sprocket [2] | Converted to ... | |||||
| clb | bdl | slt | rms | |||
| Input | clb | — | ||||
| bdl | — | |||||
| slt | — | |||||
| rms | — | |||||
Emotional expression conversion
Here are some audio examples of voice emotional expression conversion. All the training and test data used in this experiment consisted of Japanese utterances spoken by one female speaker with neutral (ntl), angry (ang), sad (sad) and happy (hap) expressions. Audio examples obtained with Transformer-VC2, Transformer-VC [1], and sprocket [5] are provided below.
| Transformer-VC2 | Converted to ... | |||||
| ntl | ang | sad | hap | |||
| Input | ntl | — | ||||
| ang | — | |||||
| sad | — | |||||
| hap | — | |||||
| Transformer-VC [1] | Converted to ... | |||||
| ntl | ang | sad | hap | |||
| Input | ntl | — | ||||
| ang | — | |||||
| sad | — | |||||
| hap | — | |||||
| sprocket [5] | Converted to ... | |||||
| ntl | ang | sad | hap | |||
| Input | ntl | — | ||||
| ang | — | |||||
| sad | — | |||||
| hap | — | |||||
References
[1] H. Kameoka, W.-C. Huang, K. Tanaka, T. Kaneko, N. Hojo, and T. Toda, "Many-to-Many Voice Transformer Network," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 656-670, 2021.
[2] R. Yamamoto, E. Song, and J. Kim, "Parallel Wavegan: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram," in Proc. ICASSP, 2020, pp. 6199-6203.
[3] https://github.com/kan-bayashi/ParallelWaveGAN
[4] J. Kominek and A. W. Black, "The CMU Arctic speech databases," in Proc. SSW, 2004, pp. 223–224.
[5] K. Kobayashi and T. Toda, "sprocket: Open-source voice conversion software," in Proc. Odyssey, 2018, pp. 203–210.