 )
) kameoka.hirokazu(at)lab.ntt.co.jp / kameoka(at)hil.t.u-tokyo.ac.jp
kameoka.hirokazu(at)lab.ntt.co.jp / kameoka(at)hil.t.u-tokyo.ac.jp +81-46-240-3645 / +81-3-5841-6901
+81-46-240-3645 / +81-3-5841-6901
Multichannel acoustic scene analysis
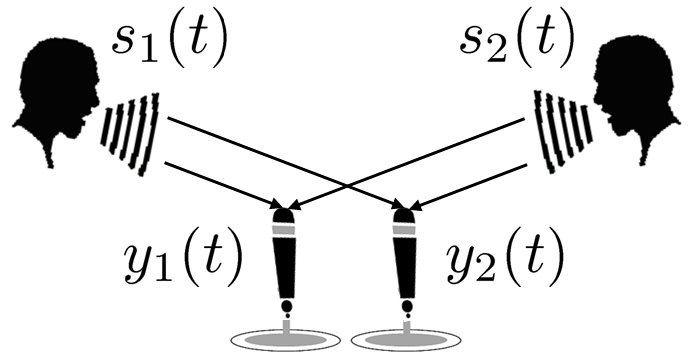
Humans are able to recognize what kinds of sounds are present and which direction they are emanating from by using their ears. The goal of acoustic scene analysis is to develop a method that let machines imitate this kind of human auditory function. Audio source separation, audio event detection, source localization, and dereverberation are major subproblems to be solved. Since each of these problems is ill-posed, some assumptions are usually required. For example, many methods for source separation assume anechoic environments, many methods for audio event detection assume that no more than one audio event can occur at a time, and many methods for source localization and dereverberation assume that only one source is present. All these algorithms work well when certain assumed conditions are met but, nevertheless, have their limitations when applied to general cases. By focusing on the fact that the solution to one of these problems can help solve the other problems, we proposed a unified approach for solving these problems through a joint optimization problem formulation.
- Takuya Higuchi, Hirokazu Kameoka, "Unified approach for underdetermined BSS, VAD, dereverberation and DOA estimation with multichannel factorial HMM," in Proc. of The 2nd IEEE Global Conference on Signal and Information Processing (GlobalSIP 2014), Dec. 2014.
- Takuya Higuchi, Hirokazu Kameoka, "Joint audio source separation and dereverberation based on multichannel factorial hidden Markov model," in Proc. The 24th IEEE International Workshop on Machine Learning for Signal Processing (MLSP 2014), Sep. 2014.
- Takuya Higuchi, Hirofumi Takeda, Tomohiko Nakamura, Hirokazu Kameoka, "A unified approach for underdetermined blind signal separation and source activity detection by multichannel factorial hidden Markov models," in Proc. The 15th Annual Conference of the International Speech Communication Association (Interspeech 2014), pp. 850-854, Sep. 2014. (PDF)
Speech prosody analysis, synthesis and conversion
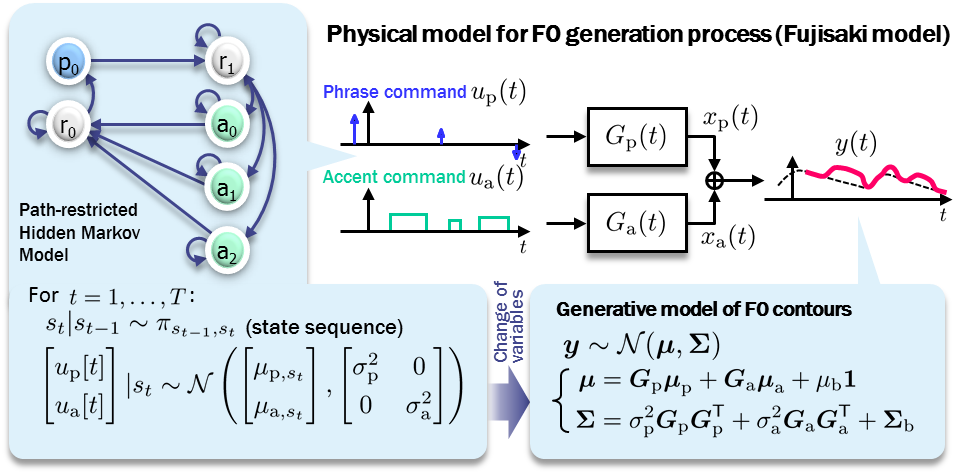
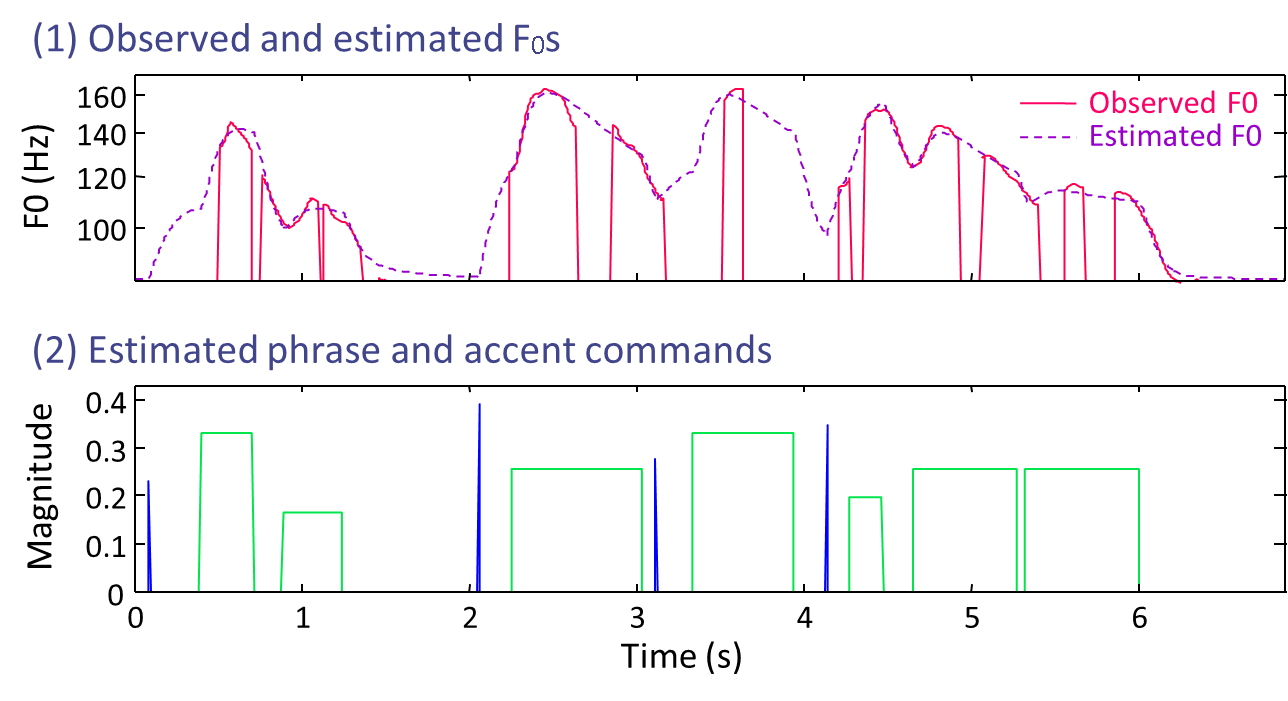
Speech consists of two major factors: phoneme and prosody. While the former is used to represent linguistic information, the latter plays an important role in conveying various types of non-linguistic information such as the identity, intention, attitude and mood of the speaker.
Linear Predictive Coding (LPC), proposed in the 1960s, has established the modern speech analysis/synthesis framework and has opened the door of the mobile phone technology and the research paradigm of statistical-model-based speech information processing. While LPC has realized the analysis/synthesis framework focusing on the 'phonemic' factor of speech, we developed a new analysis/synthesis framework focusing on the 'prosodic' factor. Although a well-founded physical model for vocal fold vibration was proposed in the 1960s by Fujisaki (known as the "Fujisaki model"), how to estimate the underlying parameters has long been a difficult task. We developed a stochastic counterpart of the Fujisaki model described by a discrete-time stochastic process, which has made it possible to apply powerful statistical inference techniques to accurately estimate the underlying parameters. This formulation is also noteworthy in that it has provided an automatically trainable version of the Fujisaki model, which allows it to be smoothly incorporated into a new module for Text-to-Speech, speech analysis, synthesis and conversion systems under a unified statistical framework.
- Hirokazu Kameoka, Kota Yoshizato, Tatsuma Ishihara, Kento Kadowaki, Yasunori Ohishi, and Kunio Kashino, "Generative modeling of voice fundamental frequency contours," IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 23, no. 6, pp. 1042-1053, Jun. 2015. (PDF)
- Hirokazu Kameoka, "Probabilistic modeling of pitch contours towards prosody synthesis and conversion," in Speech Prosody in Speech Synthesis: Modeling and generation of prosody for high quality and flexible speech synthesis, K. Hirose, J. Tao (eds.), Springer-Verlag Berlin Heidelberg, 2015.
- Hirokazu Kameoka, Kota Yoshizato, Tatsuma Ishihara, Yasunori Ohishi, Kunio Kashino, Shigeki Sagayama, "Generative modeling of speech F0 contours," in Proc. The 14th Annual Conference of the International Speech Communication Association (Interspeech 2013), pp. 1826-1830, Aug. 2013. (PDF) (Poster)
- Tatsuma Ishihara, Hirokazu Kameoka, Kota Yoshizato, Daisuke Saito, Shigeki Sagayama, "Probabilistic speech F0 contour model incorporating statistical vocabulary model of phrase-accent command sequence," in Proc. The 14th Annual Conference of the International Speech Communication Association (Interspeech 2013), pp. 1017-1021, Aug. 2013. (PDF)
- Kota Yoshizato, Hirokazu Kameoka, Daisuke Saito, Shigeki Sagayama, "Hidden Markov convolutive mixture model for pitch contour analysis of speech," in Proc. The 13th Annual Conference of the International Speech Communication Association (Interspeech 2012), Mon.O2d.06, Sep. 2012. (PDF) 〈Selected as a finalist of the Best Student Paper Award〉
- Hirokazu Kameoka, Jonathan Le Roux, Yasunori Ohishi, "A statistical model of speech F0 contours," ISCA Tutorial and Research Workshop on Statistical And Perceptual Audition (SAPA 2010), pp. 43-48, Sep. 2010. (PDF)
Optimization with auxiliary function approach
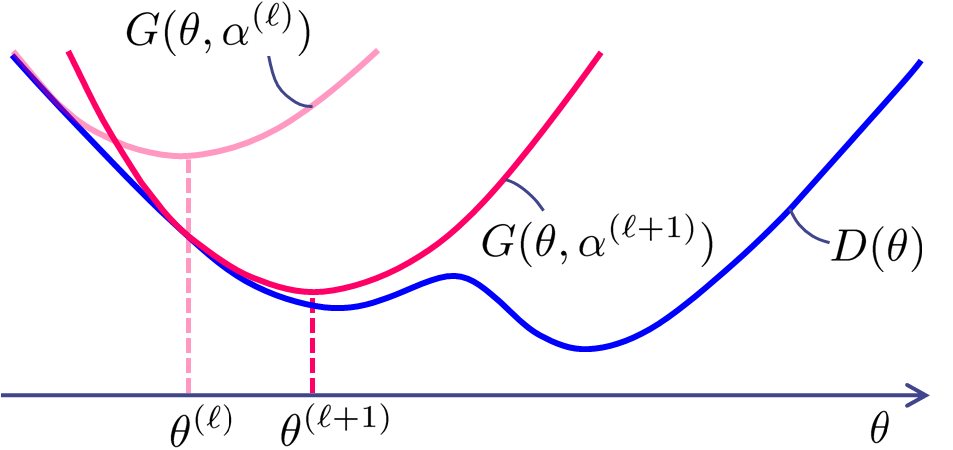
For many nonlinear optimization problems, parameter estimation algorithms using auxiliary functions have proven to be very effective. The general principle is called the "auxiliary function approach" (also known as the "Majorization-Minimization approach"). This concept is adopted in many existing algorithms (For example, the expectation-maximization (EM) algorithm can be seen as a special case of this approach). In general, if we can build an easy-to-optimize auxiliary function that tightly bounds the objective function of a certain optimization problem from above or below, we obtain a well-behaved and fast-converging algorithm. We have thus far proposed deriving parameter estimation algorithms based on this approach for various optimization problems, many of which have been shown to be significantly faster than gradient-based methods. Some examples are as follows.
- Training Restricted Boltzmann Machines: Restricted Boltzmann Machines (RBMs) are neural network models for unsupervised learning, which can also be used as feature extractors for supervised learning algorithms. RBMs have received a lot of attention recently after being proposed as building blocks for deep belief networks. The success of these models raises the issue of how best to train them. At present, the most popular training algorithm for RBMs is the Contrastive Divergence (CD) learning algorithm. We proposed a new training algorithm for RBMs based on an auxiliary function approach. Through parameter training experiments, we confirmed that the proposed algorithm converged faster and to a better solution than the CD algorithm.
- Hirokazu Kameoka, Norihiro Takamune, "Training restricted Boltzmann machines with auxiliary function approach," in Proc. The 24th IEEE International Workshop on Machine Learning for Signal Processing (MLSP2014), Sep. 2014. (PDF)
- Norihiro Takamune, Hirokazu Kameoka, "Maximum reconstruction probability training of restricted Boltzmann machines with auxiliary function approach," in Proc. The 24th IEEE International Workshop on Machine Learning for Signal Processing (MLSP 2014), Sep. 2014. (PDF)
- NMF with the beta divergence criterion: Many commonly used divergence measures for non-negative matrix factorizaion (NMF) such as the Euclidean distance, I divergence (generalized Kullback-Leibler divergence) and Itakura-Saito divergence can be described in a unified manner using a criterion called the beta divergence. We proposed a generalized algorithm for NMF with the beta divergence criterion based on an auxiliary function approach. The convergence of the proposed algorithm is guaranteed for any beta.
- Masahiro Nakano, Hirokazu Kameoka, Jonathan Le Roux, Yu Kitano, Nobutaka Ono, Shigeki Sagayama, "Convergence-guaranteed multiplicative algorithms for non-negative matrix factorization with beta-divergence," in Proc. 2010 IEEE International Workshop on Machine Learning for Signal Processing (MLSP 2010), pp. 283-288, Aug. 2010. (PDF)
- ...: ...
Extensions of Non-negative Matrix Factorization for audio signal processing
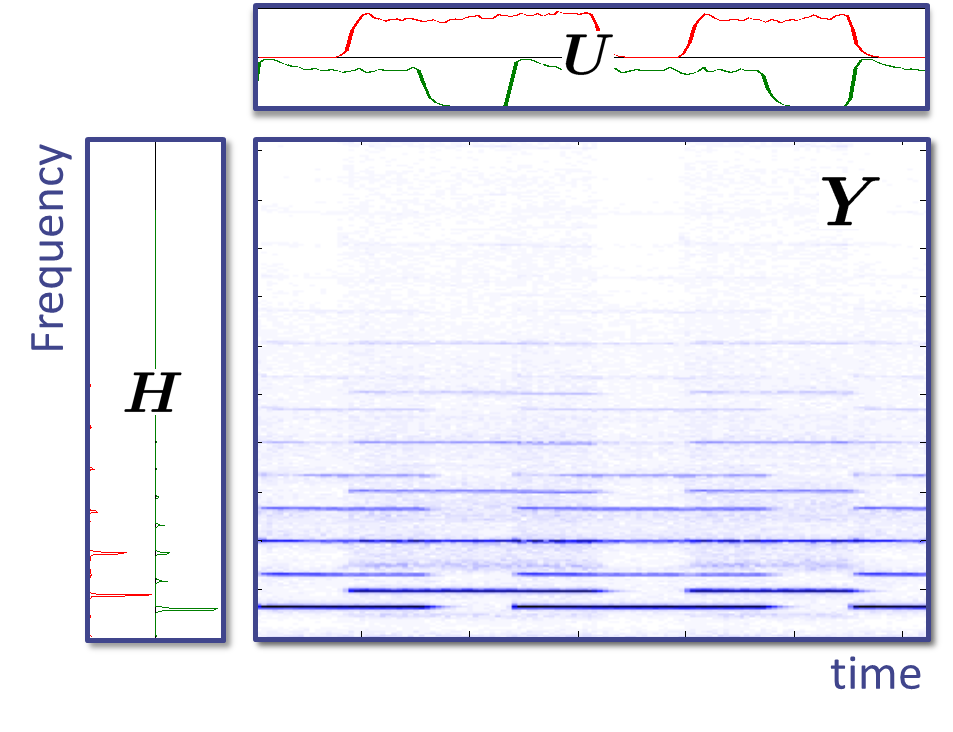
There are many kinds of real-world data given by non-negative values, such as power spectra, pixel values and count data. In a way similar to multivariate analysis techniques such as Principal Component Analysis (PCA) and Independent Component Analysis (ICA), decomposing non-negative data into the sum of underlying components can be useful in many situations. For example, if we can extract the power spectra of underlying sources in a mixture signal, they may be useful for noise reduction and source separation. A multivariate analysis technique enabling the decomposition of non-negative data into non-negative components is called Non-negative Matrix Factorization (NMF).
We developed a number of improved variants of NMF aiming to solve audio signal processing problems. Some examples are as follows.
- Phase-Aware NMF: We proposed a framework called "Complex NMF", which makes it possible to realize NMF-like signal decompositions in the complex spectrogram domain. To the best of our knowledge, this is among the first phase-aware NMF variant to be proposed. Recently, we further developed a time-domain extension of this approach. This extension is noteworthy in that it allows for a multi-resolution signal decomposition, which was not possible with the conventional NMF framework.
- Hirokazu Kameoka, "Multi-resolution signal decomposition with time-domain spectrogram factorization," in Proc. 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2015), pp. 86-90, Apr. 2015. (PDF)
- Hirokazu Kameoka, Nobutaka Ono, Kunio Kashino, Shigeki Sagayama, "Complex NMF: A New Sparse Representation for Acoustic Signals," in Proc. 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2009), pp. 3437-3440, Apr. 2009. (PDF) (Poster)
- Robust speech dereverberation: Many blind deconvolution algorithms fail to recover clean speech from its reverberated version when the room impulse response varies over time. While the room impulse response varies sensitively according to the movements of the speaker or the microphone, its power spectrogram is relatively less sensitive. By focusing on this fact, we proposed formulating a power-domain approach to blind dereverberation that works robustly against speaker's and microhone's movements. We successfully developed an efficient sparse non-negative deconvolution algorithm, inspired by the principle of the NMF algorithm.
- Hirokazu Kameoka, Tomohiro Nakatani, Takuya Yoshioka, "Robust Speech Dereverberation Based on Non-negativity and Sparse Nature of Speech Spectrograms," in Proc. 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2009), pp. 45-48, Apr. 2009. (PDF)
- Multichannel NMF: ...
- Source-Filter NMF: ...
- NMF with Time-Varying Basis Spectra: ...
- NMF with Cepstral Regularization:
- ...
Harmonic-Percussive Sound Separation
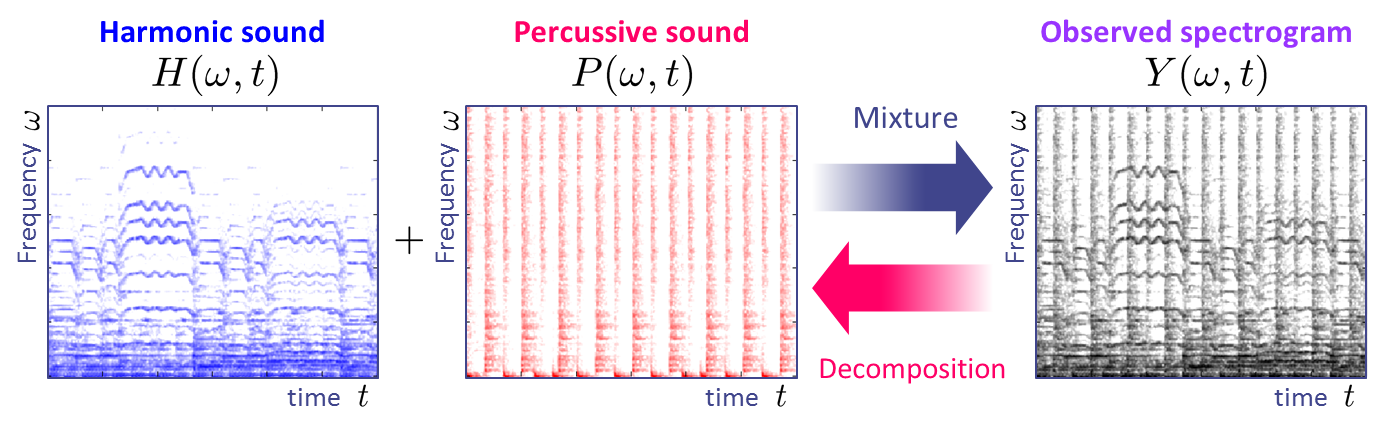
...
- Hideyuki Tachibana, Hirokazu Kameoka, Nobutaka Ono, Shigeki Sagayama, "Harmonic/Percussive sound separation based on anisotropic smoothness of spectrograms," IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 22, no. 12, pp. 2059-2073, 2015.
- Nobutaka Ono, Ken-ichi Miyamoto, Hirokazu Kameoka, Shigeki Sagayama, "A Real-time Equalizer of Harmonic and Percussive Components in Music Signals," in Proc. Ninth International Conference on Music Information Retrieval (ISMIR2008), pp. 139-144, Sep. 2008.
Multiple fundamental frequency estimation and automatic music transcription
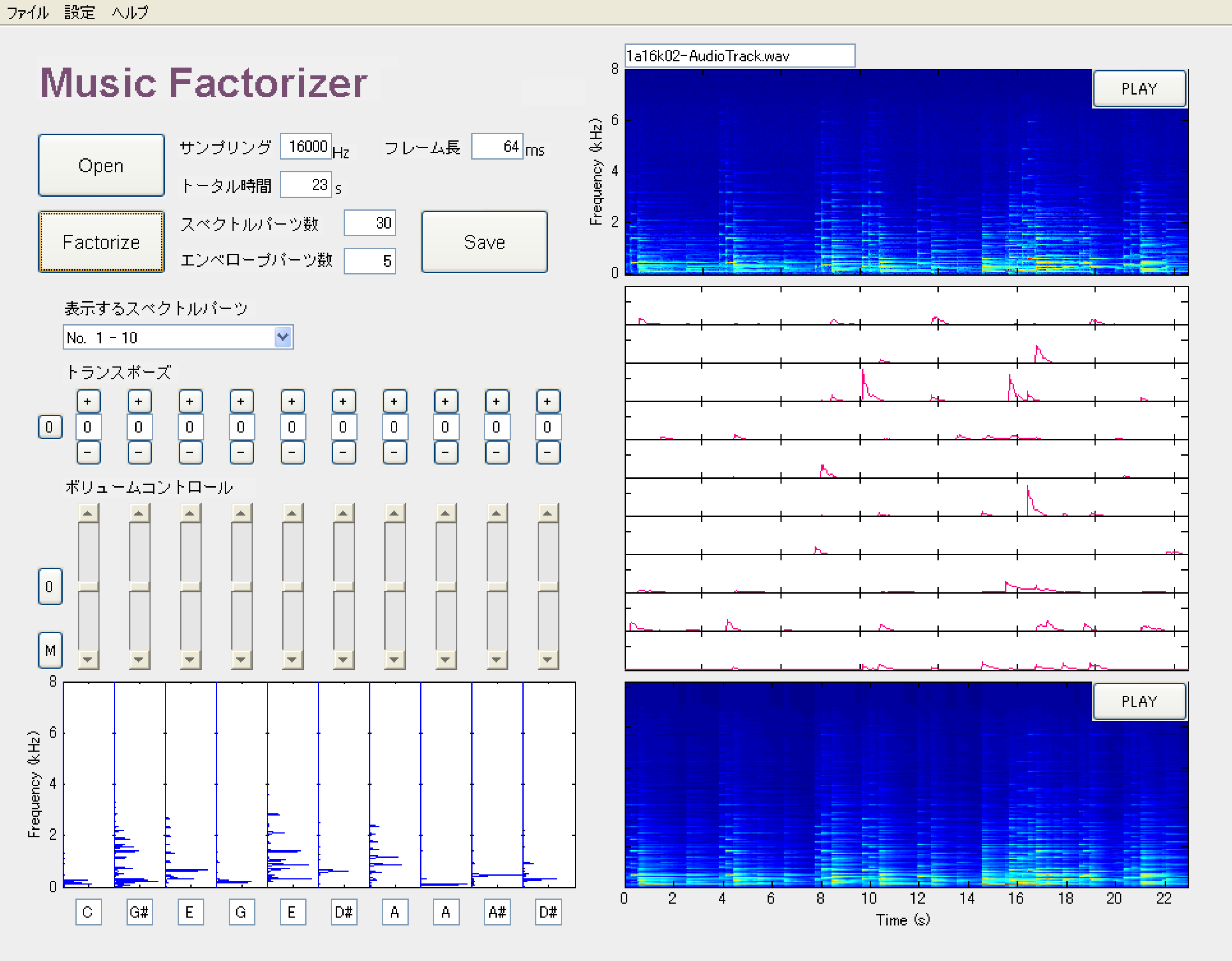
Humans are able to pay attention to a single melody line in polyphonic music. This ability is called the auditory stream segregation, which consists in grouping time-frequency elements into a perceptual unit called the auditory stream. We have proposed a novel computational algorithm imitating this auditory function by formulating the time-frequency structure of an auditory stream.
Similarly to speech recognition, music transcription is an important and challenging research topic. However, the performance of state-of-the-art techniques is still far from sufficient. A key to its solution is to build a top-down system, similar to speech recognition systems, that can hypothetically extract simultaneous notes and evaluate whether those extracted notes follow a musically likely score structure. We have proposed a new approach to music transcription based on a top-down system combining the abovementioned psycho-acoustically-motivated model with a language model for the musical score structure described by a 2 dimensional extension of the probabilistic context free grammar (PCFG).
- Hirokazu Kameoka, Takuya Nishimoto, Shigeki Sagayama, "A multipitch analyzer based on harmonic temporal structured clustering," IEEE Transactions on Audio, Speech and Language Processing, Vol. 15, No. 3, pp. 982-994, Mar. 2007. (PDF) 〈Itakura Prize〉 〈IEEE Signal Processing Society Japan Chapter Student Paper Award〉 〈IEEE Signal Processing Society 2008 SPS Young Author Best Paper Award〉
- Hirokazu Kameoka, Kazuki Ochiai, Masahiro Nakano, Masato Tsuchiya, Shigeki Sagayama, "Context-free 2D tree structure model of musical notes for Bayesian modeling of polyphonic spectrograms," in Proc. The 13th International Society for Music Information Retrieval Conference (ISMIR 2012), pp. 307-312, Oct. 2012. (PDF) (Poster)