



| Shiro Kumano, Yoichi Sato | Kazuhiro Otsuka, Junji Yamato, Eisaku Maeda | |
| (The University of Tokyo) | (NTT Communication Science Laboratories) |
| |
|
|
|
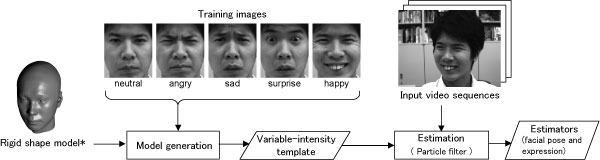
In this paper, we propose a method for poseinvariant facial expression recognition from monocular video sequences. The advantage of our method is that, unlike existing methods, our method uses a simple model, called the variable-intensity template, for describing different facial expressions. This makes it possible to prepare a model for each person with very little time and effort. Variableintensity templates describe how the intensities of multiple points, defined in the vicinity of facial parts, vary with different facial expressions. By using this model in the framework of a particle filter, our method is capable of estimating facial poses and expressions simultaneously. Experiments demonstrate the effectiveness of our method. A recognition rate of over 90% is achieved for all facial orientations, horizontal, vertical, and in-plane, in the range of ア40 degrees, ア20 degrees, and ア40 degrees from the frontal view, respectively.
* Degital Human Research Center, Advanced
Industrial Science and Technology.
Our method consists of two stages. First, we prepare a variable-intensity template
for each person from just one frontal face image for each facial expression.
Second, we estimate facial pose and expression simultaneously within the
framework of a particle filter.
Model Generation Process  mpeg1 mpeg1
|
Recognition  mpeg1 mpeg1
| |
Variable-Intensity Templates
The variable-intensity template is a novel simple face
model to simultaneously estimate facial pose and expression. It can be
easily generated as the following movie. It consists of three components.
(1) Rigid Shape Model
The rigid shape model provides the
depth coordinates of interest points defined on an image plane. The shape
model used is shown in the upper figure.
(3) Intensity
Distribution Model
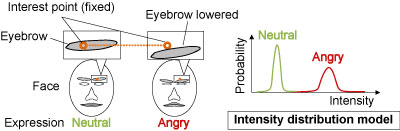
Intensity distribution model describes how the interest
point intensity varies for different facial expressions. As shown in the
figure, the interest point intensity changes strongly due to the shift of
its associated facial part. Focusing on this property, we recognize facial
expressions from the changes in observed interest point intensities.
(2) Interest Points 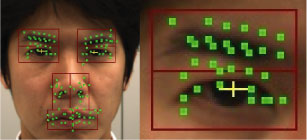
An interest point constitutes a pair of points that
straddle and are centered on the edge, to detect the bidirectional motions
of the facial parts.
| Fixed-pose dataset Horizontal mpeg1
|
Vertical mpeg1
|
In-plane mpeg1
| ||
| Free-pose dataset mpeg1
|
Journal Papers
[1] S. Kumano, K. Otsuka, J. Yamato, E. Maeda and Y.
Sato, "Pose-Invariant Facial Expression Recognition Using Variable-Intensity
Templates",
International Journal of Computer Vision,
Vol. 83, no. 2, pp.178-194, 2009.
[pdf]
Conferences
[1] S. Kumano, K. Otsuka, J. Yamato, E. Maeda and Y.
Sato, " Combining Stochastic and Deterministic Search. for Pose-Invariant Facial
Expression Recognition", British Machine Vision Conference (BMVC), 2008.
[2] S. Kumano, K. Otsuka, J. Yamato, E. Maeda and Y. Sato, "Pose-Invariant
Facial Expression Recognition Using Variable-Intensity Templates", Asian
Conference on Computer Vision (ACCV), Vol. I, pp.324-334, 2007. [Honorable mention Award]