Biography
Yasunori Ohishi is a senior manager, Head of Business Technology Development Section, Digial Design Department, Digital Transformation Headquaters in NTT EAST, Inc. His research interests include acoustic signal processing, multimedia content analysis, and music information retrieval.
Interests
- Acoustic signal processing
- Multimedia content analysis
- Music information retrieval
Education
-
PhD in Information Science, 2009
Nagoya University
-
MSc in Information Science, 2006
Nagoya University
-
BEng in Electrical and Electronic Engineering and Information Engineering, 2004
Nagoya University
Recent Posts

Skills
Acoustic signal processing
Expert
Multimedia content analysis
Expert
Music information retrieval
Expert
Machine learning
Advanced
Bayesian statistics and modeling
Advanced
Python
Advanced
Recent Publications
(2025).
Baseline Systems and Evaluation Metrics for Spatial Semantic Segmentation of Sound Scenes.
In EUSIPCO.
(2025).
CLAP-ART: Automated Audio Captioning with Semantic-rich Audio-Representation Tokenizer.
In Interspeech.
(2025).
Towards Pre-training an Effective Respiratory Audio Foundation Model.
In Interspeech.
Projects

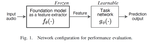
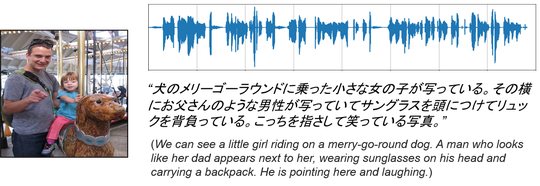
Japanese spoken captions for the Places205 image dataset
Experience
Senior Manager
Head of Business Technology Development Section, Digital Design Department, Digital Transformation Headquaters in NTT EAST, Inc.
Senior Research Scientist, Supervisor
Senior Manager
Head of Human Resources in NTT Communication Science Laboratories.
Senior Research Scientist
Leading basic researches on acoustic signal processing, crossmodal semantic learning, audio captioning, and sound event localization and detection. Presented in major international conferences such as ICASSP, Interspeech, and DCASE.
Assistant Manager
Administrative and clerical supports for researchers and budget managements in Media Information Laboratory and Moriya Research Laboratory.
Senior Research Scientist
Leading basic researches on crossmodal semantic learning and multimedia event detection.
Research Scientist
Leading basic researches on singing voice information processing and sound event detection. Presented in major international conferences such as ICASSP and Interspeech.
PhD Student
Research for analysis-synthesis model of singing voice that characterize varied singing behaviors and its practical applications.
BEng Student
Research for statistical analysis for the word hierarchy using an encyclopedic corpus.
Contact
- yasunori.ohishi.cy [at] east.ntt.co.jp
- 3-19-2 Nishi-shinjuku, Shinjuku, Tokyo 163-8019
- yasunoriohishi