A paper presented at Interspeech 2024
M2D-CLAP: Masked Modeling Duo Meets CLAP for Learning General-purpose Audio-Language Representation
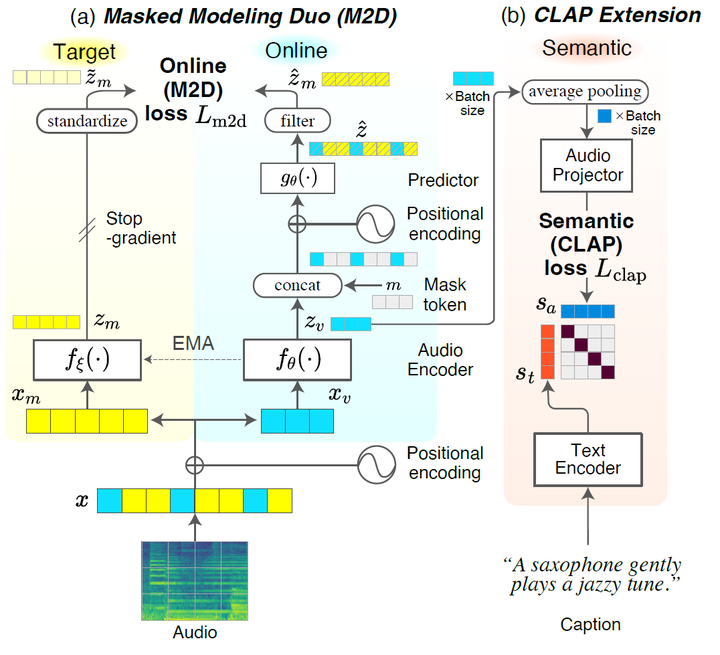
We are pleased to announce that our paper "M2D-CLAP: Masked Modeling Duo Meets CLAP for Learning General-purpose Audio-Language Representation" by Daisuke Niizumi, Daiki Takeuchi, Yasunori Ohishi, Noboru Harada, Masahiro Yasuda, Shunsuke Tsubaki, and Keisuke Imoto has been accepted to Interspeech 2024.
This paper proposes a new method, M2D-CLAP, which combines self-supervised learning Masked Modeling Duo (M2D) and CLAP. M2D learns an effective representation to model audio signals, and CLAP aligns the representation with text embedding. As a result, M2D-CLAP learns a versatile representation that allows for both zero-shot and transfer learning. Experiments show that M2D-CLAP performs well on linear evaluation, fine-tuning, and zero-shot classification with a GTZAN state-of-the-art of 75.17%, thus achieving a general-purpose audio-language representation.
Yasunori Ohishi
Senior Manager
My research interests include acoustic signal processing, crossmodal learning and music information retrieval.