Assessing the Utility of Audio Foundation Models for Heart and Respiratory Sound Analysis
Abstract
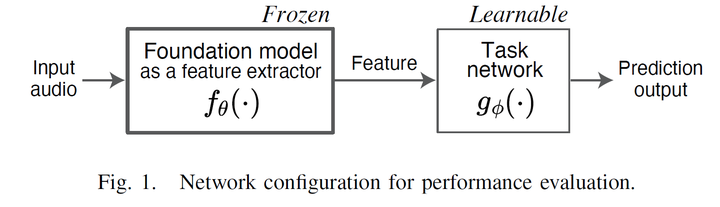
Pre-trained deep learning models, known as foundation models, have become essential building blocks in machine learning domains such as natural language processing and image domains. This trend has extended to respiratory and heart sound models, which have demonstrated effectiveness as off-the-shelf feature extractors. However, their evaluation benchmarking has been limited, resulting in incompatibility with state-of-the-art (SOTA) performance, thus hindering proof of their effectiveness. This study investigates the practical effectiveness of off-the-shelf audio foundation models by comparing their performance across four respiratory and heart sound tasks with SOTA fine-tuning results. Experiments show that models struggled on two tasks with noisy data but achieved SOTA performance on the other tasks with clean data. Moreover, general-purpose audio models outperformed a respiratory sound model, highlighting their broader applicability. With gained insights and the released code, we contribute to future research on developing and leveraging foundation models for respiratory and heart sounds.