
|
|
|
 |
雑音・残響の中で人の声を聞き取る |
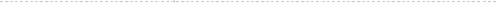 |
◆コンピュータを用いた音によるコミュニケーションシーンの分析 |
音声は、多くの人にとって、最も自然で使いやすいコミュニケーション手段の一つです。コンピュータが、私たちの生活環境(実環境)において音声を適切に収音し柔軟に処理することができれば、より快適で安心な音声サービスを提供できるようになると期待されます。しかし、実環境において、話者から離れたマイクロホンを用いて収音した音声には、背景雑音や残響が混ざってしまいます。これは、現在の音声サービスの性能を格段に低下させます。この問題を克服するため、私たちは、雑音や残響を含む音の中から、自動的に音声を特定(シーン分析)し、もとの音声の品質を回復(音声強調)する技術の研究をしています。そして音声強調の基盤技術を確立し、誰が・いつ・どのような部屋の・どこで・何を話したかといった人のコミュニケーションシーンの情報を自動的に抽出しつつ、各音声を適切に処理できる技術の実現を目指しています
|
■ 将来どのように使われるのか これまでは、背景雑音や残響の影響を極力少なくするために、接話型のマイクロホンが広く用いられてきました。しかし、マイクロホンに近づいて話さなければならないことは、状況によっては煩わしさを伴います。これに対し、コミュニケーションシーンを自動的に分析し、各音声を高い精度で抽出する技術を確立すれば、マイクロホンを意識しないで自由な場所から話すことができるようになります。さらにコンピュータによる音声認識と組み合わせることで、例えば、リモコン代わりに音声を使って家電製品をコントロールしたり、自由に動き回るロボットと自然にインタラクションしたりすることが可能となります。また会議の議事録を自動的に作成するシステムにおいて、各参加者に1つずつマイクホロンを用意する必要がなく、部屋やテーブル上などに自由にマイクロホンを設置できるようになります。さらに人と人との会話においても、雑音や残響を除去して音声の明瞭性を高めることは重要です。例えばテレビ会議や携帯電話への応用が考えられます。 |
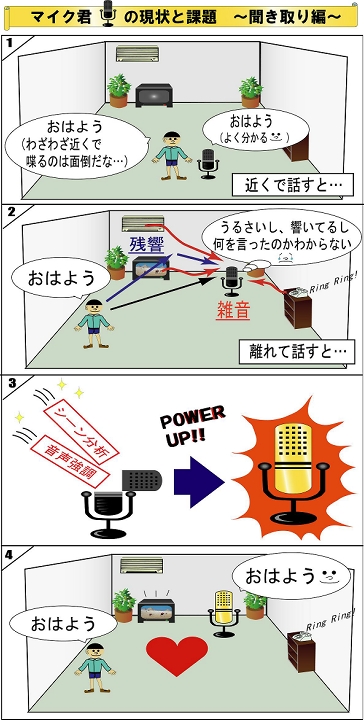 |
■ 会議シーンにおける話者インデキシング より快適な音声コミュニケーション環境構築のためには、コンピュータが周囲の音環境を自動で理解する技術が重要となります。そこで私たちは、会議などで複数の人が会話をしている中から「いつ誰が話したか?」を推定する、話者インデキシング技術の研究をすすめています。本技術は、収音したデータ中から「いつ発話されたのか?」を推定する音声区間検出技術と、「その音声はどの方向から発せられたのか?」を推定する音声到来方向推定技術を用いて実現されています。 |
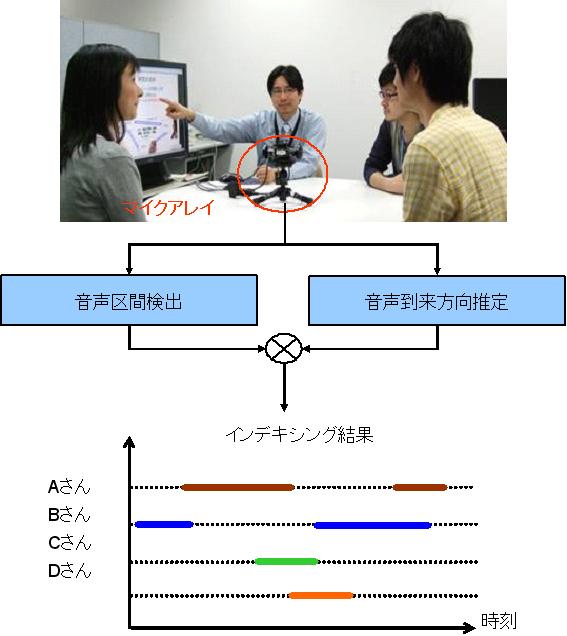 |
■ 音声らしさの学習に基づく音声強調 雑音除去や残響除去などの音声強調技術は、音声認識システムを日常の環境で使えるようにするためのキーテクノロジーです。従来から様々な音声強調方法が提案されてきましたが、その処理音声の性質は音声認識で用いられる音響モデル※と必ずしもマッチせず、高精度な音声認識に直結はしていませんでした。これに対し、私たちは、音声の確率モデルを用い、出力音声がより音声らしくなるように処理を制御しながら音声強調を行う方法を検討しています。 ※音素毎の周波数パターンを表した、音声の確率モデル |
 |
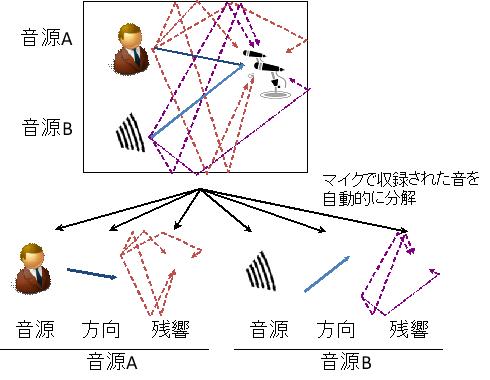
■ 音響信号処理の統一的基盤 私たちが普段聞く音は、別々の場所で生じている様々な音の集合です。私たちの研究グループでは、そのような複雑な音を、個々の音源から生じている音と空間中での音の伝わり方(音源の方向、残響)とに自動的に分解する技術を検討しています。この技術は、雑音除去、残響除去、音源方向推定などの色々な音響信号処理を統一的に行う基盤となります。私たちは、この理論基盤を構築するとともに、会議音声の収録のような現実的なシナリオにおいても、各話者の音声、残響、音源方向を同時に推定する方法を考案しています。 |
 |
【参考文献】 |
[1] 荒木,藤本,吉岡,堀,中谷, "複数人会話シーン分析におけるマイクロホン
アレイ音声処理", 電子情報通信学会 技術研究報告,vol. 111, no. 28, pp.
83-88, 2011年5月
|
[2] T. Yoshioka, T. Nakatani, M. Miyoshi, and H. G. Okuno,
"Blind separation and dereverberation of speech mixtures by joint
optimization," IEEE Transactions on Audio, Speech, and Language Processing,
vol. 19, no. 1, pp. 69-84, Jan. 2011.
|
[3] K. Kinoshita, M. Souden, M. Delcroix and T. Nakatani,
"Single channel dereverberation using example-based speech enhancement with
uncertainty decoding technique,'' Proc. of Interspeech2011 , pp.197-200, 2011.
|
[4] T. Nakatani, S. Araki, T. Yoshioka, M. Delcroix, and M. Fujimoto,
"Dominance Based Integration of Spatial and Spectral Features for Speech
Enhancement," IEEE Trans. ASLP., vol. 21, No. 12, pp.2516-2531, Dec. 2013.
|
[5] M. Souden, K. Kinoshita, M. Delcroix, and T. Nakatani,
"Location Feature Integration for Clustering-Based Speech Separation in
Distributed Microphone Arrays," IEEE Trans. ASLP, Vol. 22, no. 2, pp.
354-367, 2014.
|
[6] N. Ito, S. Araki, and T. Nakatani, "Probabilistic Integration of Diffuse
Noise Suppression and Dereverberation, " Proc. ICASSP, 2014.
|
[7] M. Fujimoto, Y. Kubo, and T. Nakatani, "Unsupervised non-parametric
Bayesian modeling of non-stationary noise for model-based noise
suppression," in Proc. ICASSP, 2014.
|
[8] A. Ogawa, K. Kinoshita, T. Hori, T. Nakatani and A. Nakamura,
"Fast segment search for corpus-based speech enhancement based on speech
recognition technology," in Proc. ICASSP, 2014.
|
[9] K. Kinoshita, M. Delcroix, T. Yoshioka, T. Nakatani, E. Habets, R.
Haeb-Umbach, V. Leutnant, A. Sehr, W. Kellermann, R. Maas, S. Gannot, B.
Raj, B, "The REVERB challenge: a common evaluation
framework for dereverberation and recognition of reverberant speech,"
in Proc. WASPAA, 2013.
|
[10] T. Yoshioka, A. Sehr, M. Delcroix, K. Kinoshita, R. Maas, T. Nakatani,
and W. Kellermann, "Making machines understand us in reverberant rooms:
robustness against reverberation for automatic speech recognition," IEEE
Signal Processing Magazine, vol. 29, no. 6, pp. 114-126, Nov. 2012.
|
|
Copyright (C) NTT Communication Science Laboratories |