どんな環境でも、聞きたい音を聞き分けるには
~確率的モデル統合に基づく音声強調~
概要
目的音を離れたマイクで収録すると、雑音や残響により、明瞭性や音声認識性能が低下します。そこで、雑音や残響を除去する音声強調技術が研究されてきました。しかし、従来技術は特定の環境でしか使えません。どんな環境でも使える音声強調技術の実現には、様々な環境のモデルを確率論的に統合する統一モデルの構築が必要です。本研究では、残響環境のモデルと拡散性雑音環境のモデルを統合した環境モデルを構築し、より広範囲の環境に適用可能な音声強調技術を実現しました。本研究により、家電の遠隔音声操作、居酒屋での音声検索など、どんな環境でも快適に音声サービスを利用できるようになります。
当日の様子



ポスター
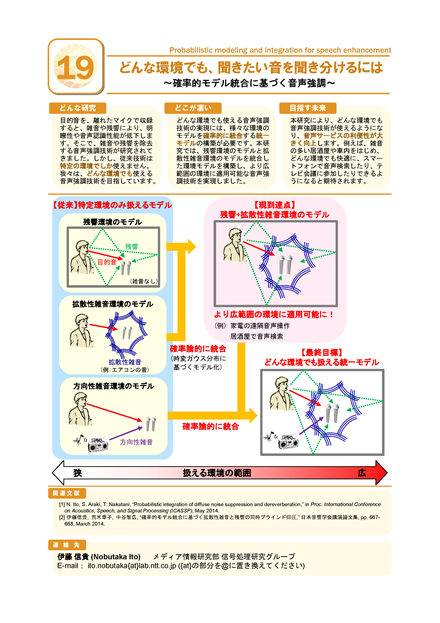
ポスターの画像をクリックすると、PDFファイルが開きます。
会場図