Check out our related work:
- iSTFTNet (ICASSP 2022): Fast and lightweight neural vocoder using iSTFT
- MISRNet (Interspeech 2022): Lightweight neural vocoder using multi-input single shared residual blocks
- WaveUNetD (ICASSP 2023): Fast and lightweight discriminator using Wave-U-Net
- AugCondD (ICASSP 2024): Augmentation-conditional discriminator for limited data
Abstract
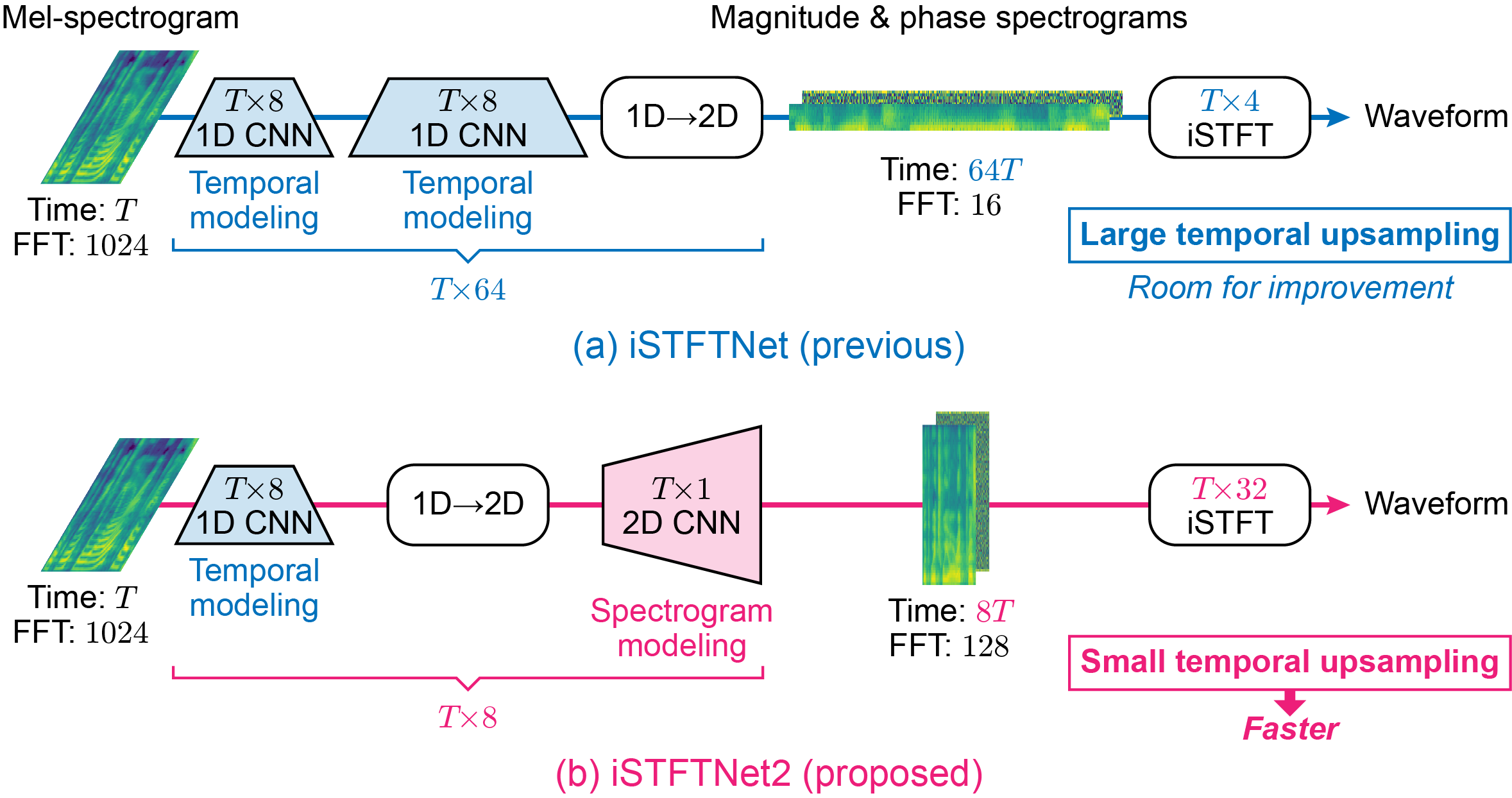
The inverse short-time Fourier transform network (iSTFTNet) [1] has garnered attention owing to its fast, lightweight, and high-fidelity speech synthesis. It obtains these characteristics using a fast and lightweight 1D CNN (e.g., HiFi-GAN [2]) as the backbone and replacing some neural processes with iSTFT. Owing to the difficulty of a 1D CNN to model high-dimensional spectrograms, the frequency dimension is reduced via temporal upsampling. However, this strategy compromises the potential to enhance the speed. Therefore, we propose iSTFTNet2, an improved variant of iSTFTNet with a 1D-2D CNN that employs 1D and 2D CNNs to model temporal and spectrogram structures, respectively. We designed a 2D CNN that performs frequency upsampling after conversion in a few-frequency space. This design facilitates the modeling of high-dimensional spectrograms without compromising the speed. The results demonstrated that iSTFTNet2 made iSTFTNet faster and more lightweight with comparable speech quality.
Contents
Results
I. Comparison on LJSpeech
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | |
|---|---|---|---|---|---|---|
| Ground truth |
| HiFi-GAN V2 [2] |
|---|
| iSTFTNet-C8C8I4 [1] | ||||||
|---|---|---|---|---|---|---|
| iSTFTNet-C8C1I32 [1] |
| iSTFTNet2-Base | ||||||
|---|---|---|---|---|---|---|
| iSTFTNet2-Small |
| iSTFTNet-MB [1][4] | ||||||
|---|---|---|---|---|---|---|
| iSTFTNet2-MB |
II. Comparison on VCTK
| Sample 1 (p227) | Sample 2 (p236) | Sample 3 (p245) | Sample 4 (p272) | Sample 5 (p312) | Sample 6 (p339) | |
|---|---|---|---|---|---|---|
| Ground truth |
| HiFi-GAN V2 [2] |
|---|
| iSTFTNet-C8C8I4 [1] | ||||||
|---|---|---|---|---|---|---|
| iSTFTNet-C8C1I32 [1] |
| iSTFTNet2-Base | ||||||
|---|---|---|---|---|---|---|
| iSTFTNet2-Small |
Citation
@inproceedings{kaneko2023istftnet2,
title={{iSTFTNet2}: Faster and More Lightweight {iSTFT}-Based Neural Vocoder Using {1D-2D CNN}},
author={Takuhiro Kaneko and Hirokazu Kameoka and Kou Tanaka and Shogo Seki},
booktitle={Interspeech},
year={2023},
}
References
- T. Kaneko, K. Tanaka, H. Kameoka, S. Seki. iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform. ICASSP, 2022.
- J. Kong, J. Kim, J. Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. NeurIPS, 2020.
- K. Ito, L. Johnson. The LJ Speech Dataset. 2017.
- G. Yang, S. Yang, K. Liu, P. Fang, W. Chen, L. Xie. Multi-Band Melgan: Faster Waveform Generation For High-Quality Text-To-Speech. SLT, 2021.
- J. Yamagishi, C. Veaux, K. MacDonald. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit. University of Edinburgh. The Centre for Speech Technology Research, 2017.