A paper presented at EUSIPCO 2025
Baseline Systems and Evaluation Metrics for Spatial Semantic Segmentation of Sound Scenes
We are pleased to announce that our paper "Baseline Systems and Evaluation Metrics for Spatial Semantic Segmentation of Sound Scenes" by Binh Thien Nguyen, Masahiro Yasuda, Daiki Takeuchi, Daisuke Niizumi, Yasunori Ohishi, and Noboru Harada has been accepted to EUSIPCO 2025.
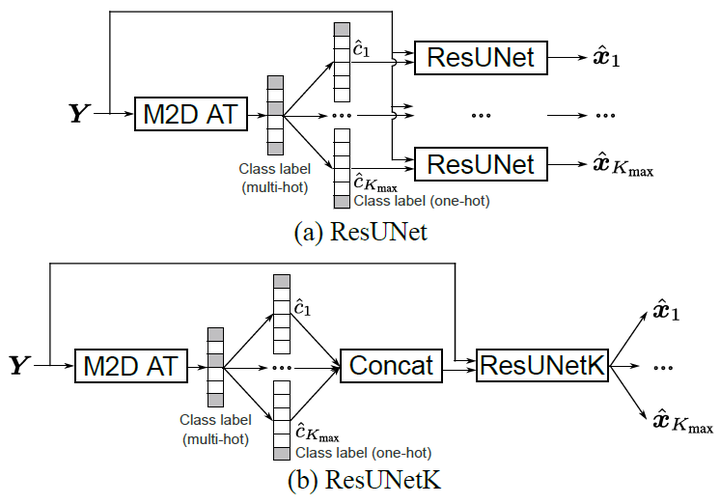
Immersive communication has made significant advancements, especially with the release of the codec for Immersive Voice and Audio Services. Aiming at its further realization, the DCASE 2025 Challenge has recently introduced a task for spatial semantic segmentation of sound scenes (S5), which focuses on detecting and separating sound events in spatial sound scenes. In this paper, we explore methods for addressing the S5 task. Specifically, we present baseline S5 systems that combine audio tagging (AT) and label-queried source separation (LSS) models. We investigate two LSS approaches based on the ResUNet architecture: a) extracting a single source for each detected event and b) querying multiple sources concurrently. Since each separated source in S5 is identified by its sound event class label, we propose new class-aware metrics to evaluate both the sound sources and labels simultaneously. Experimental results on firstorder ambisonics spatial audio demonstrate the effectiveness of the proposed systems and confirm the efficacy of the metrics.
Yasunori Ohishi
Senior Manager
My research interests include acoustic signal processing, crossmodal learning and music information retrieval.