

データと学習の科学
データに隠れた関係性を賢く抜き出します
~無限バイクラスタリングによる特徴的部分行列の抽出~

概要
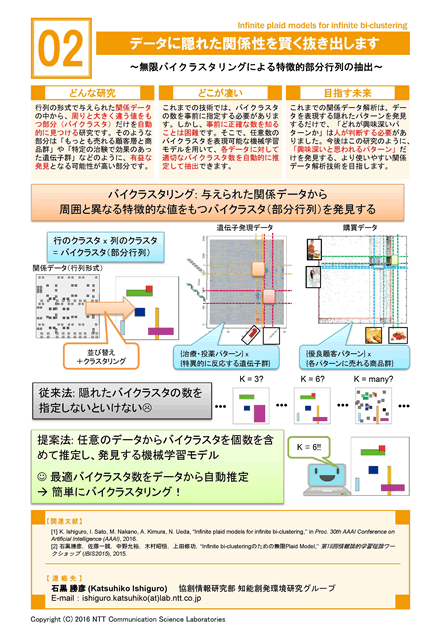
行列の形式で与えられた関係データの中から、周りと大きく違う値をもつ部分(バイクラスタ)だけを自動的に見つける研究です。そのような部分は「もっとも売れる顧客層と商品群」や「特定の治験で効果のあった遺伝子群」などのように、有益な知識となる可能性が高い部分です。
これまでの技術では、バイクラスタの数を事前に指定する必要があります。しかし、不適切な数を指定すると解析に失敗します。そこで、任意数のバイクラスタを表現可能な機械学習モデルを用いて、各データに対して適切なバイクラスタ数を自動的に推定して抽出できます。
これまでの技術では、バイクラスタの数を事前に指定する必要があります。しかし、不適切な数を指定すると解析に失敗します。そこで、任意数のバイクラスタを表現可能な機械学習モデルを用いて、各データに対して適切なバイクラスタ数を自動的に推定して抽出できます。
当日の様子


ポスター
ポスターの画像をクリックすると、PDFファイルが開きます。



