

Science of Machine Learning
Find a good number of salient patterns in a matrix
- Infinite plaid models for infinite bi-clustering -

Abstract
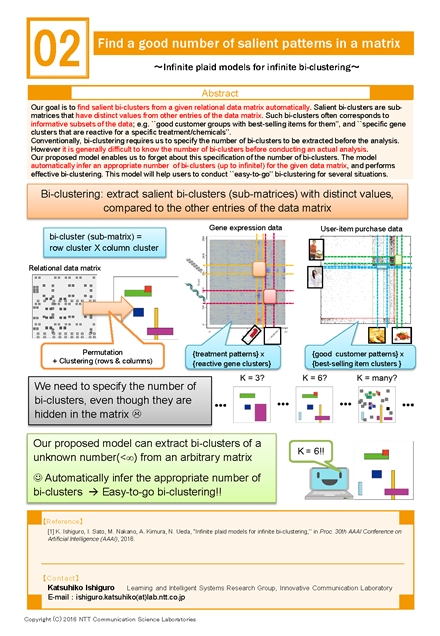
Our goal is to find salient bi-clusters from a given relational data matrix automatically. Salient bi-clusters are sub-matrices that have distinct values from other entries of the data matrix. Such bi-clusters often corresponds to informative subsets of the data; e.g. “good customer groups with best-selling items for them”, and “specific gene clusters that are reactive for a specific treatment/chemicals” .
Conventionally, bi-clustering requires us to specify the number of bi-clusters to be extracted before the analysis. Howeverit is generally difficult to know the number of bi-clusters before conducting an actual analysis.
Our proposed model enables us to forget about this specification of the number of bi-clusters. The model automatically infer an appropriate number of bi-clusters (up to infinite!) for the given data matrix, and performs effective bi-clustering. This model will help users to conduct “easy-to-go” bi-clustering for several situations.
Conventionally, bi-clustering requires us to specify the number of bi-clusters to be extracted before the analysis. Howeverit is generally difficult to know the number of bi-clusters before conducting an actual analysis.
Our proposed model enables us to forget about this specification of the number of bi-clusters. The model automatically infer an appropriate number of bi-clusters (up to infinite!) for the given data matrix, and performs effective bi-clustering. This model will help users to conduct “easy-to-go” bi-clustering for several situations.
Photos


Poster
Please click the thumbnail image to open the full-size PDF file.
Presenters




Takuma Otsuka
Innovative Communication Laboratory
Innovative Communication Laboratory