TL;DR
We propose MeanVoiceFlow, a novel one-step nonparallel VC model based on mean flows, which can be trained from scratch without requiring pretraining or distillation.
Abstract
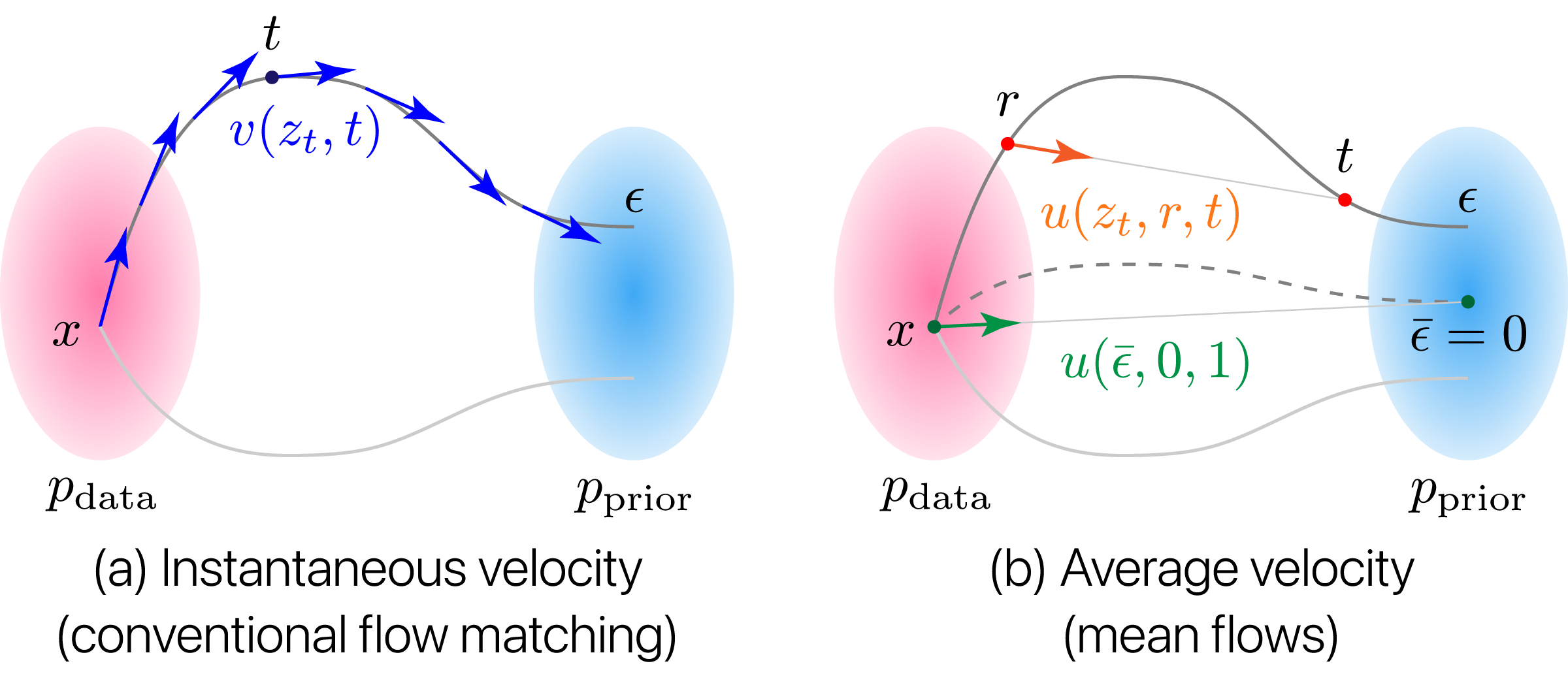
In voice conversion (VC) applications, diffusion and flow-matching models have exhibited exceptional speech quality and speaker similarity performances. However, they are limited by slow conversion owing to their iterative inference. Consequently, we propose MeanVoiceFlow, a novel one-step nonparallel VC model based on mean flows, which can be trained from scratch without requiring pretraining or distillation. Unlike conventional flow matching that uses instantaneous velocity, mean flows employ average velocity to more accurately compute the time integral along the inference path in a single step. However, training the average velocity requires its derivative to compute the target velocity, which can cause instability. Therefore, we introduce a structural margin reconstruction loss as a zero-input constraint, which moderately regularizes the input--output behavior of the model without harmful statistical averaging. Furthermore, we propose conditional diffused-input training in which a mixture of noise and source data is used as input to the model during both training and inference. This enables the model to effectively leverage source information while maintaining consistency between training and inference. Experimental results validate the effectiveness of these techniques and demonstrate that MeanVoiceFlow achieves performance comparable to that of previous multi-step and distillation-based models, even when trained from scratch.
Contents
- Analysis of zero-input constraint (Table 1)
- Analysis of conditional diffused-input training (Fig. 3)
- Comparisons with prior models (Table 2)
- Versatility analysis (Table 3)
Results
I. Analysis of zero-input constraint (Table 1)
- (E): SSIM + margin + zero-input constraint (proposed configuration)
| Source | Target | (A) | (B) | (C) | (D) | (E) | (F) | |
|---|---|---|---|---|---|---|---|---|
| Metric | — | L1 | L2 | SSIM | SSIM |
SSIM | ||
| Margin | — | — | — | — | ✓ |
✓ | ||
| Input | — | Zero | Zero | Zero | Zero |
All | ||
| Female → Female | ||||||||
| Male → Male | ||||||||
| Female → Male | ||||||||
| Male → Female |
Incorporating the reconstruction loss with (1) structural comparison (SSIM), (2) margin-based relaxation, and (3) selective application (zero-input constraint) is crucial for achieving high-fidelity synthesis.
II. Analysis of conditional diffused-input training (Fig. 3)
- w/: With conditional diffused-input training (proposed training)
- w/o: Without conditional diffused-input training
Note: w/o may produce buzzy sounds at t' = 0.5 and t' = 0.0; please adjust the volume accordingly.
| Source | Target | w/o | w/ | w/o | w/ | w/o | w/ | |
|---|---|---|---|---|---|---|---|---|
| t' | – | – | 1.0 | 1.0 | 0.5 | 0.5 | 0.0 | 0.0 |
| Female → Female | ||||||||
| Male → Male | ||||||||
| Female → Male | ||||||||
| Male → Female |
Conditional diffused-input training (w/) enhances both robustness to the mixing ratio t' and peak performance.
III. Comparisons with prior models (Table 2)
- MVF: MeanVoiceFlow (proposed model)
| Source | Target | DiffVC-30 | VG-DM-1 | VG-DM-30 | VG-FM-1 | VG-FM-30 | FVG | FVG+ | MVF | |
|---|---|---|---|---|---|---|---|---|---|---|
| NFE | 30 | 1 | 30 | 1 | 30 | 1 | 1 | 1 |
||
| From scratch | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | ✓ |
||
| Female → Female | ||||||||||
| Male → Male | ||||||||||
| Female → Male | ||||||||||
| Male → Female |
MeanVoiceFlow (MVF) outperforms one-step models trained from scratch, such as VoiceGrad-DM-1 (VG-DM-1) and VoiceGrad-FM-1 (VG-FM-1), and achieves performance comparable to that of multi-step models, including VoiceGrad-DM-30 (VG-DM-30) and VoiceGrad-FM-30 (VG-FM-30), as well as one-step models enhanced by distillation and adversarial training, such as FastVoiceGrad (FVG) and FastVoiceGrad+ (FVG+).
IV. Versatility analysis (Table 3)
- MVF: MeanVoiceFlow (proposed model)
| Source | Target | VG-DM-1 | VG-DM-30 | VG-FM-1 | VG-FM-30 | MVF | |
|---|---|---|---|---|---|---|---|
| NFE | 1 | 30 | 1 | 30 | 1 |
||
| Female → Female | |||||||
| Male → Male | |||||||
| Female → Male | |||||||
| Male → Female |
On another dataset, MeanVoiceFlow (MVF) outperforms one-step models trained from scratch, such as VoiceGrad-DM-1 (VG-DM-1) and VoiceGrad-FM-1 (VG-FM-1), and achieves performance comparable to that of multi-step models, including VoiceGrad-DM-30 (VG-DM-30) and VoiceGrad-FM-30 (VG-FM-30).
Citation
@inproceedings{kaneko2026meanvoiceflow,
title={MeanVoiceFlow: One-step Nonparallel Voice Conversion with Mean Flows},
author={Kaneko, Takuhiro and Kameoka, Hirokazu and Tanaka, Kou and Kondo, Yuto},
booktitle={ICASSP},
year={2026},
}