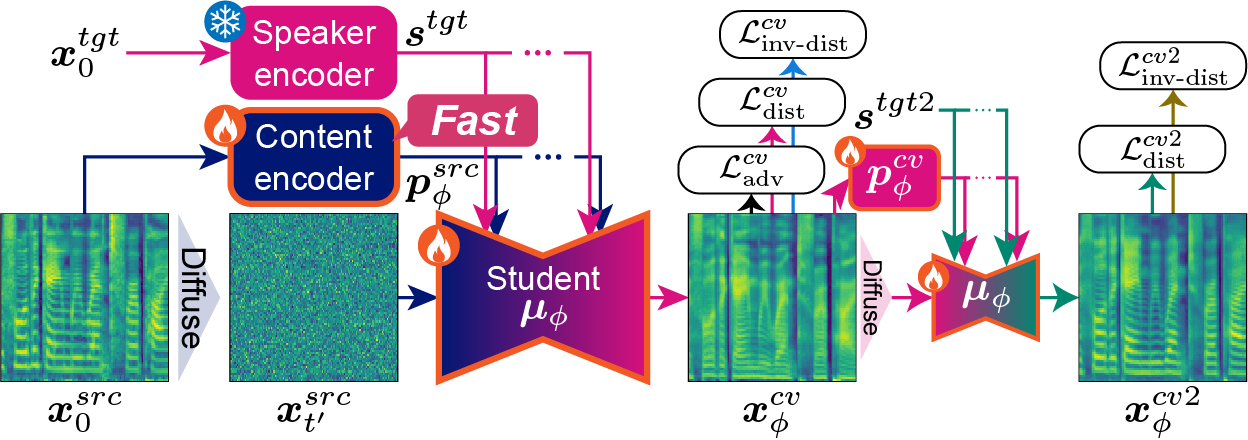
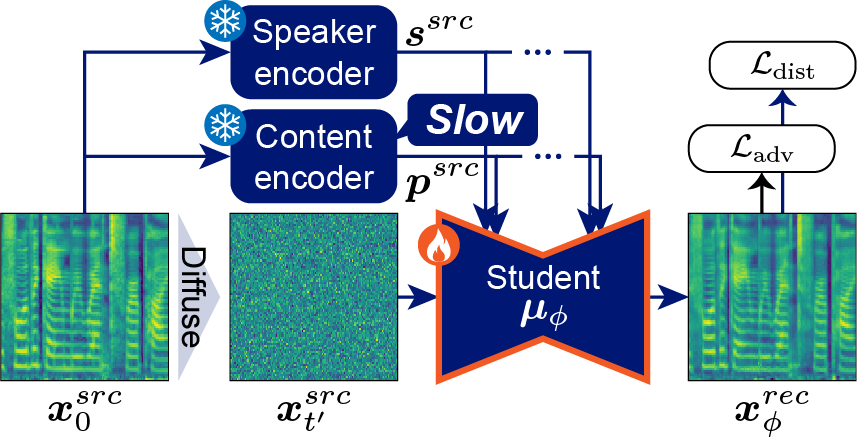
FasterVoiceGrad (proposed): Jointly distilling a diffusion model and a content encoder Cf. FastVoiceGrad (previous): Distilling only a diffusion model
TL;DR
We propose FasterVoiceGrad, a novel one-step diffusion-based voice conversion (VC) model, obtained by jointly distilling a diffusion model and a content encoder through adversarial diffusion conversion distillation (ADCD).
Abstract
A diffusion-based voice conversion (VC) model (e.g., VoiceGrad) can achieve high speech quality and speaker similarity; however, its conversion process is slow owing to iterative sampling. FastVoiceGrad overcomes this limitation by distilling VoiceGrad into a one-step diffusion model. However, it still requires a computationally intensive content encoder to disentangle the speaker's identity and content, which slows conversion. Therefore, we propose FasterVoiceGrad, a novel one-step diffusion-based VC model obtained by simultaneously distilling a diffusion model and content encoder using adversarial diffusion conversion distillation (ADCD), where distillation is performed in the conversion process while leveraging adversarial and score distillation training. Experimental evaluations of one-shot VC demonstrated that FasterVoiceGrad achieves competitive VC performance compared to FastVoiceGrad, with 6.6--6.9 and 1.8 times faster speed on a GPU and CPU, respectively.