Please check out our follow-up work!
- CycleGAN-VCs: CycleGAN-VC2, CycleGAN-VC3, MaskCycleGAN-VC (Latest)
- StarGAN-VCs: StarGAN-VC, StarGAN-VC2
- WaveCycleGANs: WaveCycleGAN, WaveCycleGAN2
- Other VCs: Links to demo pages
Paper

Takuhiro Kaneko and Hirokazu Kameoka
Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks
arXiv:1711.11293, Nov. 2017 (EUSIPCO 2018)
[Paper]
(Alternative title: "CycleGAN-VC: Non-parallel Voice Conversion Using Cycle-Consistent Adversarial Networks")
CycleGAN-VC
We propose a non-parallel voice-conversion (VC) method that can learn a mapping from source to target speech without relying on parallel data. The proposed method is particularly noteworthy in that it is general purpose and high quality and works without any extra data, modules, or alignment procedure.
Our method, called CycleGAN-VC, uses a cycle-consistent adversarial network (CycleGAN) [1] (i.e., DiscoGAN [2] or DualGAN [3]) with gated convolutional neural networks (CNNs) [4] and an identity-mapping loss [5]. We show the training procedure in Figure 1. In a CycleGAN, forward and inverse mappings are simultaneously learned using an adversarial loss and cycle-consistency loss (Figure 1 (a)(b)). This makes it possible to find an optimal pseudo pair from non-parallel data. Furthermore, the adversarial loss can bring the converted speech close to the target one on the basis of indistinguishability without explicit density estimation. This allows to avoid over-smoothing caused by statistical averaging, which occurs in many conventional statistical model-based VC methods that represent data distribution explicitly.
The cycle-consistency loss imposes constraints on the structure of the mapping; however, it would not suffice to guarantee that the mappings always preserve linguistic information. To encourage linguistic-information preservation without relying on extra modules, we incorporate an identity-mapping loss, which encourages the generator to find the mapping that preserves composition between the input and output (Figure 1 (c)(d)).

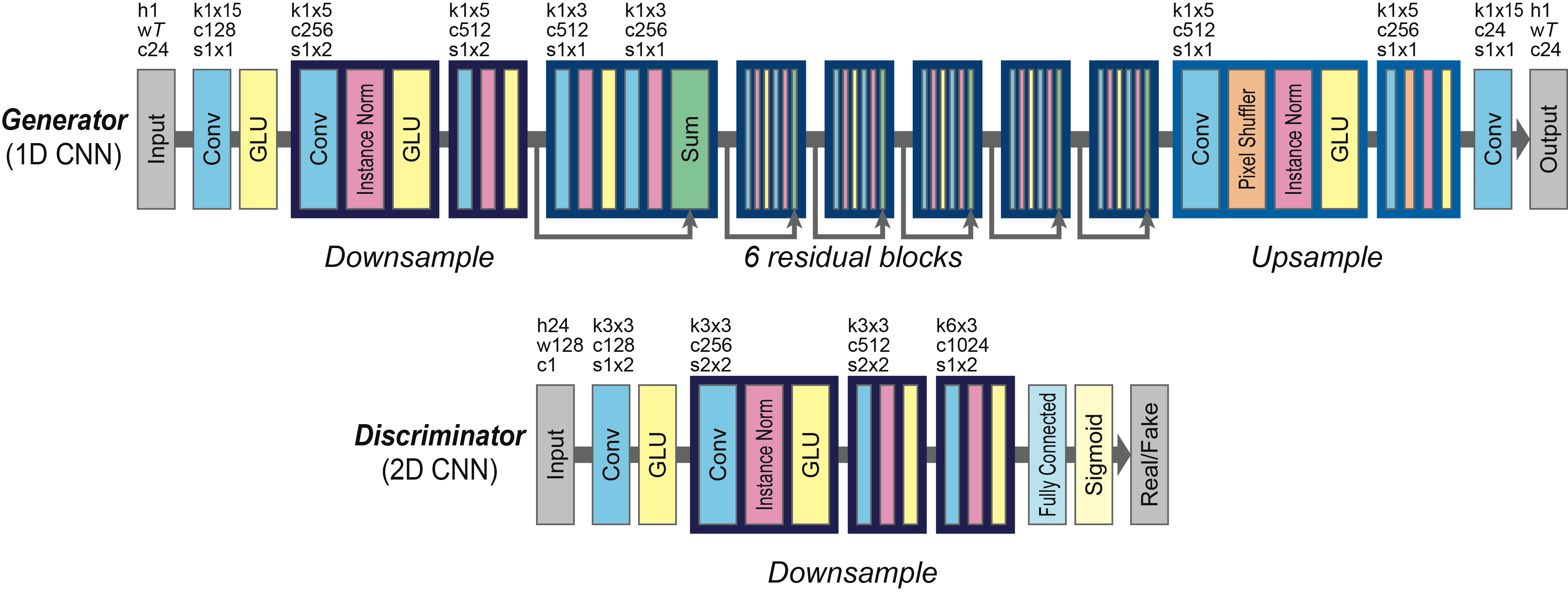
One of the important characteristics of speech is that it has sequential and hierarchical structures, e.g., voiced or unvoiced segments and phonemes or morphemes. An effective way to represent such structures would be to use an RNN, but it is computationally demanding due to the difficulty of parallel implementations. Instead, we configure a CycleGAN using gated CNNs that not only allow parallelization over sequential data but also achieve state-of-the-art in language modeling [4] and speech modeling [6]. In a gated CNN, gated linear units (GLUs) are used as an activation function. A GLU is a data-driven activation function, and the gated mechanism allows the information to be selectively propagated depending on the previous layer states. We illustrate the network architectures of the generator and discriminator in Figure 2.
We evaluated our method on a non-parallel VC task. An objective evaluation showed that the converted feature sequence was near natural in terms of global variance and modulation spectra, which are structural indicators highly correlated with subjective evaluation. A subjective evaluation showed that the quality of the converted speech was comparable to that obtained with a Gaussian mixture model-based parallel VC method even though CycleGAN-VC is trained under disadvantageous conditions (non-parallel and half the amount of data). We provide speech samples below.
Speech Samples
We evaluated our method using the Voice Conversion Challenge 2016 (VCC 2016) dataset [7].
To evaluate our method under a non-parallel condition, we divided the training set into two subsets without overlap.
The first half 81 sentences were used for the source and the other 81 sentences were used for the target.
This means that CycleGAN-VC is trained under the disadvantageous condition (non-parallel and half the amount of data).
For comparison with other methods, we refer to the following web sites:
- Summary of VCC 2016
- VAW-GAN demo [8]
- StarGAN-VC demo (our follow-up work) [9]
- CycleGAN-VC2 demo (our follow-up work) [11]
NOTE: Recommended browsers are Apple Safari, Google Chrome, or Mozilla Firefox.
Female (SF1) → Female (TF2)
| Source | Target | CycleGAN-VC | |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 |
Female (SF1) → Male (TM3)
| Source | Target | CycleGAN-VC | |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 |
Male (SM1) → Female (TF2)
| Source | Target | CycleGAN-VC | |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 |
Male (SM1) → Male (TM3)
| Source | Target | CycleGAN-VC | |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 |
Implementations
Implementations of CycleGAN-VC by our followers.
If you would like to add yours, please contact us.
References
[1] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. The IEEE International Conference on Computer Vision (ICCV), 2017. [Paper]
[2] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jungkwon Lee, and Jiwon Kim. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. The International Conference on Machine Learning (ICML), 2017. [Paper]
[3] Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. The IEEE International Conference on Computer Vision (ICCV), 2017. [Paper]
[4] Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. Language Modeling with Gated Convolutional Networks. The International Conference on Machine Learning (ICML), 2017. [Paper]
[5] Yaniv Taigman, Adam Polyak, and Lior Wolf. Unsupervised Cross-Domain Image Generation. The International Conference on Learning Representations (ICLR), 2017. [Paper]
[6] Takuhiro Kaneko, Hirokazu Kameoka, Kaoru Hiramatsu, and Kunio Kashino. Sequence-to-Sequence Voice Conversion with Similarity Metric Learned Using Generative Adversarial Networks. The Annual Conference of the International Speech Communication Association (INTERSPEECH), 2017. [Paper]
[7] Tomoki Toda, Ling-Hui Chen, Daisuke Saito, Fernando Villavicencio, Mirjam Wester, Zhizheng Wu, and Junichi Yamagishi. The Voice Conversion Challenge 2016. The Annual Conference of the International Speech Communication Association (INTERSPEECH), 2016. [Paper]
[8] Chin-Cheng Hsu, Hsin-Te Hwang, Yi-Chiao Wu, Yu Tsao, and Hsin-Min Wang. Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks. The Annual Conference of the International Speech Communication Association (INTERSPEECH), 2017. [Paper]
Please check out our follow-up work!
[9] Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, and Nobukatsu Hojo. StarGAN-VC: Non-parallel Many-to-Many Voice Conversion with Star Generative Adversarial Networks. arXiv:1806.02169, June 2018 (The IEEE Workshop on Spoken Language Technology (SLT), Dec. 2018). [Paper] [Project]
[10] Kou Tanaka, Takuhiro Kaneko, Nobukatsu Hojo, and Hirokazu Kameoka. WaveCycleGAN: Synthetic-to-Natural Speech Waveform Conversion Using Cycle-Consistent Adversarial Networks. arXiv:1809.10288, Sep. 2018 (The IEEE Workshop on Spoken Language Technology (SLT), Dec. 2018). [Paper] [Project]
[11] Takuhiro Kaneko, Hirokazu Kameoka, Kou Tanaka, and Nobukatsu Hojo. CycleGAN-VC2: Improved CycleGAN-based Non-parallel Voice Conversion. The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2019. [Project]
Contact
Takuhiro Kaneko
NTT Communication Science Laboratories, NTT Corporation
kaneko.takuhiro at lab.ntt.co.jp