

| 07 |
データを漏洩させない機械学習革新的な非同期分散型学習アルゴリズムと医療画像への応用 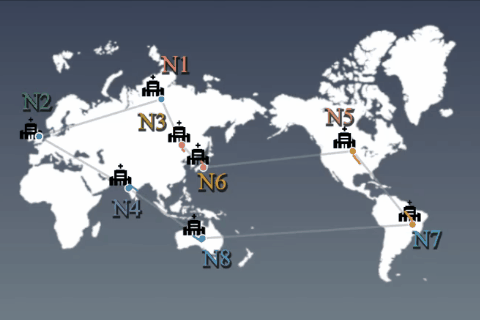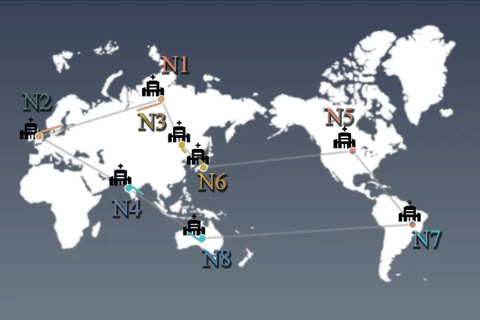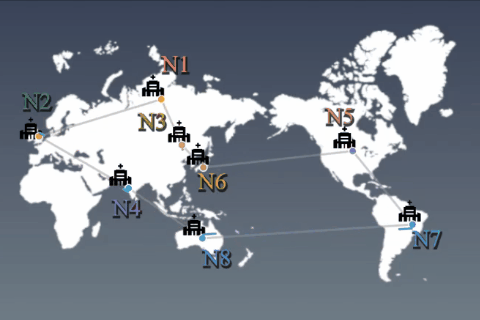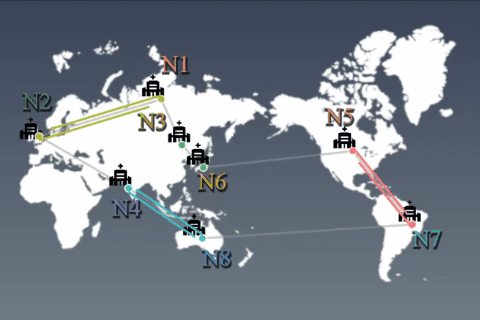
|
|---|
| どんな研究 |
1か所に集約したデータを使ってモデルを学習することが一般的です。しかし、データ量の激増やプライバシー保護の観点からデータ蓄積や学習/推論処理は分散化されるでしょう。データを各ノード(例:基地局)から外に出すことなく、機械学習モデルを学習する手法を提案します。 |
|---|---|
| どこが凄い |
分散蓄積されたデータは、統計的に偏っていると仮定することが自然です(例:一部クラスのデータが存在しない)。その状況で、ノード同士がモデル等の変数を非同期に交換(通信)しながら、全データを使って学習したかのようなグローバルモデルを得るアルゴリズムを開発しました。 |
| めざす未来 |
地域/国/世界中のデータ全体を間接的に取り扱えるようにすることで、プライバシーを保護しながらも、高度な知を形成したり、高性能なサービス(例:医療)を提供できるようにしたいです。 |

[1] J. Chen, A. H. Sayed, “Diffusion adaptation strategies for distributed optimization and learning over networks,” IEEE Transactions on Signal Processing, Vol. 60, No. 8, pp. 4289?4305, 2012.
[2] B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, “Communication?efficient learning of deep networks from decentralized data,” in Proc. Artificial Intelligence and Statistics (AISTATS 2017), pp. 1273?1282, 2017.
[3] K. Niwa, N. Harada, G. Zhang, W. B. W Kleijn, “Edge-consensus learning: deep learning on P2P networks with nonhomogeneous data,” in Proc. the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD 2020), pp. 668?678, 2020.
[4] National Institutes of Health (NIH) clinical center, ChestXray14 data set.

丹羽 健太 (Kenta Niwa)協創情報研究部 知能創発環境研究グループ
Email: cs-openhouse-ml@hco.ntt.co.jp