



| 07 |
Look for bilingual sentence pairs in the worldLarge-scale parallel corpus construction technology 
|
|---|
Machine translation systems require many bilingual sentence pairs (translations of each other) as training data. We are researching technology to build a parallel corpus (bilingual database) by collecting bilingual text scattered on the Internet (Web) and in patent application archives. JParaCrawl, a web-based parallel corpus, was constructed by efficiently collecting many bilingual sentence pairs from the Web using crowdsourcing. JaParaPat, a patent parallel corpus, has improved the quality of its sentence pairs by alternately extracting data and training models. Both are the world's largest publicly available parallel corpus between Japanese and English. We will further enhance our technology to automatically build a high-quality parallel corpus in specific fields, such as medicine and finance, which are rich in specialized terminology, and in particular language pairs, such as Chinese and Japanese, to implement a machine translation system customized to the needs of our customers.
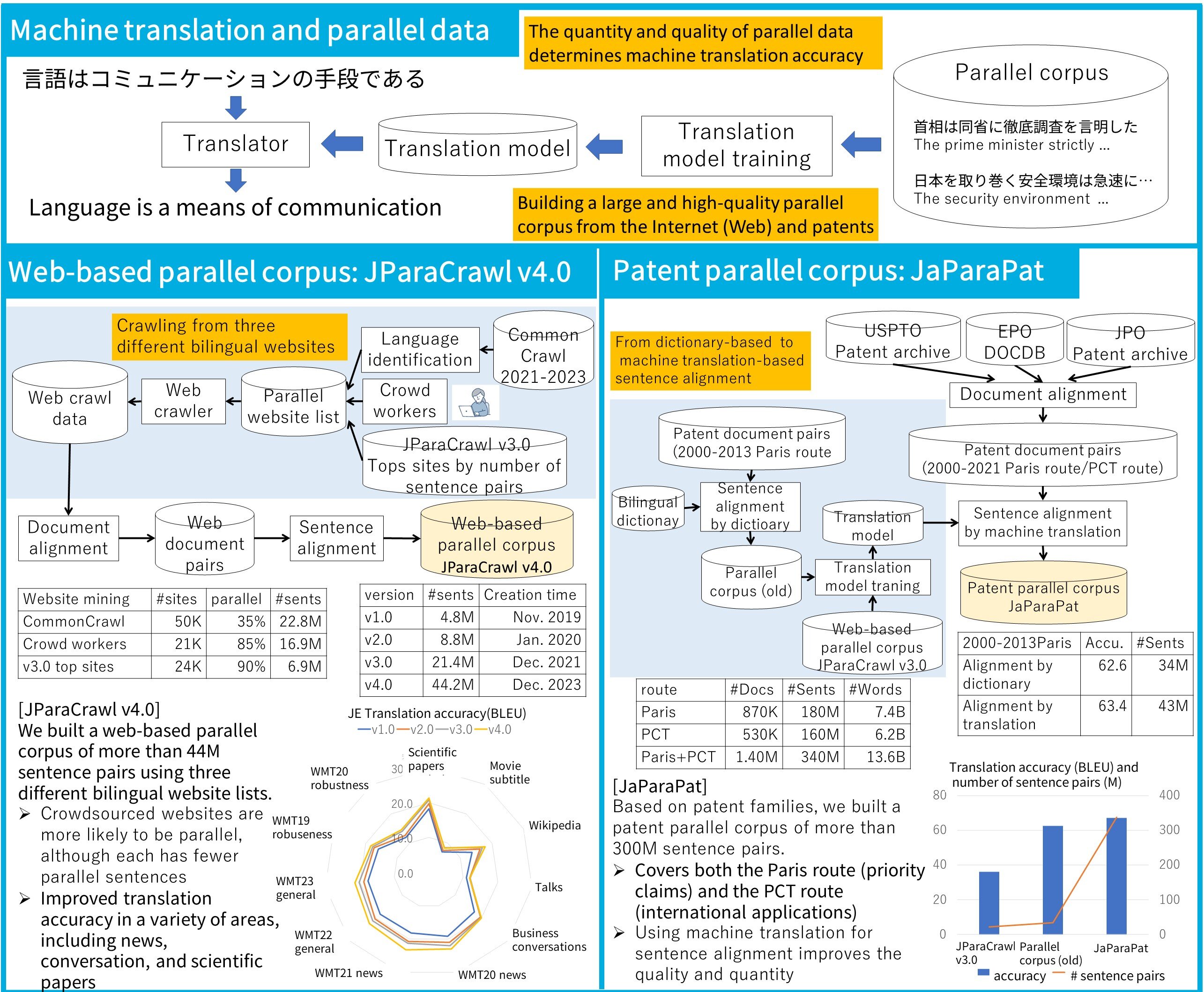
[1] Makoto Morishita, Katsuki Chousa, Masaaki Nagata, “JParaCrawl v4.0: Building a Large Parallel Corpus with Crowdsourcing,” proceedings of the 30th annual meeting of Association for Natural Language Processing (NLP-2024), pp. 2330-2335, 2024 (in Japanese).
[2] Masaaki Nagata, Makoto Morishita, Katsuki Chousa, Norihito Yasuda, “JaParaPat: A Large-scale Japanese-English Parallel Patent Application Corpus,” proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 9452-9462, 2024.

Masaaki Nagata, Linguistic Intelligence Research Group, Innovative Communication Laboratory