

Science of Machine Learning
Finding similar voice recordings in big data
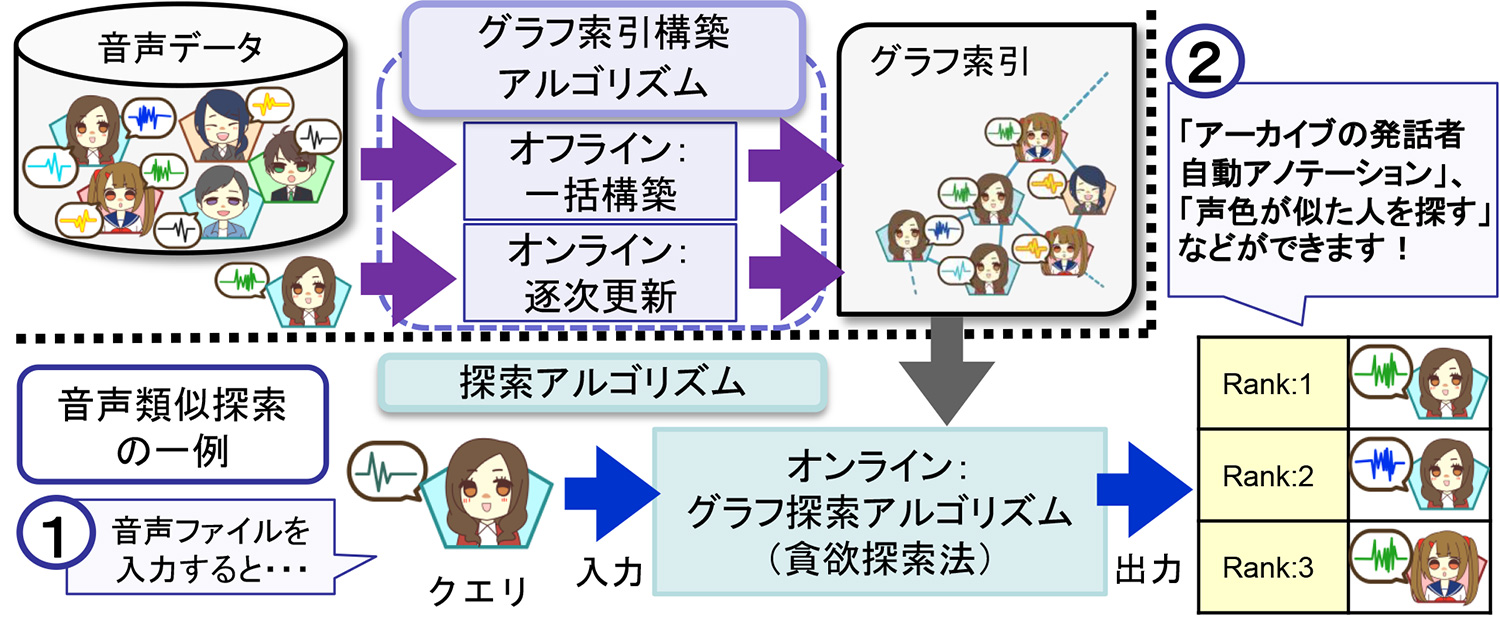
Graph index-based audio similarity search
Abstract
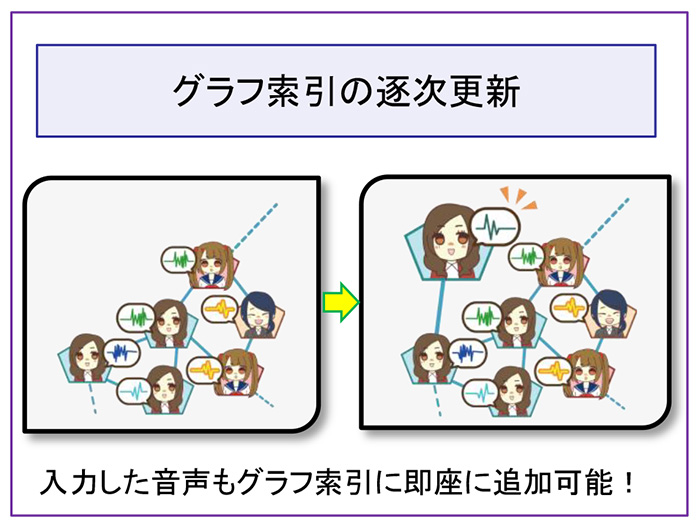
We propose an audio similarity search method for finding similar voice recordings in a large-scale database from an input voice recording. The search method is based on a graph index, where each vertex corresponds to a voice recording and two vertices are connected by an edge when they satisfy a certain similarity condition. The graph index shows small-world behavior, that is, vertices can be reached from every other vertex by a small number of steps. Hence, searching the graph results in quick termination of the search process. Furthermore, since the graph index is constructed based on similarity between two objects, the search method is versatile and can be applied to not only audio, but also text and images. The graph index can be updated successively, adding new objects, such as queries, to the existing graph index. This successive update algorithm allows users to always search with the most current data.

Reference
-
[1] K. Aoyama, A. Ogawa, T. Hattori, T. Hori, “Double-layer neighborhood graph based similarity search for fast query-by-example spoken term detection,” in Proc. Int. Conf. Acoustics, Speech, Signal Process. IEEE, April 2015, pp. 5216-5220.
[2] K. Aoyama, S. Watanabe, H. Sawada, Y. Minami, N. Ueda, K. Saito, “Fast similarity search on a large speech data set with neighborhood graph indexing,” in Proc. Int. Conf. Acoustics, Speech, Signal Process. IEEE, March 2010, pp. 5358-5361.
Poster
Photos


Presenters

Takashi Hattori
Innovative Communication Laboratory
Innovative Communication Laboratory

Kazuo Aoyama
Innovative Communication Laboratory
Innovative Communication Laboratory