Generating datasets using people and information on the WWW
Abstract
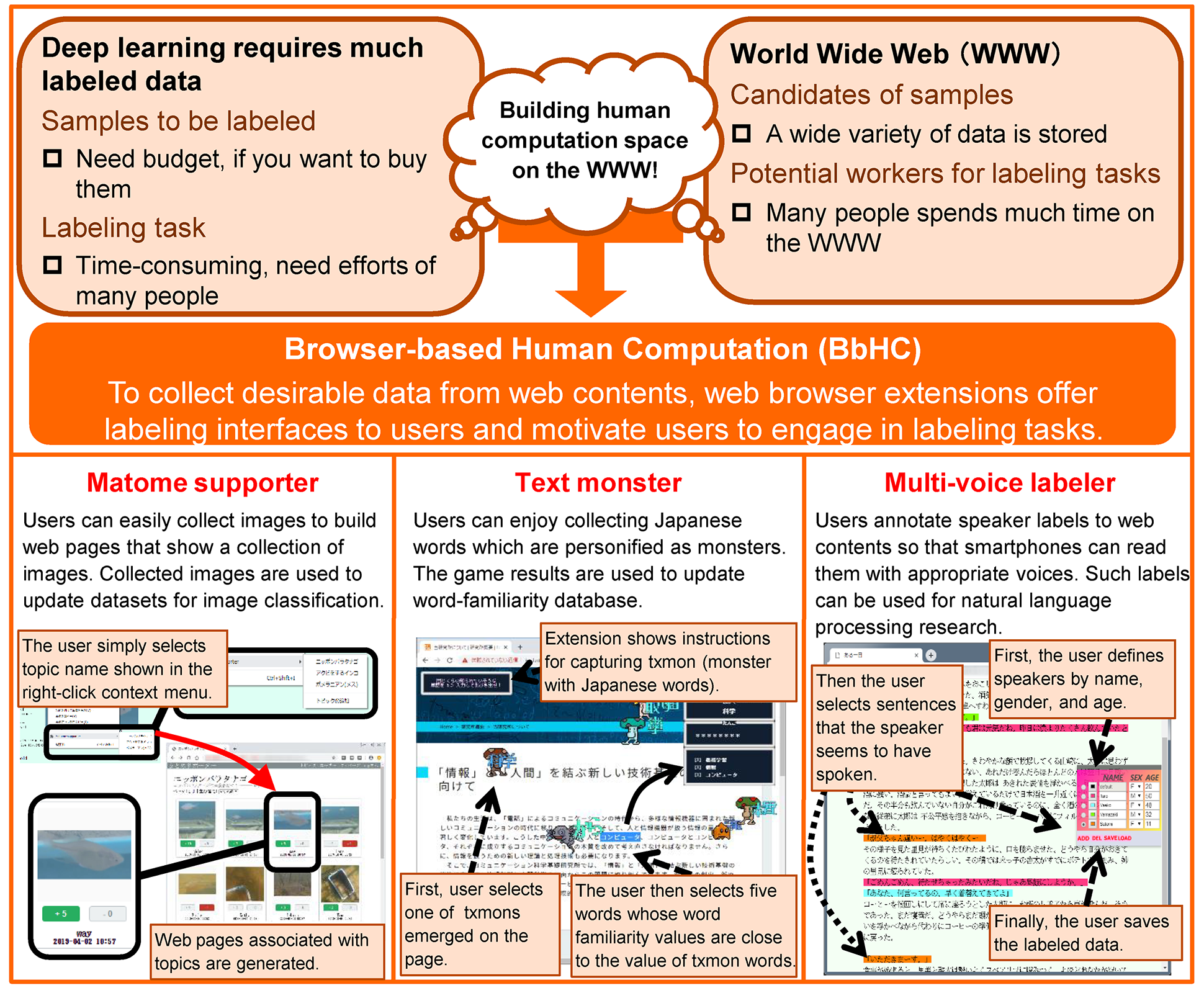
Although contents on the WWW are potentially valuable data as training data for machine learning, they are difficult to use in their current state. Our approach, Browser-based Human Computation (BbHC), offers a cost-effective way to extract desirable data from web contents. BbHC enables people to label various web contents through the web browsers they normally use for web browsing. To accelerate the labeling of data without the inducement of monetary rewards, browser extensions based on BbHC motivate people to continuously engage in labeling tasks through various human computation techniques. We implemented systems based on BbHC to explain how it works. Matome supporter helps us to collect labeled images to create an image classifier. Text monster reduces the cost of annotating word familiarity values for updating a word familiarity database. Multi-voice labeler’s purpose is to collect writings with speaker information for natural language processing research.
References
Y. Shirai, Y. Kishino, Y. Yanagisawa, S. Mizutani, T. Suyama, “Building human computation space on the www: labeling web contents through web browsers,” in Proc. The seventh AAAI Conference on Human Computation and Crowdsourcing (HCOMP2019), 2019.