Abstract
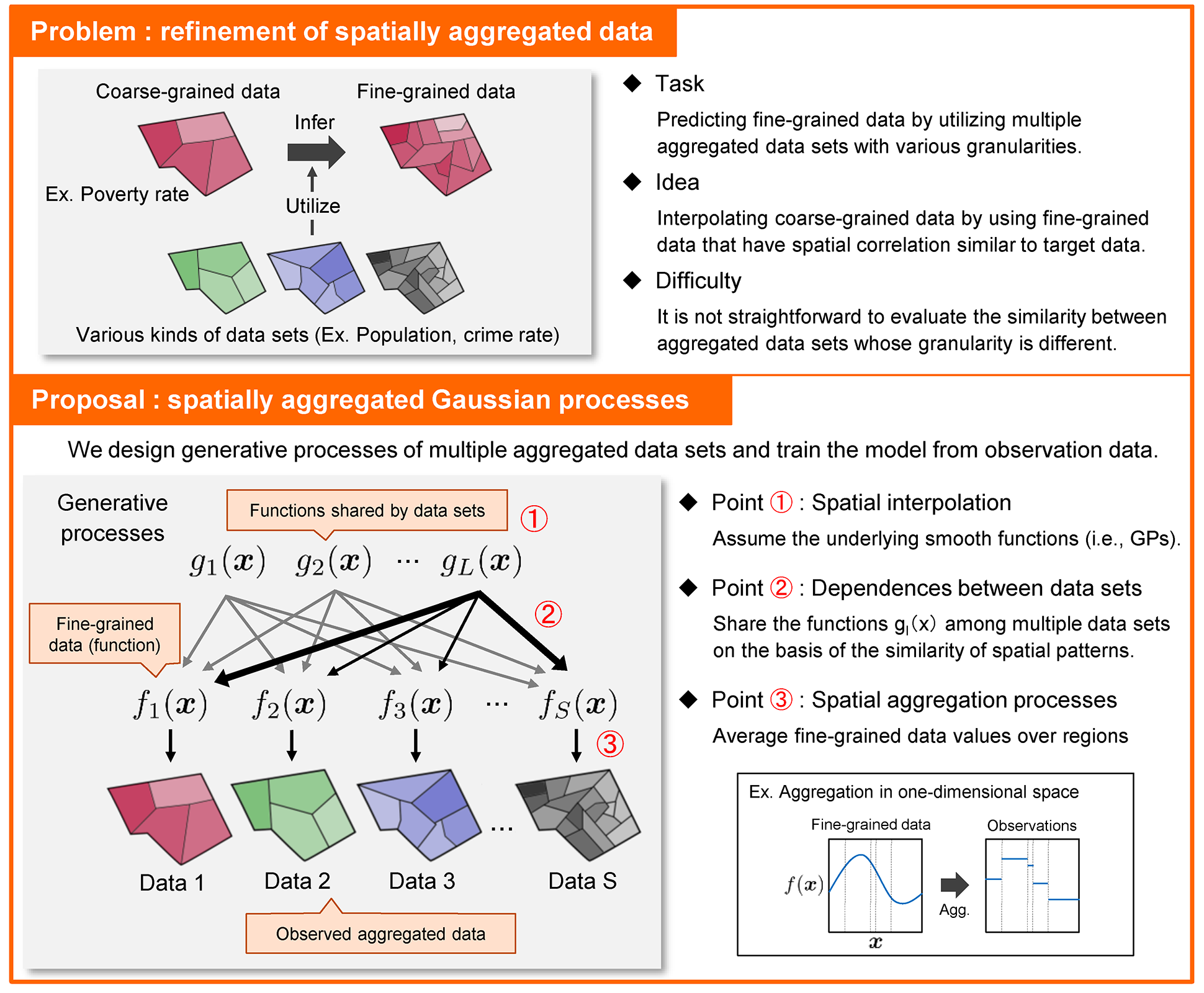
Spatial data collected from cities are often aggregated into geographical partitions (e.g., districts). We propose a probabilistic model for refining coarse-grained aggregated data by utilizing multiple aggregated data sets with various granularities. Our model is based on multivariate Gaussian processes (GPs), in which dependences between data sets are established by linearly mixing some independent latent GPs. We newly introduce an observation model with spatial aggregation processes, which allows us to use multiple aggregated data sets for the refinement task even if they have various granularities. Our model can be used for predicting data values with arbitrary fine granularity; it is useful for finding key pin-point regions (e.g., poverty area) in a city, efficiently. In the future, we will extend the model to handle data gathered from multiple cities simultaneously.
Yusuke Tanaka / Service Evolution Laboratory
Email: