Abstract
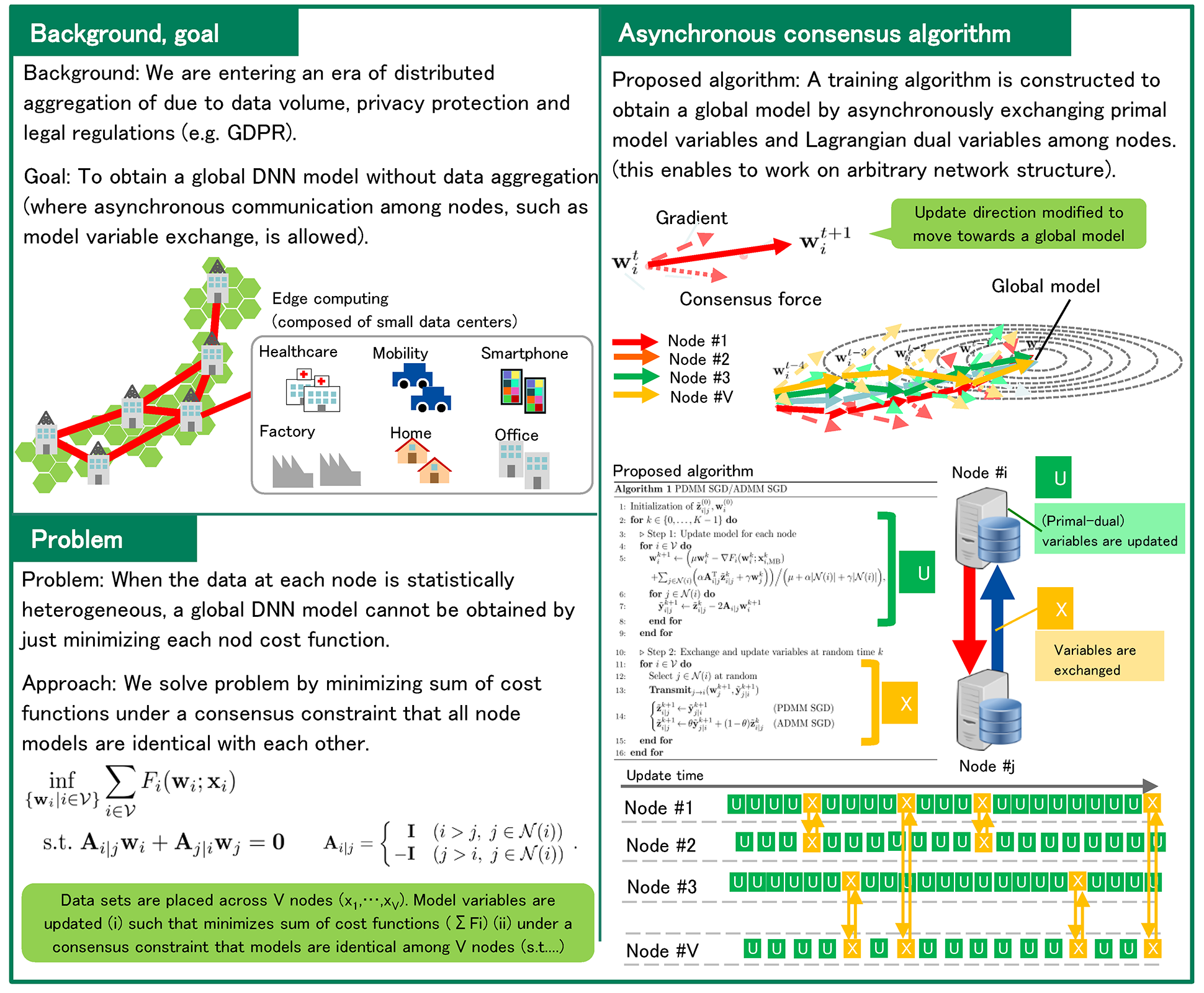
While use of massive data benefits on training DNN models, aggregating all data into one physical location (e.g. a cloud data center) may not be possible due to data privacy concerns from consumers. For example, according to EU GDPR, it is preferable to minimize data transmission between processing nodes.
Our goal is to construct training algorithms to obtain a global DNN model that can be adapted to all data, even when individual nodes only have access to different subsets of the data. We assume that this algorithm is allowed to communicate autonomously between nodes, exchanging information such as model variables or their update difference, but data are prohibited from being moved from node they reside on.
Now, several platformers provide advanced services by aggregating/monopolizing data. However, we aim to create a society where data ownership belongs to individual and can be used for a variety of services while protecting data privacy.
Kenta Niwa / Communication Science Laboratory, Media Intelligence Laboratory
Email: