Abstract
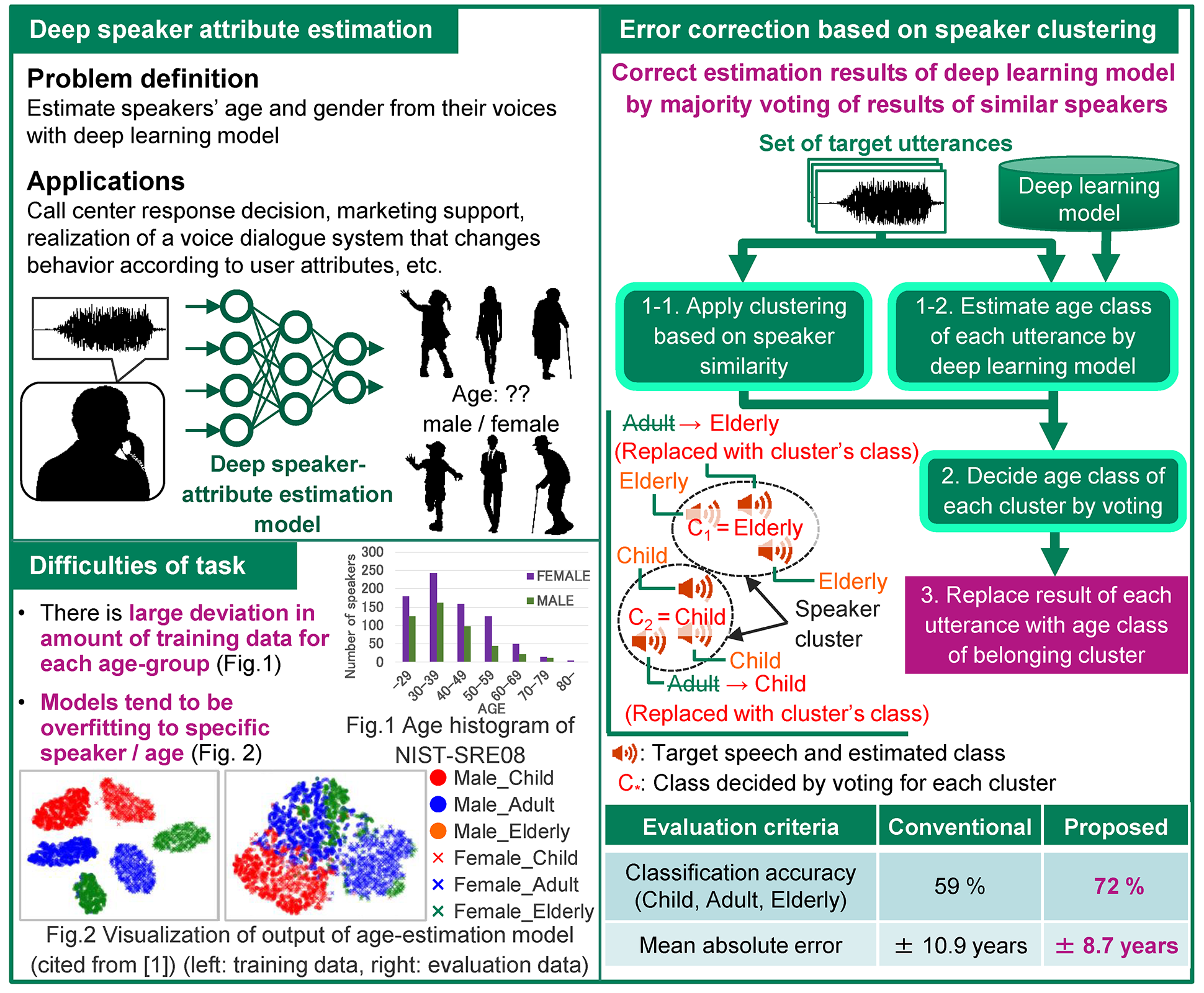
Estimating speaker-attributes such as age and gender is an important task with a wide range of applications. While the recent proposed deep neural network models have been achieving high performance, the estimated results tend to be less reliable because of the overfitting problem. In order to solve this problem, we propose a general framework for correcting the unreliable results of the arbitrary speaker-attribute estimation models. The proposed algorithm first applies speaker clustering to the target utterances to detect similar speakers of target utterances. Then, the speaker-attribute class of each cluster is determined by voting on the utterances assigned to the cluster. Finally, we can correct the result of unreliable utterances by replacing their result with the clusters’ speaker-attribute class. Our approach is evaluated on age-gender classification and gender regression tasks, yielding significant improvements in classification accuracy and mean absolute error.
Naohiro Tawara / Signal Processing Research Group, Media Information Laboratory
Email: