

データと学習の科学
膨大なデータから似た音声を見つけます!
~グラフ索引に基づく類似音声探索~
どんな研究
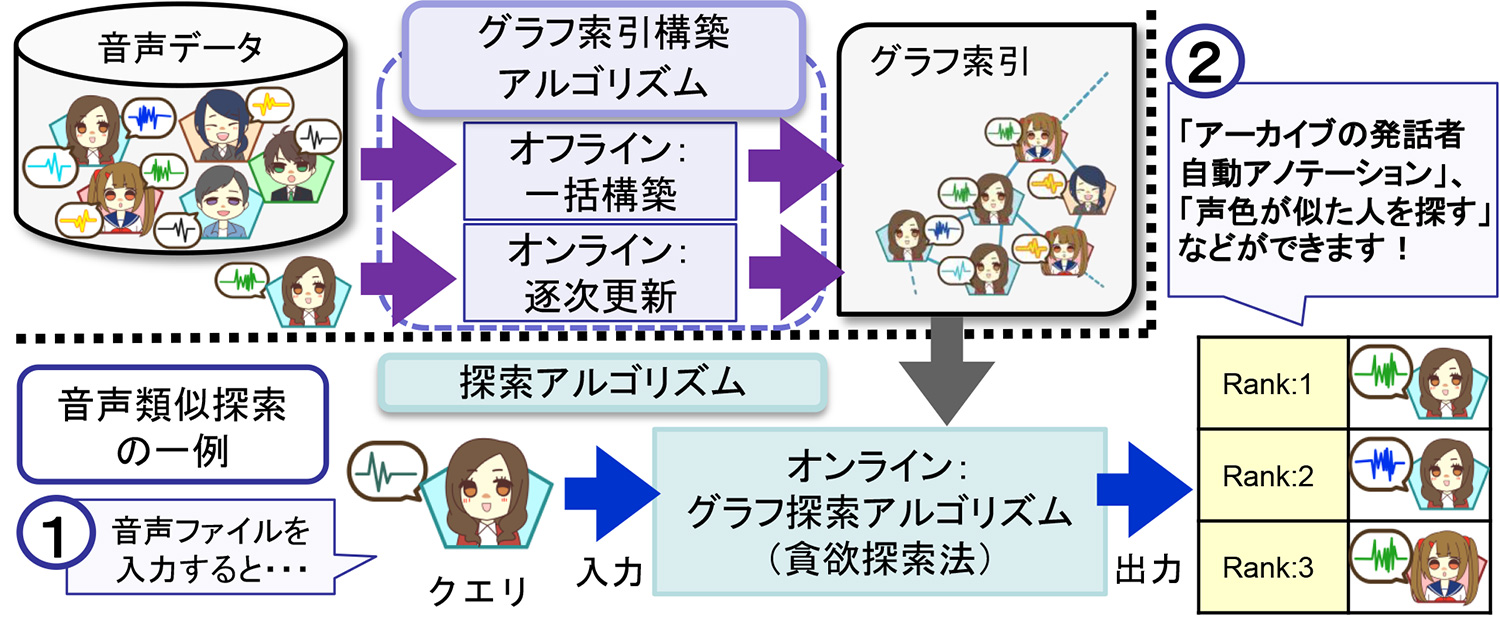
膨大なデータの中から即座に類似のデータを見つけるための研究です。例えば、多数の話者がいろいろな発話をしている膨大な音声データの中から、ある特定の話者の発話した音声データや、その話者に類似の声色の別の話者を探すことができます。
どこが凄い
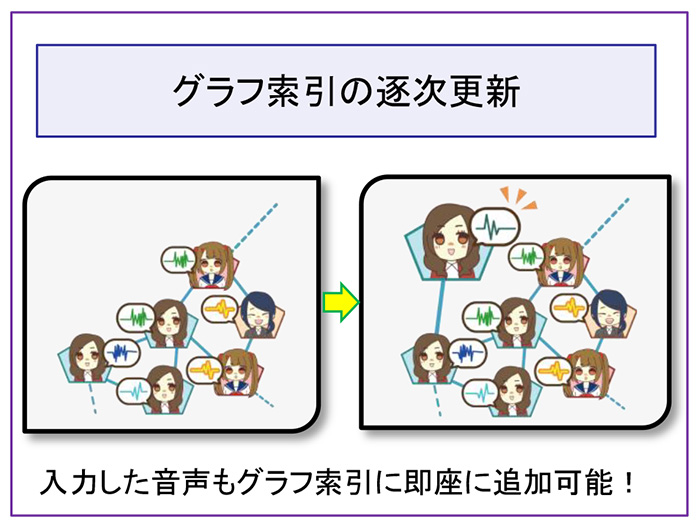
提案法は、検索対象間の類似度さえ定義できれば構築可能なグラフ索引に基づく、多様なメディアに利用できる汎用性に優れた方法です。グラフ索引は、検索の度に随時更新でき、新しい音声を即座に追加することで最新のデータで検索できます。
めざす未来
あらゆるメディアを検索可能なプラットフォームを構築し、なんでも気軽に検索できる未来をめざします。さらには、複数のメディアを統合的に検索可能なクロスメディア検索システムを実現し、文書、画像、音声など何を入力しても役立つ情報が得られる将来をめざします。

関連文献
-
[1] K. Aoyama, A. Ogawa, T. Hattori, T. Hori, “Double-layer neighborhood graph based similarity search for fast query-by-example spoken term detection,” in Proc. Int. Conf. Acoustics, Speech, Signal Process. IEEE, April 2015, pp. 5216-5220.
[2] K. Aoyama, S. Watanabe, H. Sawada, Y. Minami, N. Ueda, K. Saito, “Fast similarity search on a large speech data set with neighborhood graph indexing,” in Proc. Int. Conf. Acoustics, Speech, Signal Process. IEEE, March 2010, pp. 5358-5361.
ポスター
PDFの表示にはAdobe Acrobat Reader等のPDF閲覧表示が必要です。
当日の様子


展示代表者

服部 正嗣
協創情報研究部
協創情報研究部

青山 一生
協創情報研究部
協創情報研究部