

| 13 |
Faithful translation without excess or deficiencyPreference optimization for LLM-based translation 
|
|---|
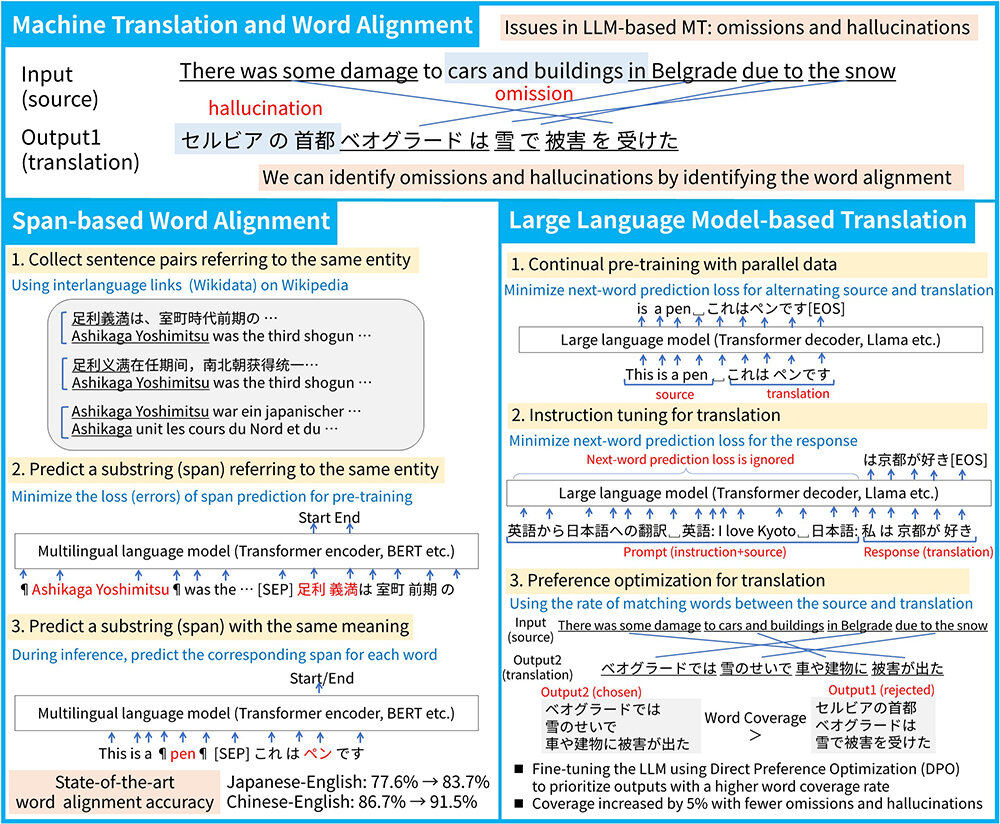
Machine translation using Large Language Models (LLMs) can lead to errors such as “missing translation,” where parts of the source text are omitted, and “hallucination,” where the translation includes content not present in the source text. In this study, we first developed a method to train a highly accurate word alignment model using pairs of sentences in different languages that refer to the same entity in Wikipedia. We then developed a method for training a translation model with fewer omissions and hallucinations by maximizing pairs of words with equivalent meanings in the source text and its translation. In the future, we aim to improve machine translation technology in areas that require precise translations, including patents, law, and medicine. We will improve the fidelity of LLM-based translation, which excel at generating fluent and lengthy translations while maintaining consistency with the source text.
[1] Q. Wu, M. Nagata, Y. Tsuruoka, “WSPAlign: Word alignment pre-training via large-scale weakly supervised span prediction,” in Proc. The 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023), 2023.
[2] Q. Wu, M. Nagata, Z. Mao, Y. Tsuruoka, “Word alignment as preference for machine translation,” in Proc. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), 2024.

Masaaki Nagata, Linguistic Intelligence Research Group, Innovative Communication Laboratory