


| 17 |
声で顔画像の表情を動かすクロスモーダルアクションユニット系列推定と顔画像変換 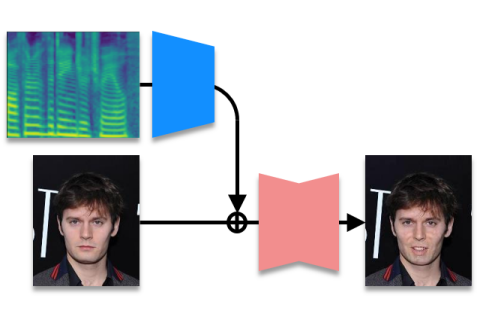
|
|---|
| どんな研究 |
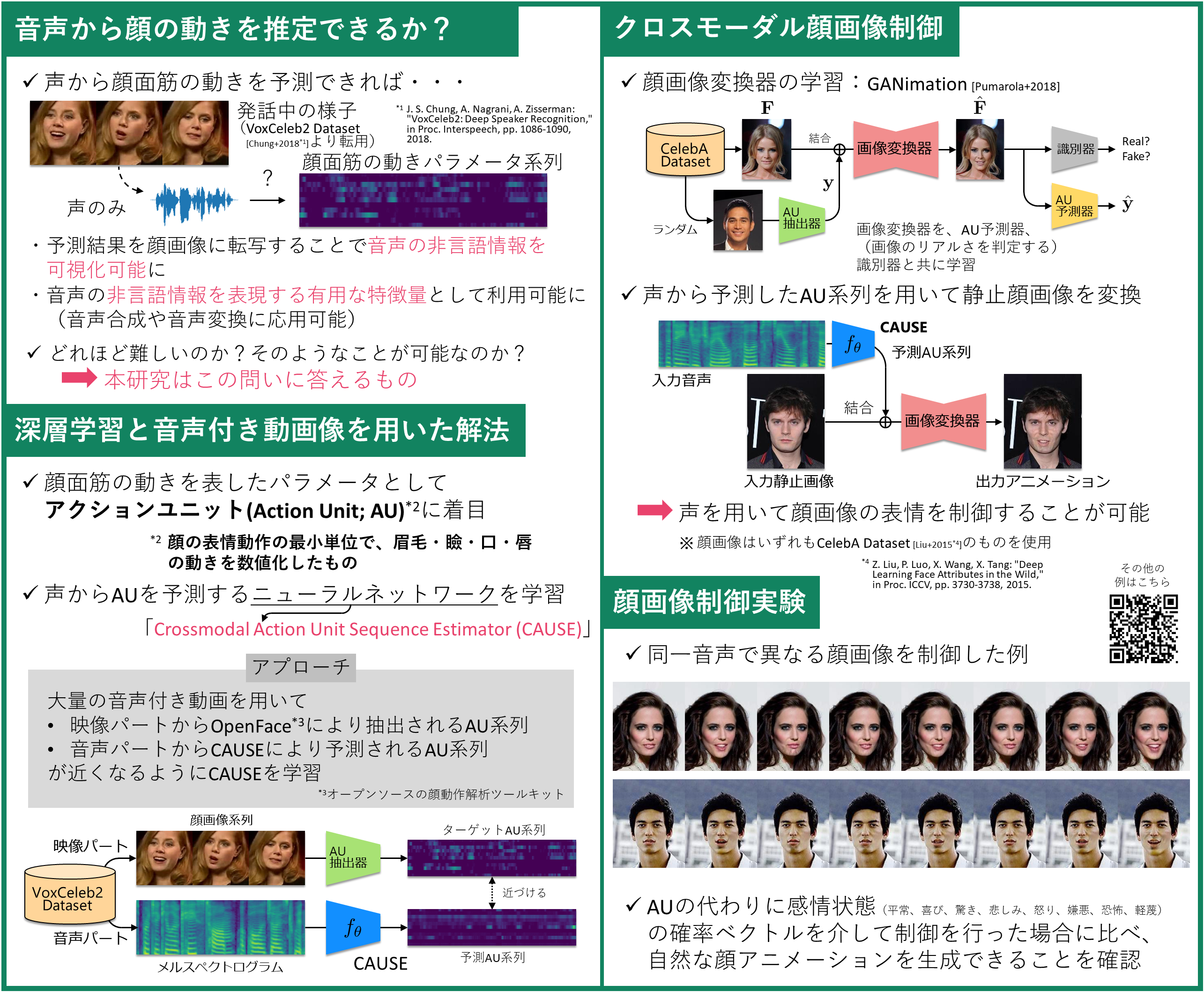
音声には発話内容に相当する言語情報だけでなく、感情表現やムードに相当する非言語情報が含まれ、音声対話において重要な役割を担っています。本研究では、音声の非言語情報は話者の顔表情に表出されていると仮定し、音声のみから話者のアクションユニット(顔面筋パラメータ)を推定することを初めて試みた研究です。 |
|---|---|
| どこが凄い |
これまで音声のみからアクションユニットを推定する試みはなく、どの程度の精度を達成できるかは未知数でしたが、本研究ではこれを初めて明らかにしました。また、音声から推定したアクションユニットと画像変換器を用いることで、声に合わせて静止顔画像の表情を動かすシステムを実装し、声の表情や雰囲気を可視化することを可能にしました。 |
| めざす未来 |
感情表現やムードは、従来、主観に基づく大まかなラベルにより記号的に扱われることが主流でした。これに対し、アクションユニットは感情表現やムードを細やかに表現する連続量として好適であり、本研究で音声からアクションユニットを推定できることを示しました。今後、顔表情に合った音声合成、音声に合った顔画像生成など、音声と顔画像を同時利用した様々な応用技術が拓けると期待しています。 |
[1] H. Kameoka, T. Kaneko, S. Seki, K. Tanaka, “CAUSE: Crossmodal action unit sequence estimation from speech,” submitted to The 23rd Annual Conference of the International Speech Communication Association (Interspeech 2022).

亀岡 弘和(Hirokazu Kameoka) メディア情報研究部 メディア認識研究グループ
Email: cs-openhouse-ml@hco.ntt.co.jp