

| 09 |
Providing a diverse range of appealing voicesAn idol voice dataset for research on speech generation AI 
|
|---|
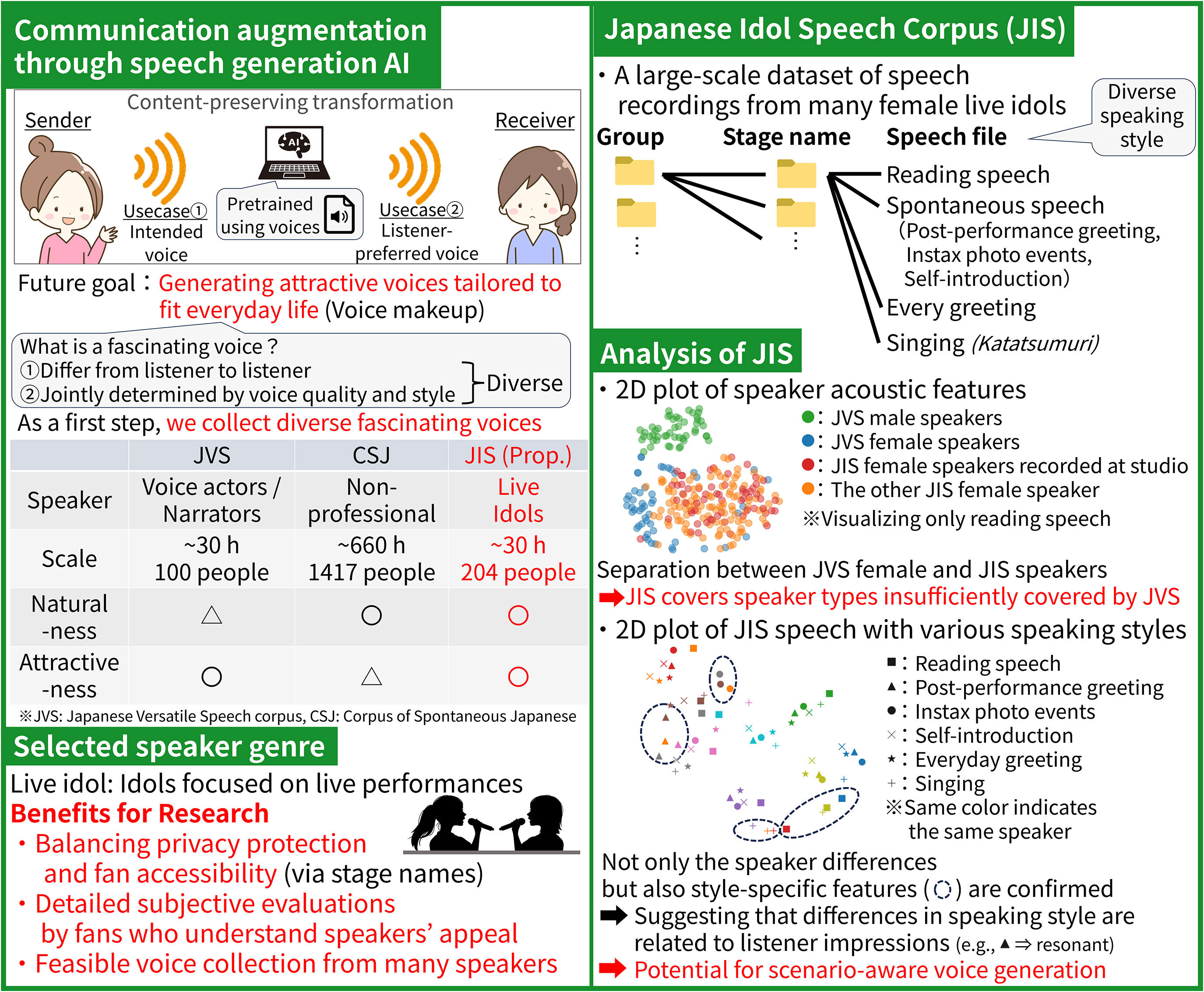
Research data for speech generation AI are often biased toward acted speech produced by professional speakers, such as voice actors. As a first step toward enabling AI systems to generate speech that is personalized to individual users’ preferences and perceived as appealing, we construct the Japanese Idol Speech (JIS) corpus, a multi-speaker speech dataset featuring live idols as speakers with a wide range of vocal characteristics. JIS is the first large-scale idol speech dataset with properly established contractual arrangements for research use, comprising over 200 speakers and approximately 30 hours of audio. In addition to reading speech and everyday conversational utterances commonly found in existing speech datasets, JIS includes distinctive idol-specific speech styles, such as utterances simulating Instax photo session events. By learning from the voices of diverse individuals, we aim to develop an AI system that enables anyone to flexibly and effectively refine their own voice.
[1] Y. Kondo, H. Kameoka, K. Tanaka, T. Kaneko, “JIS: A Speech Corpus of Japanese Idol Speakers with Various Speaking Styles,” in Proc. INTERSPEECH, pp. 4783-4787, 2025.
Yuto Kondo, Computational Modeling Research Group, Media Information Laboratory